
VGGNet 모델은 2014년에 이미지넷 대회에서 준우승을 차지한 모델로(참고로 우승은 GoogLeNet) layer의 개수에따라 VGG16, VGG19로 구분된다.
VGG 모델의 가장 큰 특징은 3x3사이즈의 작은 필터만을 사용해 깊은 층을 구성했다는 점이며,
아래는 tensorflow로 VGG16을 구현한 코드로 코드와 함께 간단한 설명을 적어보았다.
- 라이브러디 가져오기 및 tensorflow 버전확인
##from ____future____ import 모듈이름 : 파이썬3에서 사용하는 문법을 파이썬2에서도 동일하게 사용하기 위함
from __future__ import absolute_import, division, print_function, unicode_literals
import os
import numpy as np
import matplotlib.pyplot as plt
try:
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
keras = tf.keras
print("tensorflow version",tf.__version__)- 파라미터 설정
IMG_SIZE = 244 ## 이미지 사이즈를 244 x 244로 설정
EPOCHS = 3
BATCH_SIZE = 128
learning_rate = 0.0001- 데이터 다운 및 탐색
from keras.datasets import cifar10
from keras.utils import np_utils
import tensorflow_datasets as tfds
## progress bar disable
tfds.disable_progress_bar()
#분류할 클래스 개수
num_classes=10 # Cifar10의 클래스 개수
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cifar10',
split=['train[:90%]', 'train[90%:]', 'test'],
with_info=True,
as_supervised=True,
)
print("Train data 개수:",len(raw_train))
print("Val data 개수:",len(raw_validation))
print("Test data 개수:",len(raw_test))- 이미지셋 전처리
def format_example(image, label):
image = tf.cast(image, tf.float32)
image = (image/127.5) - 1
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label
##map 함수를 사용하여 데이터셋의 각 항목에 데이터 포맷 함수를 적용
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)- 데이터셋 만들기
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)
## train set 개수 / 배치사이즈 = len(train_batches)
45000/ 128 = 352 - VGG16 모델 불러오기
- VGG16 모델을 가져온 후 우리는 클래스 개수가 10개이므로 마지막 분류층을 교체해주는 작업이 필요하다.
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
#CNN 모델 변경하려면 여기서 변경
#ImageNet으로 사전 훈련된 모델 불러오기
base_model = tf.keras.applications.VGG16(input_shape=IMG_SHAPE,
## 분류하는 부분까지 추출
include_top=True,
classes=1000,
## 이미지넷에서 사용한 가중치 적용
weights='imagenet')
model = tf.keras.Sequential()
for layer in base_model.layers[:-1]: # go through until last layer
model.add(layer)
#마지막 layer의 최종 분류 개수를 클래스 개수와 맞게 설정
## 활성함수로는 softmax를 사용
model.add(keras.layers.Dense(num_classes, activation='softmax',name='predictions'))- 모델 summary
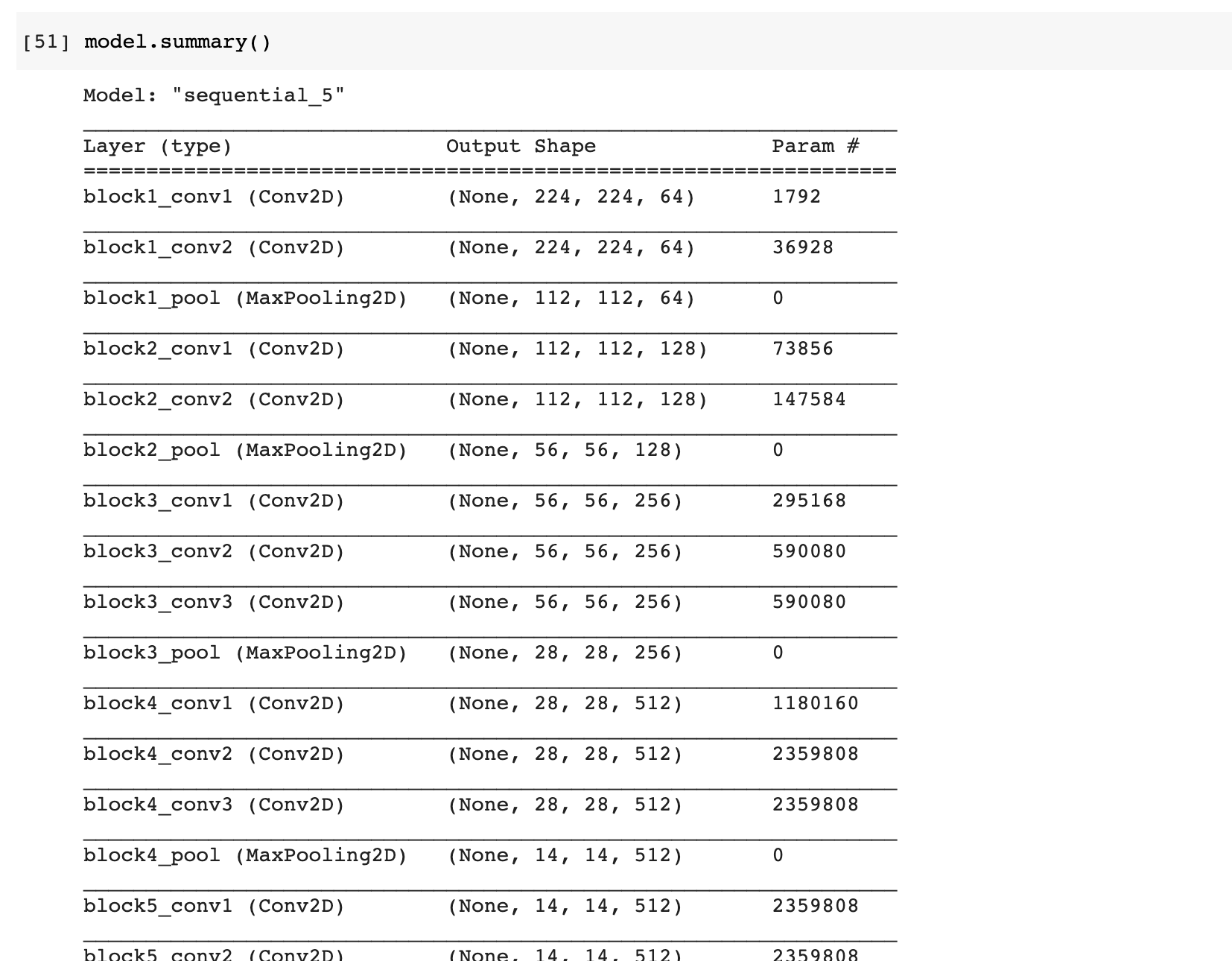
- summary 함수를 이용해 모델의 층, 출력 및 파라미터 정보를 확인할 수 있다.
여기서 말하는 파라미터는 매개변수의 개수를 이야기하는 것으로 다음과 같이 구한다.첫번째 파라미터 1792
1792 = 3(입력채널) x 3x3(필터사이즈) x 64(출력: 필터개수) + 64(바이어스)두번째 파라미터 36928
36928 = 64(입력채널) x 3x3(필터사이즈) x 64(출력: 필터개수) + 64(바이어스)
- 모델 컴파일
- optimzer(가중치 갱신을 위한 함수), 손실함수, 모니터링을위해 metrics를 설정한다.
model.compile(optimizer=tf.keras.optimizers.Adam(lr=learning_rate),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])- 모델 training
model.fit(train_batches,
epochs=EPOCHS,
validation_data=validation_batches,
batch_size=BATCH_SIZE)- test 데이터로 모델 정확도 확인
- evaluate 함수를 이용하면 첫번째 인자로는 전체 loss, 두번째 인자로는 accuracy를 받는다.
loss_and_metrics = model.evaluate(test_batches, batch_size=64)
print("테스트 성능 : {}%".format(round(loss_and_metrics[1]*100,4)))
원하는 대로 살자