
그동안 인공지능에대해 학습하면서 정작 그 정의에 대에서는 집고넘어가지않은 것 같아서 간단히 정리해보았다.
인공지능(Artificial Intelligence)
- 인간처럼 추론, 사고, 이해하는 능력을 실현한 기술
머신러닝(Machine Learning)
- 위의 인공지능의 주체가 컴퓨터가되어 경험(데이터)을 학습을 통해 규칙을 찾고 새로운 경험(데이터)에 대해서 더 잘 예측하는 것
딥러닝(Deep Learning)
- 다수의 layer를 가진 신경망을 이용해 최적의 계층적인 특징을 학습하는 방법으로 심플하고 세분화된 특징을 고도화, 추상화된 특징으로 표현한다.
표현학습(Representation Learning)
- 특징, 규칙을 사람의 도움없이 스스로 찾는 학습방법, 원래 공간을 변형해서 보다 심플한 규칙을 찾는다. 딥러닝은 표현학습 중 하나이다.
매니폴드(Manifold)
- 아래의 롤처럼 생긴 공간을 생각했을 때 우리가 보기에는 곡선인 비유클리디안 모양이지만 아주 작은 부분만 취해서 미소적 관점으로 본다면 직선의 유클리디안 공간이된다. 마치 지구가 실제로는 구이지만 우리는 지구에비해 매우 작기 때문에 평평하다고 느끼는 것과 같다.
이러한 개념이 바로 매니폴드이다. 뭔가 정의가 딱 떨어지는 느낌은 아닌데 아무튼 이러한 관점을통해 고차원의 데이터를 아우르는 저차원인 유클리디안 부분 공간을 찾는 것을 매니폴드 학습이라고한다. 즉 아래그림에서는 고차원인 곡선의 특정부분의 데이터를 저차원으로 투영했을 때 투영된 유클리디안 공간에서도 그 데이터가 유사하게 설명이된다. 그러므로써 데이터를 좀더 심플하게 시각화하고 차원의 저주를 개선할 수 있다.
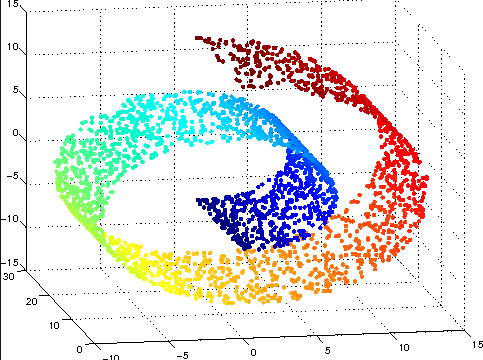
적은양의 데이터에도 불구하고 차원의 저주를 피하는 경우
- 차원의 저주는 차원이 늘어나면 데이터 수가 상대적으로 공간에비해 작아져 모델의 성능이 저하되는 것을 말한다. 이 이론에 따르면 데이터는 차원이 증가함에따라 지수적으로 증가해주어야 모델의 성능이 잘 유지된다.
하지만 예외적인 경우가 있는데 대표적인 케이스가 MNIST(손글씨 숫자데이터)이다. MNIST데이터의 경우 2^784의 차원에도 불구하고 60000개정도의 학습데이터를 잘 분류한다. 이 것은 아래와 같은 세가지 이유 때문이다.
- 2^784차원의 방대한 공간에서 실제로 특정 숫자가 발현되는 부분은 매우 작은 부분(아래 그림의 빨간색 내부)이며 각 숫자별로(만약 3이 100개있다고 하면 모두 비슷한 위치에서 발현될 것)발현되는 위치가 비슷비슷하기 때문에 이런경우에는 차원의 저주가 해당하지 않는다.

- 데이터 자체가 숫자가 아니거나 숫자임에도 형체를 알 수 없는 이상한 데이터가 학습되는 경우는 거의 없다.
- 위에서 설명한 매니폴드 관점에서 각 숫자데이터는 내제되어있는 규칙을 가지고있기 때문에 고차원에서의 규칙이 저차원에서 유사하게 보존된다. 그렇기 때문에 상대적으로 적은양의 학습데이터에도 불구하고 저차원으로 투영했을 때 고차원에서의 규칙을 유사하게 가지고 감으로써 잘 분류할 수 있다.
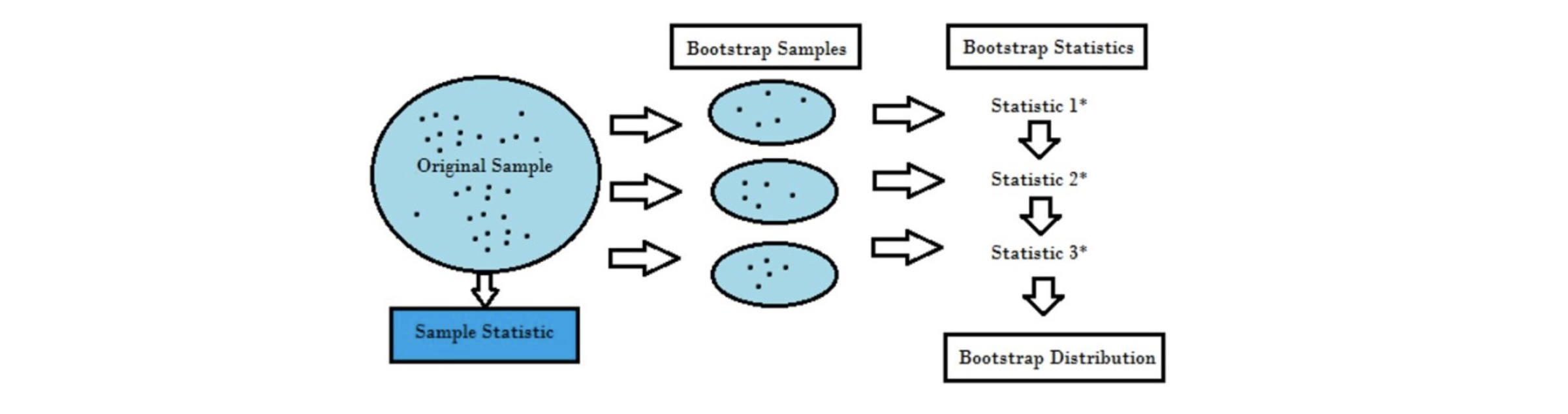
부트스트랩(Bootstrap)
-
임의(random)의 복원 추출 샘플링의 반복으로 학습데이터가 작을 때 또는 데이터 분포가 불균형일 때 사용한다. 샘플링할 때 중복이 가능하므로 학습데이터를 늘릴 수 있다는 것은 직관적으로 이해가 가능한 부분이다. 마치 확률통계에서 특정 크기이상의 표본을 무수히 뽑았을 때 그 분포는 모집단을 잘 설명할 수 있기 때문에 표본을 엄청나게 반복적으로 샘플링해도 기존 학습데이터와 비슷하기 때문에 문제가 안될 것이라는 생각이든다.
-
그렇다면 데이터 분포가 불균형일 때는 이를 부트스트랩 방법을 이용해 어떻게 해결가능하다는 것일까? 이른바 오버샘플링(Oversampling)과 언더샘플링(Undersampling) 방법을 통해서이다. 오버샘플링은 불균형 데이터 셋에서 낮은 비율의 데이터 수를 늘리는 것이고 언더샘플링은 반대로 큰 비율의 데이터수를 줄이는 방법으로 아래의 그림을 보면 쉽게 이해가될 것이다.
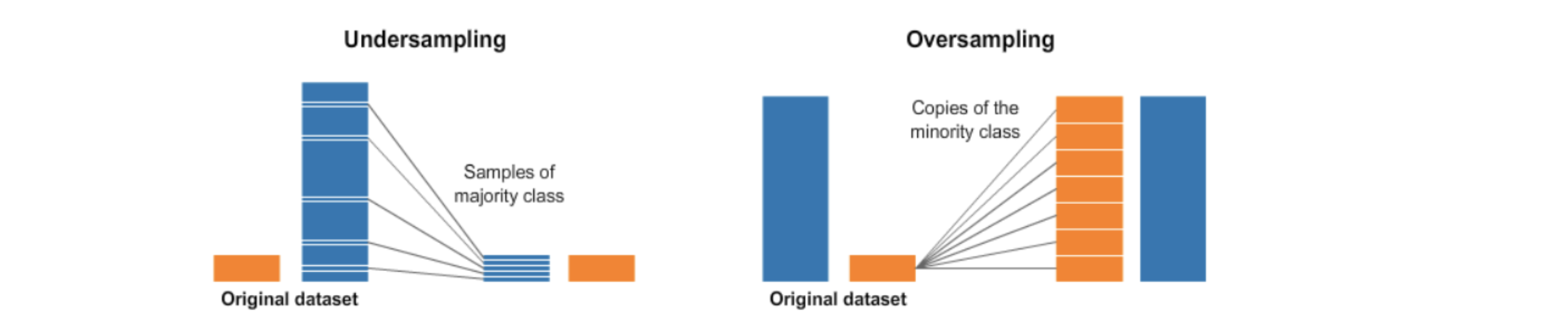
Data Augmentation
- Data Augmentation은 데이터의 다양성을 확보하기위한 전략으로 특히 이미지 데이터에서 원본데이터를 약간의 rotation, shift 그리고 crop 등의 작업을 해줌으로써 새로운 데이터의 수집없이도 학습데이터를 늘려줄 수있다.

참고

원하는 대로 살자