
1. 객체 탐지에 사용되는 딥러닝 모델
조원들은 일주일 동안 객체 탐지 알고리즘에 관련해서 서치하고 중간중간 자신이 얻은 정보들을 공유하며 알고리즘을 학습했다.
아래는 일주일 간 학습하여 회의 동안 내용을 함께 공유하며 정리한 내용이다.
객체 탐지는 컴퓨터 비전의 중요한 개념으로 임의의 이미지 속에서 우리가 원하는 객체를 배경 이미지와 구분, 식별하는 자동화 기법이다.
Bounding Box를 설정해 이미지 속 객체를 나타내고 해당 박스 안의 객체를 소속된 클래스로 분류한다.
경계박스는 IoU(Intersection over Union)을 사용한 NMS(Non Maximum Suppression) 방식으로 객체 당 하나의 경계 박스로 만들어야 한다.
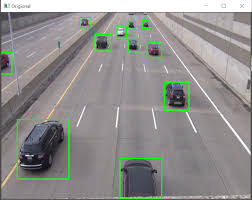
앞선 포스트에서 각 알고리즘에 대해서 설명했기 때문에 간단하게 요약한다.
1-1 이단계 방식의 객체 탐지 알고리즘
이단계 알고리즘은 Region Proposal을 수행한다.
이 중에는 객체를 포함할 확률이 높은 영역을 선택적으로 탐색하거나 RPN(Region Proposal Network)를 이용하여 영역을 선택하는 방식이 있다.
R-CNN, Fast R-CNN, Faster R-CNN등이 해당 알고리즘의 예시이다.
1-2 단일 단계 방식의 객체 탐지 알고리즘
단일 단계 방식은 정해진 위치와 크기의 객체만 찾는 방식이다.
이미지를 고정된 사이즈의 영역으로 나누어 각 영역에 대해 형태와 크기가 미리 결정된 객체의 고정 개수를 예측한다.
대표적인 알고리즘으로 YOLO, SSD, RetinaNet이 있다.
2. 선택한 방식
2-1 채용한 알고리즘 YOLOv5
우리 팀이 채택한 알고리즘은 YOLO로 그 중 가장 최근 개바된 YOLOv5 모델이다.
YOLO 알고리즘은 단일 단계 방식의 알고리즘으로 하나의 네트워크 안에서 영역 제안과 분류를 수행하기 때문에 속도가 월등히 빠르다.
고정 grid 방식을 채용하기 때문에 훨씬 작은 수의 영역을 검사하고 높은 FPS(Frame Per Seconds)와 mAP(mean Average Precision)이 장점인 모델이다.
우리 팀은 동영상의 실시간 객체 탐지를 통해 하이라이트를 추출해야 하기 때문에 속도가 빠른 YOLO를 선택했고 아래의 오픈 소스를 이용하기로 결정했다.
2-2 채용한 개발 툴
일단 딥러닝을 위해서는 어느 정도의 성능을 요하는 개발환경이 필요한데 팀원 모두의 개발 환경을 고려했을 때,
공짜로 GPU의 활용을 제공하는 Google의 COLAB을 이용하기로 했다.
3. 다음 회의 예정
이번 회의를 통해서 객체 탐지에 사용하게 될 딥러닝 알고리즘을 선정했다.
딥러닝 알고리즘을 선정한 만큼 다음 회의까지 커스텀 데이터 셋을 이용해 한 번 이상의 동영상 객체 탐지를 수행해보고 필요한 점을 구상하기로 했다.
다음 회의에서는 객체 탐지를 수행해 본 결과, 동영상 편집 기능을 제공할 플랫폼 등을 결정하고 제안발표를 위한 내용을 논의하기로 했다.
