
Object Detection 문제는 CNN의 이미지 분류 문제와 유사하지만 거기에 더해 추가로 Localization 정보가 필요하다. Localization는 분류 대상이되는 물체가 이미지에서 1. 존재하는지 여부 2. 어디에 위치하는지 3. 사이즈는 어떻게 되는지 등의 정보를 담고있다.
Object Detection 요소기술
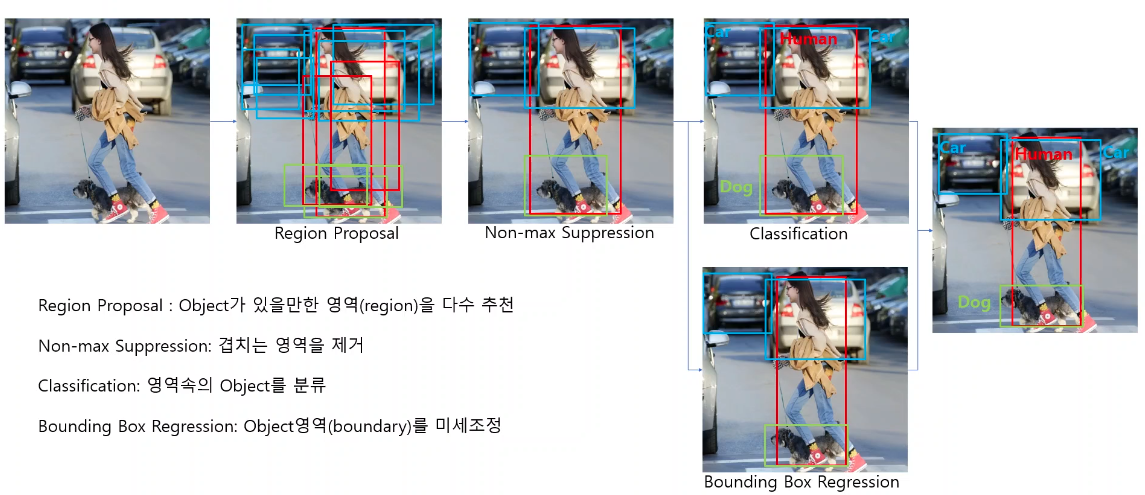
거의 모든 Object Detection에 자주쓰이는 요소기술은 아래와 같다.
- Region Proposal : object가 있을 만한 영역을 다수 추천
- Non-max Suppression : 겹치는 영역을 제거
- Classification : 영역속의 Object를 분류
- Bounding Box Regression : Object영역을 미세조정
용어정리
Bounding Box : 사진에서 object를 detect한 박스를 Bounding Box라고한다.
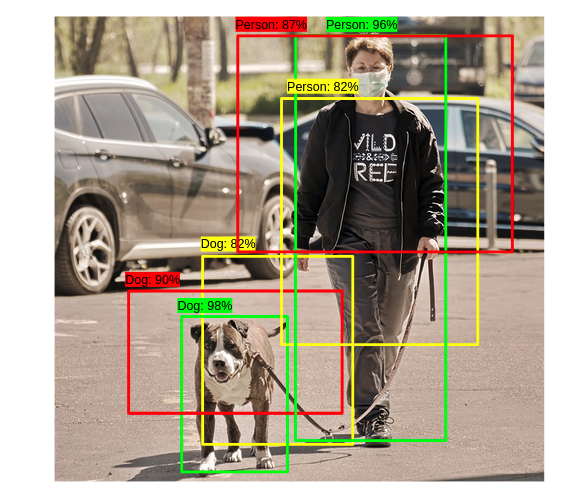
Ground-truth : 녹색 bounding box로 실제 object영역이다. 참고로 빨간색은 예측된 영역이다.
Confidence Score : bounding box의 object 포함여부, 그리고 얼마나 정확하게 object를 포함하고있는지를 반영하는 스코어
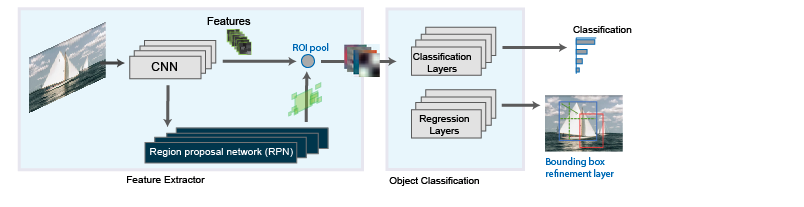
Faster RCNN 구조
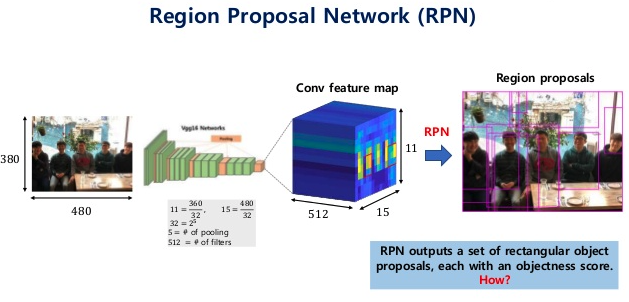
Region Proposal Architecture
- Region Proposal은 각 object마다 detect하기위한 여러개의 bounding box를 발생시키는 것이다. 이러한 bounding box는 아래 그림과 같이 CNN의 feature map에 그려진다.
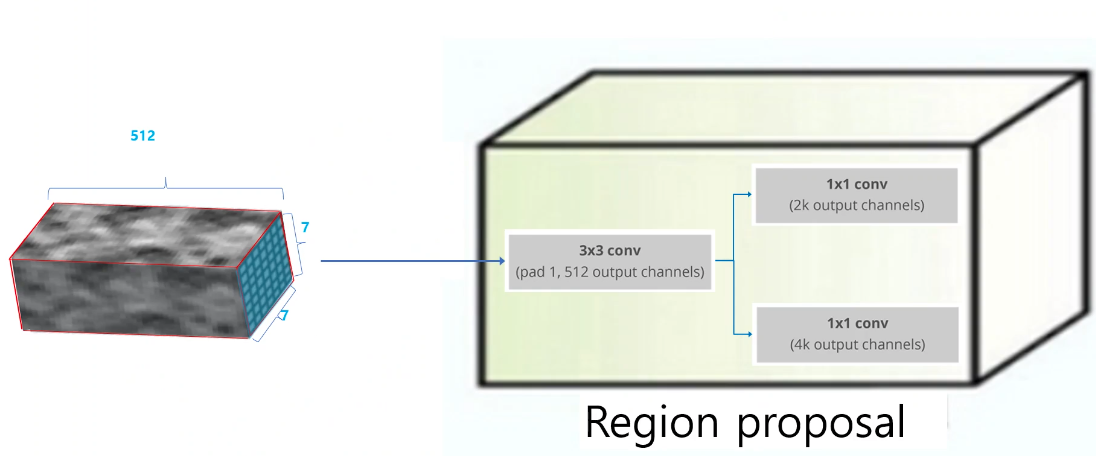
RCNN의 region proposal의 처음에는 3x3 convolution(512ch)이 진행되며 그 후에는 분기되어 채널 사이즈 조절이 가능한(보통 축소) 1x1 convolution이 진행되는데 이로부터 나온 출력은 각각 다른 정보를 같는다. 하나는 object 여부, 나머지는 box의 위치/사이즈 정보를 벡터로 가진다.
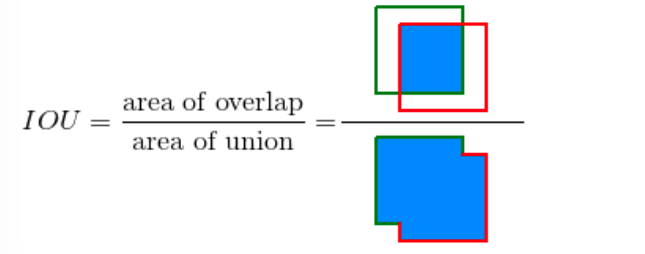
IOU(intersection over union) measure
- object dectection이 잘되고있는지 평가하는 측정도구이다. 그림에서 녹색을 이미지에서 실제 object detect된 부분이라하고 빨간색을 예측된 부분이라고하면 IOU 결과는 그 녹색과 빨간색 box의 교집합 면적을 합집합 면적으로 나눈 것이된다. 따라서 만약 예측이 정확하다면 1에 가까운 값이 될 것이고 아니라면 0 근처의 결과값이 나올 것이다.
실제 학습(training)과정에서는 이러한 IOU Threshold값을 임의로 정해 그 기준값 보다 크면 제대로 object를 detect했다고 볼 수 있다.
Anchor Box
- Anchor Box란?
- 이미지에서 다양한 형태의 object를 detection하기위한 미리 정해진 크기와 비율을 가진 경계박스
- anchor box의 개수와 형태는 사용자가 임의로 정해준다
- Anchor Box를 사용하는 이유?
- 아래사진과 같이 자전거는 3x4의 사이즈인데 하나의 노란색 셀만으로 object가 제대로 detection되었다고 보기어렵다. 따라서 2x3, 3x2, 1x2 ..... 등등등 다양한 anchor box를 적용해 위의 IOU 측정을 통해 object를 판단한다.
- bouding boc regressor 과정해서 box사이즈를 object에 맞게 미세조정해준다. 만약 이미지한장에 자전거(3x4)과 강아지(1x2)가 있다고했을 때 하나의 box(1x1)를 가지고 늘렸다 줄였다하면서 조정해주는 일이 쉬운일이 아니다. 따라서 여러 형태의 anchor box를 이용해 학습한다.

NMS(non-Max Suppression)
region proposal이 object에 여러개의 bounding box를 그리는 과정이라면 non max suppression은 이렇게 겹쳐버린 많은 box중에 가장 confidence가 높은 box만 남기고 나머지는 제거하는 과정으로 다음과 같이 진행된다.
1. 가장 objectness score가 높은 bb를 선택한다. 아래 그림에서는 녹색 box가 될 것이다.
2. IOU 측정을 통해 녹색 box와 어느정도 overlap되는 box들을 모두 삭제한다. 여기서 어느정도라는 것은 사용자가 임의의 IOU threshold는 설정한 후 IOU 연산을 했을 때 이 값보다 높은 box들을 말한다.
3. 위의 절차를 나머지 box에 대해서 반복해서 수행함으로써 겹치는 bounding box들을 제거해나간다.
RoI(region of interest) Pooling
- 하나의 이미지에 여러 물체가 있다면 CNN에서 출력된 feature map에 region proposal이 씌워진 영역은 사이즈가 각 물체마다 다르다. 따라서 사이즈가 다른 각 영역을 정해진 규격의 grid에 맞춰 max pooling을 적용해 동일한 사이즈의 출력을 뱉어내는 과정이다.
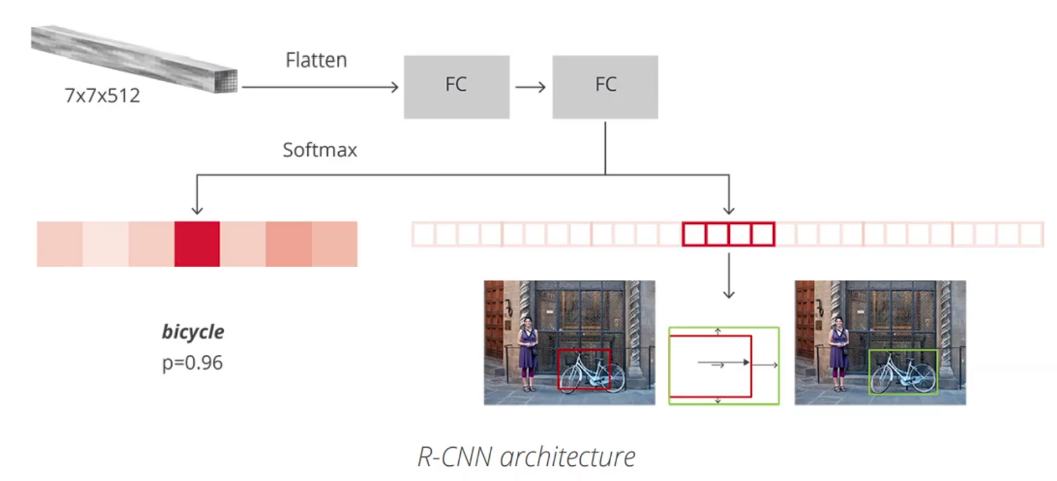
Classifier & Regressor
ROI를 통해 나온 결과는 flatten과 FC layer를거쳐 어떤 객체 class인지를 예측하는classifier 과정과 예측된 bounding box를 object에 맞게 미세조정하는 regressor과정을 최종적으로 진행한다.

아래 그림은 class가 bicycle포함 7개인 예시이고 따라서 오른쪽 벡터가 4x7개의 원소로 표현되었다. 여기서 4는 bounding box의 위치(x,y)와 넓이/높이(w/h)를 의미한다.
이 과정을 수식으로 표현하면 region proposal에 의해 대략적으로 제안된 bounding box가 Pj(k)로 주어졌을 때 실제 box인 B와의 IOU 연산을 통해 가장 근접한(IOU가 가장큰) Bi(k)가 추출된다. (j는 예측된 bounding box의 개수, i는 이미지 속의 object의 개수 또는 실제 bounding box의 개수)
ground-truth classification에서 IOU값이 0.5보다 작을 때 맨앞의 원소가 1인 것은 배경(background)를 의미하는 class이다.

RCNN의 손실함수(cost function)는 아래와 같이 corss-entropy함수를 통해 minimize되는 쪽으로 가중치를 갱신하게된다.

