이번 학습 키워드는
🥕 순차 데이터
🥕 순환 신경망
입니다.
1. 순차 데이터
순차 데이터
- 텍스트나 시계열 데이터와 같이 순서에 의미가 있는 데이터
시계열 데이터
- 일정한 시간 간격으로 기록된 데이터
지금까지 다뤘던 패션 MNIST 데이터나 생선 데이터는 신경망 모델에 전달할 때 샘플을 랜덤하게 섞은 후 훈련 세트와 검증 세트로 나눴습니다. 즉, 샘플의 순서는 학습에 영향을 주지 않았습니다.
하지만 텍스트 데이터와 같은 순차 데이터는 순서를 유지하며 신경망에 주입해야합니다. 따라서 이전에 입력한 데이터를 기억하는 기능이 필요합니다.
피드포워드 신경망(feedforwrd neural network)
- 완전 연결망이나 합성곱 신경망과 같이 입력 데이터의 흐름이 앞으로만 전달되는 신경망
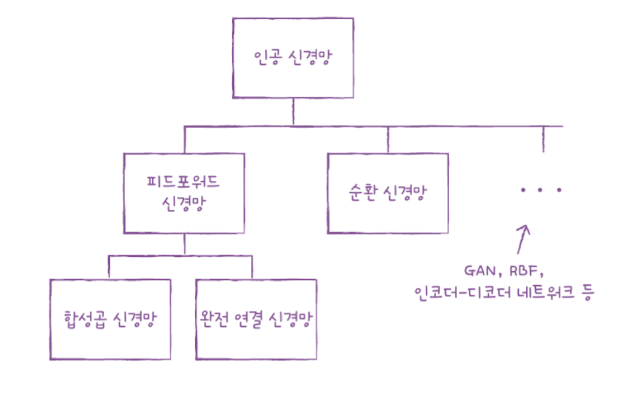
2. 순환 신경망
순환 신경망(RNN: Recurrent Neural Network)
- 순차 데이터에 잘 맞는 인공 신경망의 한 종류
- 순차 데이터를 처리하기 위해 고안된 순환층을 1개 이상 사용한 신경망
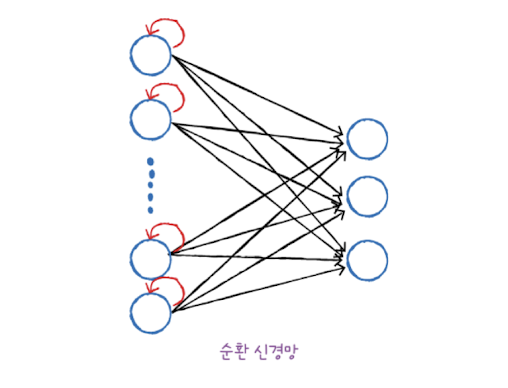
완전 연결 신경망에 이전 데이터의 처리 흐름을 순환하는 고리 하나를 추가하면 순환 신경망이됩니다. 즉 어떤 샘플을 처리할 때 바로 이전에 사용했던 데이터를 재사용합니다.
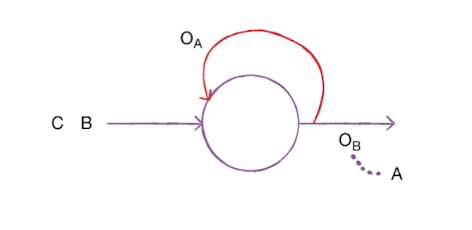
예를들어 A라는 샘플을 처리한 난 출력을 라고하면, 그 다음 순서인 샘플 B를 처리할 때 를 함께 사용합니다.
이렇게 샘플을 처리하는 한 단계를 타임스텝이라고 합니다. 순환 신경망은 이전 타임스텝의 샘플을 기억하지만 타임스텝이 오래될수록 순환되는 정보는 희미해집니다.
타임스텝(time step)
- 순환 신경망에서 샘플을 처리하는 한 단계
셀(cell)
- 순환 신경망의 층
- 은닉상태(hidden state): 셀의 출력
일반적으로 은닉층의 활성화 함수로는 하이퍼볼릭 탄젠트 함수인 tanh 함수가 많이 사용됩니다.
tanh 함수
- 활성화 함수의 종류 중 하나로 은닉층에 많이 사용됨
- -1~1 사이의 범위를 가짐
합성곱 신경망과 같은 피드포워드 신경망에서 뉴런은 입력과 가중치를 곱합니다. 순환 신경망에서의 뉴런은 가중치가 하나 더 있습니다. 바로 이전 타임스텝의 은닉 상태에 곱해지는 가중치입니다.
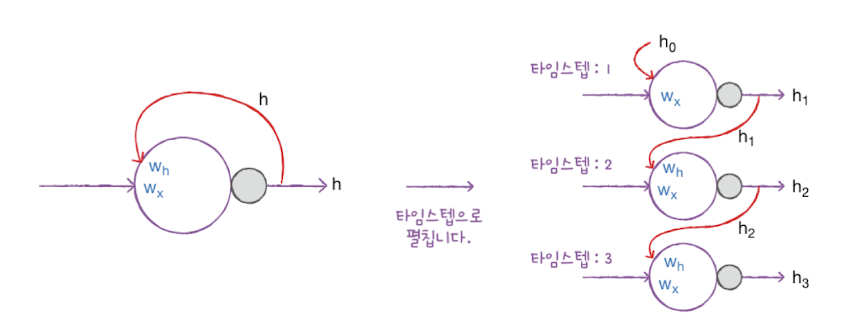
위 그림에서 는 입력에 곱해지는 가중치이고 는 이전 타임스텝의 은닉 상태에 곱해지는 가중치입니다. 셀의 출력(은닉 상태)이 다음 타임스텝에 재사용되기 때문에 타임스텝으로 셀을 나누어 그릴 수 있습니다.
오른쪽 그림과 같이 순환 신경망을 타임스텝마다 그리는 것을 타임스텝으로 펼쳤다고 말합니다.
가장 첫번째 타임스텝에서 사용되는 이전 은닉 상태 은 모두 0으로 초기화합니다.
3. 셀의 가중치과 입출력
셀의 가중치
순환 신경망의 셀에서 필요한 가중치 크기를 계산해보겠습니다.
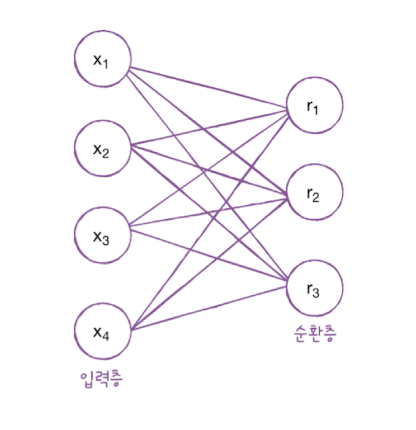
위 그림에서 순환층에 입력되는 특성의 개수는 4개, 뉴런의 개수는 3개입니다.
입력층과 순환층의 뉴런이 모두 완전 연결되기 때문에 가중치의 크기는 4 x 3 = 12 입니다.
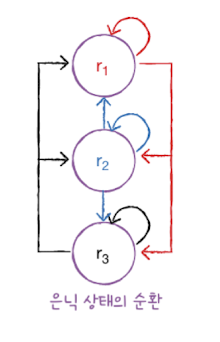
순환층에서 다음 타임스텝에 재사용되는 은닉 상태를 위한 가중치의 크기는 3 x 3 = 9 입니다.
모델 파라미터의 개수는 가중치에 절편을 더한 값이므로 12 + 9 + 3 = 24개입니다.
모델 파라미터 수 = + + 절편
