
YOLO(You Only Look Once)는 objection model로 현재까지 version4까지 개발되었다. 주요 특징으로는 다른 모델들에비해 inference time이 빠른대신 정확도가 조금은 떨어진다는 단점이있다. 이렇게 속도가 강점인 것은 1. RPN과 2. classifier & regressor가 각각의 layer로 존재하던 Two-stage detector의 RCNN과 달리 이 둘이 통합된 One-stage detector이기 때문이다.
YOLO V1
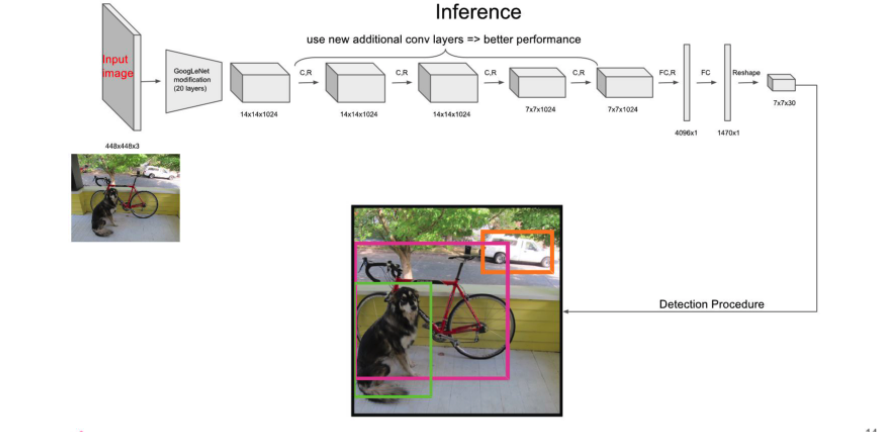
YOLO v1의 구조는 아래와 같고 사전학습, 약간은 수정된 GoogLeNet을 거친후 여러 convolution layer를 통과한다. 최종적으로 FC layer를 통과한 후 7x7x30의 형태로 reshape를 진행한 결과를 통해 detection 과정을 진행한다.
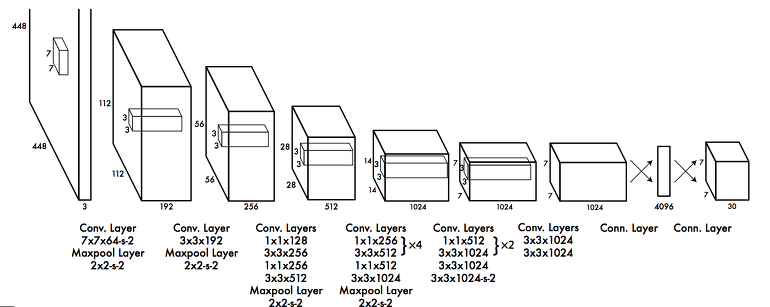
이미지는 7x7개의 cell로 표현되며 각 셀은 길이 30의 벡터로 표현된다.
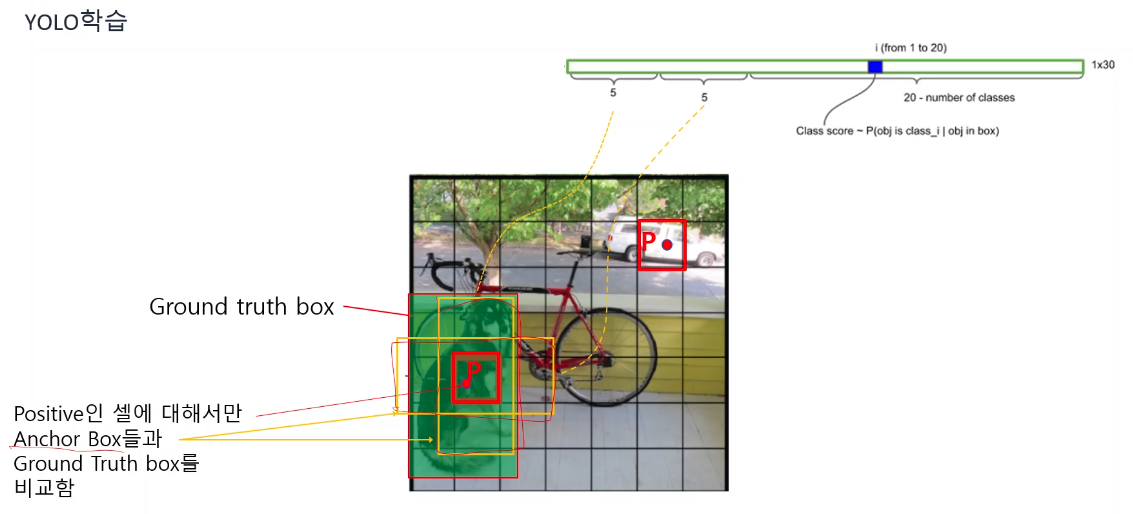
길이 30의 벡터의 앞부분 각 5개는 anchor box를 의미하며 Groung Truth Box와 IOU연산을 통해 더 높은 anchor box의 confidence만을 1로 설정해준다.
또한 Ground Truth Box의 중심점을 잡아 이를 포함하는 cell만 positive를 나머지 cell은 negative를 부여한 후 positive인 셀의 길이 30인 벡터를 아래와 같이 표현한다.
벡터에서 1~5의 정보는 첫번째 anchor box, 6~10의 정보는 두번째 anchor box, 나머지는 해당 셀이 어떤 class인지를 보여주는 conditional class probability를 의미한다.
각 셀별로 아래와 같이 confidence score와 conditional class probability의 곱을통해 노란색 벡터가나온다. 결국에는 셀이 49개이므로 2개의 anchor box에대한 confidence score와 conditional class probability의 곱인 벡터는 2x49 = 98개가 나오게 된다.
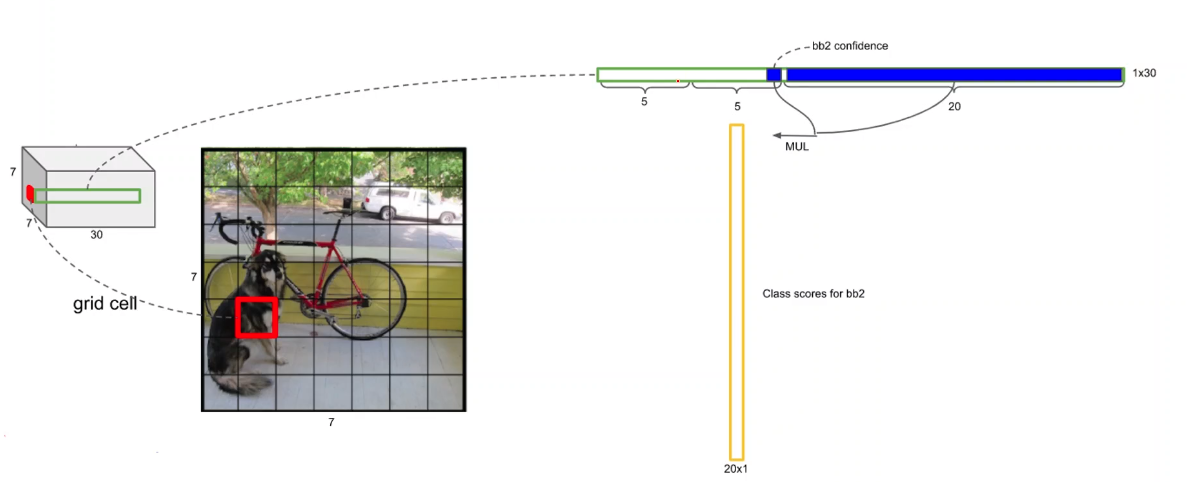
98개의 각 벡터는 class의 개수에 해당하는 길이 20을 가진다. 따라서 각 class 별로 non maximum supresstion를 진행하는 작업을 거친다.
YOLO 버전별 비교
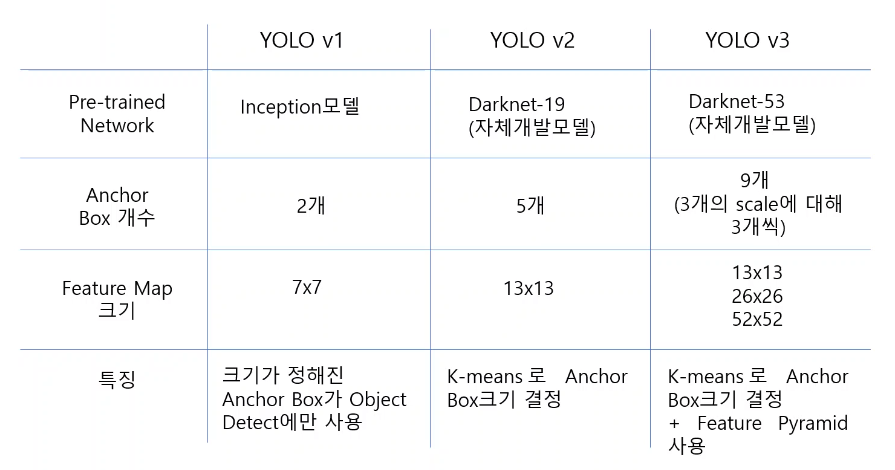
K-means Anchor Box크기 결정(v2, v3)
version2 부터는 anchor box의 결정에 K-menans 방법을 사용한다. 아래의 그림은 데이터 셋에서 ground-truth bounding box를 추출한 후 5개로 크기를 분류하였다. 그리고 분류된 영역을 대표하는 box를 하나씩 뽑아 anchor box로 사용한다.
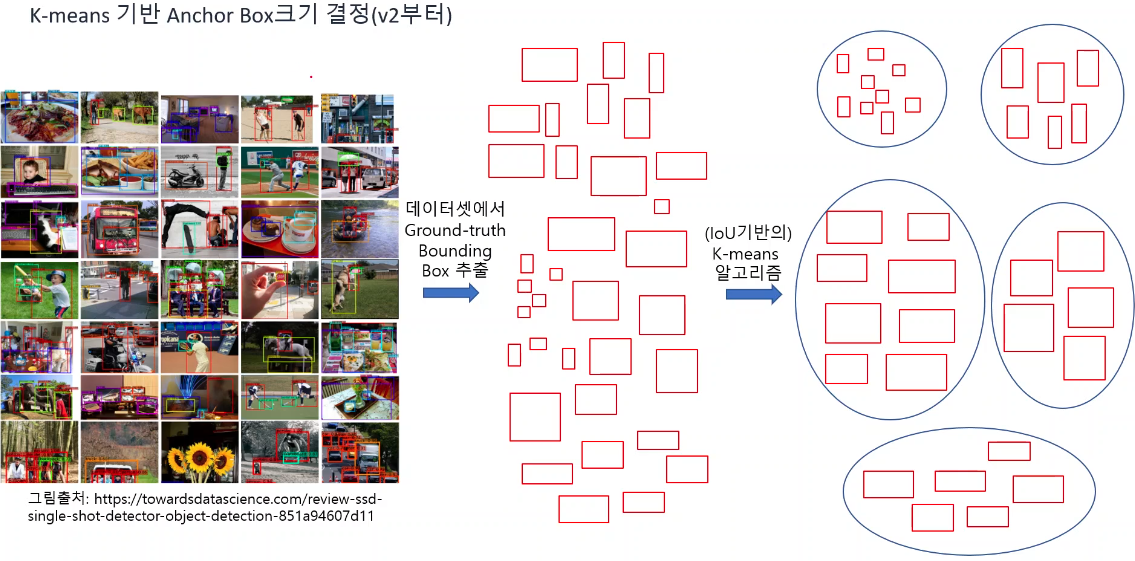
Feature Pyramid(v3)
어떤 이미지가 주어졌을 때 anchor box 사이즈가 특정영역을 잘 커버하지 못하는 경우를 극복하기위해 영상의 사이즈를 줄이거나 늘려 동일한 anchor box에 대해 특징영역을 detect한다.
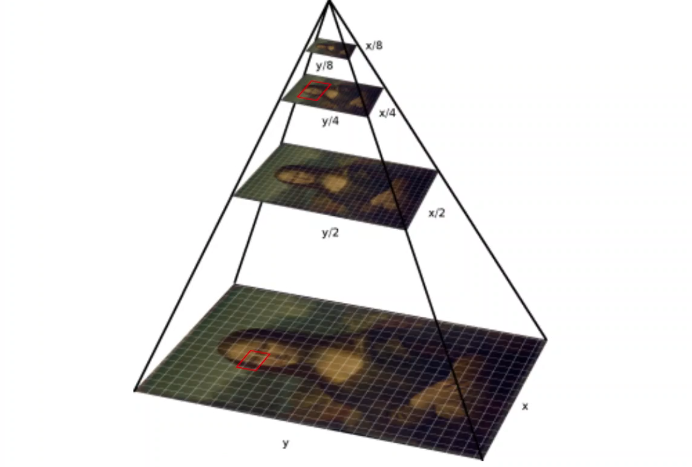
YOLO v3 structure
아래 구조에서 진행과정을 보면 이미지를 줄이거나 늘리는 부분이 있다. 특히 줄이는 과정에서 정보가 손실될 수 있으며 이미 한번 줄어든 이미지는 후에 늘리는 과정을 통해서도 손실되 정보를 회복할 수 없다. 따라서 이 때 필요한 것이 residual block으로 사이즈를 변경하기 전의 정보를 더해줌으로써 손실된 정보를 보완할 수 있다.
참고
