학습 목표 :
📌 텐서플로를 사용해 순환 신경망을 만들기
📌 영화 리뷰 데이터셋에 적용하여 리뷰 긍부정 분류하기
이번 챕터에서는 순환 신경망을 사용해서 IMDB 리뷰 데이터셋을 훈련해보겠습니다. 데이터셋은 1) 원-핫 인코딩 2) 단어 임베딩 의 두 가지 방법으로 변형하여 입력하겠습니다.
1. IMDB 리뷰 데이터셋
IMDB 데이터
- 영화 데이터베이스인 imdb.com에서 수집한 리뷰를 긍정과 부정으로 분류한 데이터셋
자연어 처리(NLP: Natural Language Processing)
- 컴퓨터를 사용해 인간의 언어를 처리하는 분야
음성인식, 기계 번역, 감성 분석 등이 있음- 말뭉치(corpus): 자연어 처리 분야의 훈련 데이터
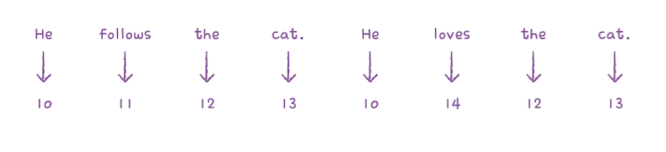
텍스트 데이터를 신경망에 전달할 때는 숫자 형태로 변환하여 입력합니다.
일반적으로 영어 문장은 모두 소문자로 바꾸고 구둣점을 삭제한 다음 공백을 기준으로 분리합니다.
토큰(token)
- 영어 말뭉치에서 단어를 의미
- 하나의 샘플은 여러 개의 토큰으로 구성
- 1개의 토큰은 하나의 타임스텝에 해당
한글의 경우 형태로 분석을 통해 토큰 생성
IMDB 리뷰 데이터셋은 영어 문장을 정수로 바꾼데이터셋이 있습니다. 해당 데이터셋을 임포트해서 500개까지만 적재해보겠습니다.
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(
num_words=200)
print(train_input.shape, test_input.shape)(25000,) (25000,)
훈련 세트와 테스트 세트가 각각 25,000개의 샘플로 이루어져 있습니다. 배열이 1차원인데요, 개별 리뷰를 담은 파이썬 리스트 객체로 이루어진 넘파이 배열이기 때문입니다.
print(len(train_input[0]))218
print(len(train_input[1]))189
첫 번째 리뷰의 길이는 218개의 토큰으로 이루어져 있고 두 번째 리뷰의 길이는 189개 입니다. 리뷰마다 각각 길이가 다르다는 것을 알 수 있습니다.
print(train_input[0])[1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 2, 2, 66, 2, 4, 173, 36, 2, 5, 25, 100, 43, 2, 112, 50, 2, 2, 9, 35, 2, 2, 5, 150, 4, 172, 112, 167, 2, 2, 2, 39, 4, 172, 2, 2, 17, 2, 38, 13, 2, 4, 192, 50, 16, 6, 147, 2, 19, 14, 22, 4, 2, 2, 2, 4, 22, 71, 87, 12, 16, 43, 2, 38, 76, 15, 13, 2, 4, 22, 17, 2, 17, 12, 16, 2, 18, 2, 5, 62, 2, 12, 8, 2, 8, 106, 5, 4, 2, 2, 16, 2, 66, 2, 33, 4, 130, 12, 16, 38, 2, 5, 25, 124, 51, 36, 135, 48, 25, 2, 33, 6, 22, 12, 2, 28, 77, 52, 5, 14, 2, 16, 82, 2, 8, 4, 107, 117, 2, 15, 2, 4, 2, 7, 2, 5, 2, 36, 71, 43, 2, 2, 26, 2, 2, 46, 7, 4, 2, 2, 13, 104, 88, 4, 2, 15, 2, 98, 32, 2, 56, 26, 141, 6, 194, 2, 18, 4, 2, 22, 21, 134, 2, 26, 2, 5, 144, 30, 2, 18, 51, 36, 28, 2, 92, 25, 104, 4, 2, 65, 16, 38, 2, 88, 12, 16, 2, 5, 16, 2, 113, 103, 32, 15, 16, 2, 19, 178, 32]
첫 번째 리뷰에 담긴 내용을 출력했습니다. 정수로 변환된 리뷰를 확인할 수 있습니다.
print(train_target[:20])[1 0 0 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 1]
타깃 데이터는 리뷰가 긍정인지 부정인지를 판단하는 이진분류 문제를 표현하며 0은 부정, 1은 긍정을 의미합니다.
from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)80:20의 비율로 훈련 세트와 검증 세트를 분리하였습니다.
이번에는 리뷰 데이터의 평균적인 길이 등의 정보를 확인해보겠습니다.
import numpy as np
lengths = np.array([len(x) for x in train_input])
print(np.mean(lengths), np.median(lengths))239.00925 178.0
리뷰의 평균 단어 개수는 239개이고, 중간값은 178입니다.
import matplotlib.pyplot as plt
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()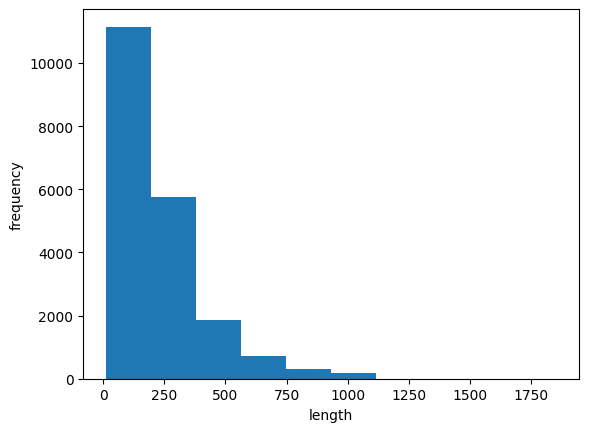
히스토그램으로 그려보니 리뷰 길이 데이터가 대부분 300 미만으로 치우친 걸 확인할 수 있습니다.
리뷰가 대부분 짧기 때문에 중간값보다 훨씬 짧은 100개의 단어만 사용하겠습니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)
print(train_seq.shape)(20000, 100)
pad_sequences( ) 함수를 사용해서 train_input 의 길이를 100으로 맞추었습니다. 길이가 100보다 짧은 경우는 0으로 패딩합니다.
train_input은 파이썬 리스트의 배열이었지만 변환을 거친 train_seq는 (20000, 100) 크기의 2차원 배열입니다.
val_seq = pad_sequences(val_input, maxlen=100)검증 데이터셋도 길이를 100으로 맞춰줍니다.
2. 순환 신경망 만들기
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 200)))
model.add(keras.layers.Dense(1, activation='sigmoid'))케라스의 SimpleRNN 클래스를 사용해서 순환 신경망을 구성했습니다.
순환층
- 첫 번째 매개변수는 사용할 뉴런의 개수로 (100, 500)을 입력차원으로 지정
- 활성화 함수: 기본값인 tanh 하이퍼볼릭 탄젠트 함수를 그대로 사용
- inputshape
- 100은 샘플의 길이인 100으로 지정
- 500은 imdb.load_data( )에서 500개의 단어만 사용하도록 지정했기 때문
원-핫 인코딩
- 정수값을 배열에서 해당 정수 위치의 원소만 1이고 나머지는 모두 0으로 변환
train_seq와 val_seq는 토큰을 정수로 변환한 형태인데 그대로 신경망에 주입하면 큰 정수가 큰 활성화 출력을 만든다는 문제가 생깁니다. 이를 해결하기 위해 원-핫 인코딩을 사용합니다.
train_oh = keras.utils.to_categorical(train_seq)
print(train_oh.shape)(20000, 100, 200)
to_categorial( )
- 정수 배열을 입력하면 원-핫 인코딩된 배열 반환
print(train_oh[0][0][:12])[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
위와 같이 원-핫 인코딩 변환이 잘 되었습니다.
val_oh = keras.utils.to_categorical(val_seq)검증세트도 같은 방식으로 원-핫 인코딩 해줍니다.
3. 순환 신경망 훈련하기
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.keras',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model.fit(train_oh, train_target, epochs=100, batch_size=64,
validation_data=(val_oh, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])모델을 컴파일하고 훈련을 시작합니다. 훈련된 모델의 훈련 손실과 검증 손실을 그래프로 그려서 훈련 과정을 확인해보겠습니다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()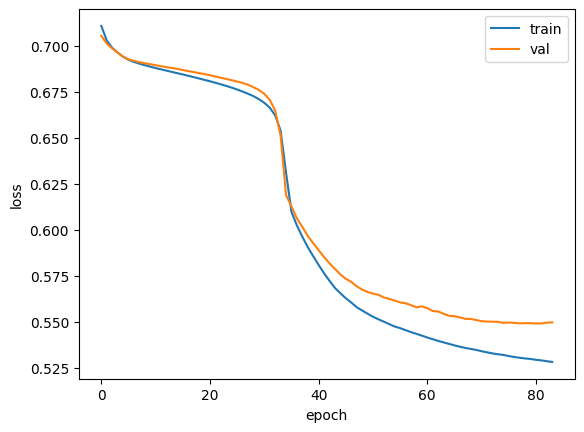
그런데 원-핫 인코딩을 사용할 경우 입력 데이터의 크기가 커진다는 단점이 있습니다. 토큰 1개를 500차원으로 늘렸기 때문에 약 500배가 커집니다.
4. 단어 임베딩 사용하기
단어 임베딩(word embedding)
- 각 단어를 고정된 크기의 실수 벡터로 변환
- 순환 신경망에서 텍스트를 처리할 때 주로 사용하는 방법으로 입력으로 정수 데이터를 받아 메모리를 효율적으로 사용
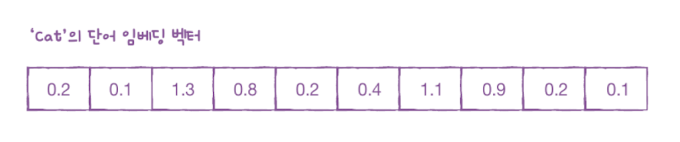
단어 임베딩으로 만들어진 벡터는 원-핫 인코딩 벡터보다 훨씬 의미있는 값으로 채워져 있기 때문에 자연어 처리에서 더 좋은 성능을 내는 경우가 많습니다.
케라스의 Embeddign 클래스로 임베딩 기능을 제공합니다.
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(200, 16, input_shape=(100,)))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))Embedding 클래스
- 첫 번째 매개변수 500: 어휘 사전의 크기인 단어 500개
- 두 번째 매개변수 16: 임베딩 벡터의 크기 16으로 지정
- input_length: 입력 시퀀스 길이, 샘플의 길이를 100으로 맞춤
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-embedding-model.keras',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()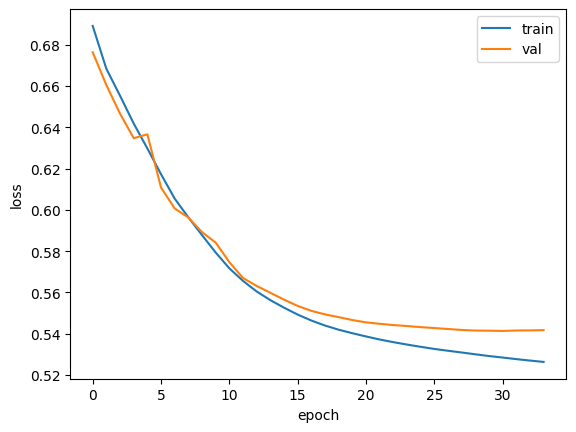
모델을 훈련하고 훈련 과정을 그래프로 그렸습니다.
