교차 엔트로피(Cross Entropy)
두 확률 분포(P와 Q라고 가정)가 얼마만큼의 정보를 공유하고있는지 유사도의 척도이다.
아래와 같은 수식으로 표현되며 머신러닝에서 교차엔트로피는 손실함수로 사용 된다. 예를들어 P를 입력데이터의 분포, Q를 예측데이터의 분포라고했을 때 입력분포는 우리가 조정할 수 없는부분이지만 예측분포 Q는 우리가 어떻게 예측하느냐에따라 달라지는 부분으로 손실함수는 Q에의해서 조정가능하다.
만약 이렇게 교차엔트로피를 손실함수로 사용하는 경우 아래의 빨간색 박스부분을 KL발산이라고하며 우리의 목적은 이 부분을 최소로하는 것이 된다.
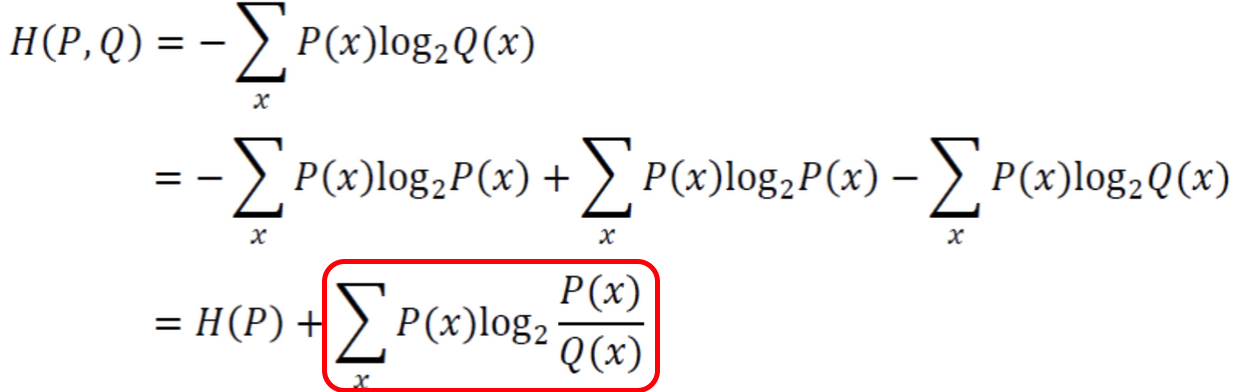
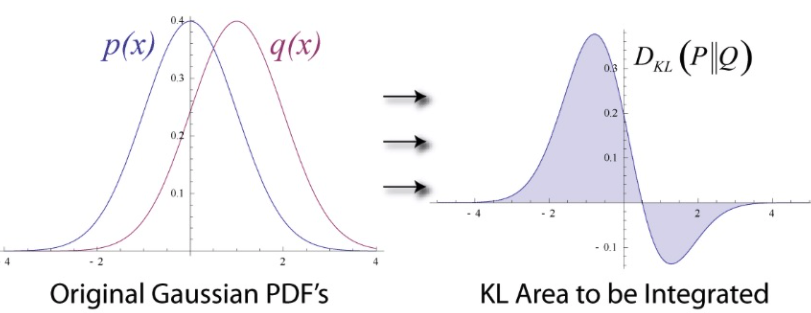
아래의 오른쪽 그래프가 p와 q 확률분포의 차이가되며 두 확률분포가 비슷할수록 그래프의 면적은 0에 가깝게된다.
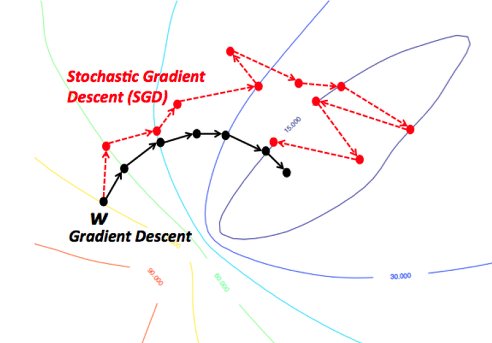
경사하강 알고리즘
손실함수를 최소로하는 지점을 찾기위해 경사하강 알고리즘으르 주로 사용한다.
경사하강 알고리즘의 기본적인 원리는 미분을 이용해 기울기와 이동거리를 조절하는 learning rate를 통해 손실함수가 최소가되는 지점을 향하여 점진적으로 이동하는 것이다. 이 경사하강 알고리즘을 사용할 때 학습데이터 전체를 통해 갱신하는 경우 학습을 여러번 진행하게되면(epoch가 크면) 그 과정이 오래걸리는 단점이있기 때문에 학습데이터를 나누어(mini-batch의 단위) 부분 데이터로 경사도를 계산한 후 즉시 갱신하는 방법을 사용한다.
이러한 방법을 전체 데이터에서 샘플을 취해 경사를 구한다고해서 확률론적 경사하강(Stochastic gradient descent) 알고리즘이라고한다. 확률론적 경사하강법은 샘플데이터를 1개(배치의 크기가 1)취해서 갱신하는 방법과 위에서 말한 것처럼 전체데이터를 미니배치의 단위(일반적으로 10~1000개사이 샘플)로 갱신하는 방법이 사용된다. 보통 머신러닝을 학습할 때 gpu를 사용하기 때문에 병렬처리의 이점을 살릴 수 있고 경사도의 잡음도 상대적으로 적은 미니배치단위의 확률론적 경사하강법을 주로 사용한다.
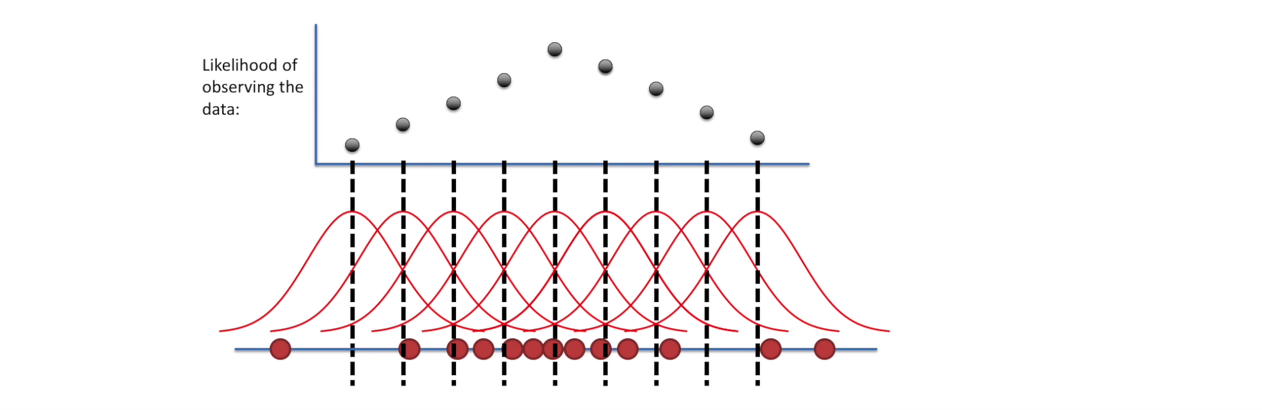
확률(probability)과 우도(likelihood)
확률
- 어떤 분포로부터 관측된 값이 나올 확률 만약 연속사건이라면 특정 구간에 속할 확률을 의미한다.
우도
- 관찰 데이터로부터 특정 사건이 일어날 확률분포를 유추하는 것을 의미한다.
최대우도추정(Maximum liklihood estimator)
- 확률변수의 관찰된 값들을 토대로 그 확률변수의 매개변수를 구하는 방법, 또는 일어날 가능성이 가장 높은 확률분포를 찾는 것을 말한다.
즉 아래의 그림에서 빨간색 공들이 관찰데이터라고 했을 때 검은색으로 표현된 결과가 가장 높은지점(우도가 가장 높은)이 관찰데이터가 나올수 있는 가장 높은 확률의 분포라고 보는 것이 최대우도추정이다.