군집화, Clustering
지도 학습을 사용하여 이미지 내의 객체를 분류하는 것이 가능하지만 이는 많은 양의 질 좋은 학습 데이터를 필요로 한다.
추가적으로 인터넷 상에 사용할 데이터가 충분하지 않은 경우에 직접 커스텀 데이터를 만들어야 하는 문제가 있다.
따라서 학습 데이터가 필요하지 않은 군집화 알고리즘을 사용해 보면 좋을 것 같아 학습했다.
Clustering(군집화)는 샘플에 대한 사전 지식 없이 유사도에 근거하여 군집을 구분한다.
구분된 군집들 사이의 분산을 최대화하고 동일 군집 내에서는 분산을 최소화 시키려는 목적을 가지고 있다.
군집 간의 유사도 거리 측정 함수로
- Euclidean distance
- Mahalanobis distance
- Lance-Wiliams distance
- Hamming distacne
등이 사용된다.
군집화는 Hierarchical, Partitonal의 두 종류로 나눌 수 있다.
Hierarchical
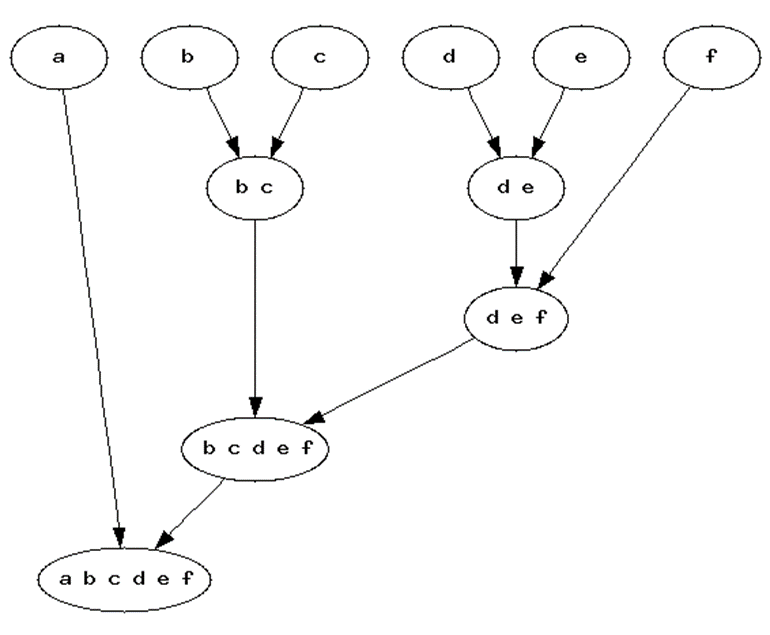
한 쪽 끝에는 각각의 요소가 다른 끝에는 모든 요소를 가진 하나의 클러스터가 존재하고 Tree 구조를 이룬다.
Partitional
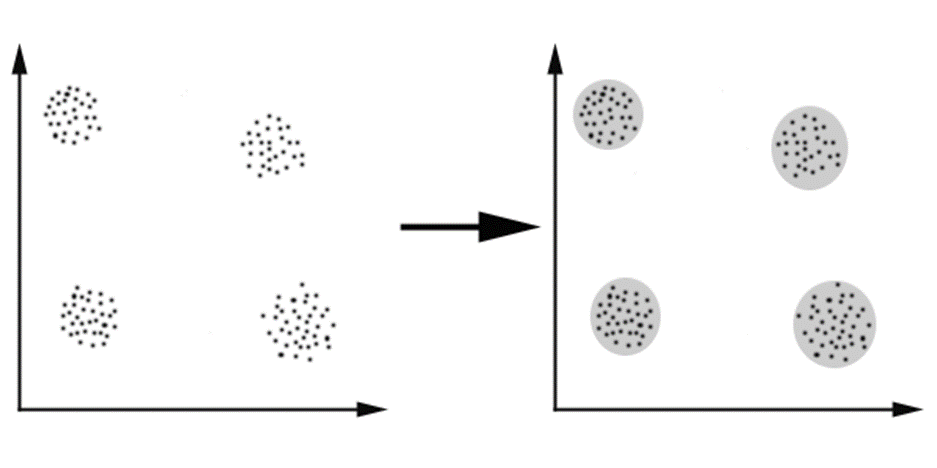
군집의 계층을 고려하지 않고 평면적으로 군집화한다.
군집화가 완료되면 1) 군집 간 거리 2) 군집의 지름 3) 군집의 분산을 통해서 해당 군집화가 타당한 지 검증한다.
실습 해 본 알고리즘
- Meanshift clustering
- K-Means clustering
- Auto Encoder
1. Meanshift
meanshift는 군집화를 하려는 대상 군집의 개수를 정하지 않고 수행하는 알고리즘이다.
알고리즘이 수행되면서 최적의 군집 개수를 찾아 해당 개수로 데이터를 군집화한다.
- sklearn의 MeanShift 알고리즘을 이용하여 랜덤 데이터에 대한 군집화 실습 수행.
군집화 된 데이터는 pandas의 dataframe을 이용하여 데이터를 가공하고 matplotlib의 pyplot의 scatter를 이용하여 분포를 시각화 했다.
첫번째 plot은 군집화하기 이전의 데이터의 분포이다.
두번째 plot은 알고리즘을 통해 군집화가 완료된 분포이다.
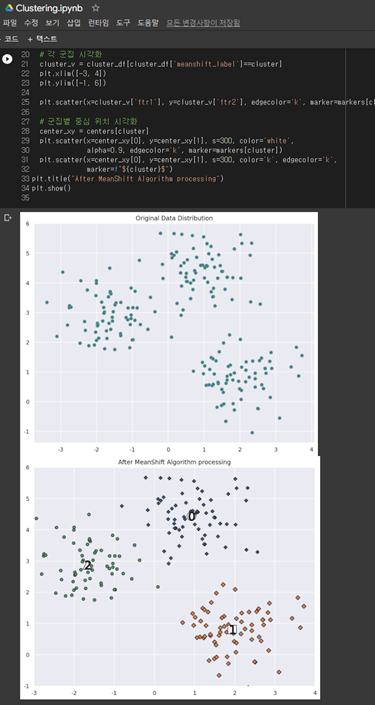
데이터는 다음 코드를 통해서 임의로 얻어왔다.
X, y = make_blobs(n_samples=200, n_features=2, centers=3,
cluster_std=0.7, random_state=0)2. K-Means
K-means 알고리즘은 K개의 군집을 묶는데 각 군집의 평균(means)을 활용하는 알고리즘이다.
간단하게 평균은 각 군집의 중심과 해당 군집 안의 데이터들 사이의 평균 거리를 의미한다.
K-means는 서로 가까운 데이터를 비슷한 특징을 가진 데이터로 인지하고 같은 군집으로 군집화 한다. 데이터 사이의 거리를 이용하는 것에서 K-NN과 유사하지만 K-NN은 지도, K-means는 비지도 학습이다.
K-means의 수행 과정은 다음과 같다.
- 군집화 할 군집의 개수 K를 미리 설정한다.
어떻게 보면 K-means의 한계점이다. 군집의 개수를 설정하는 것에도 Rule of thumb, Elbow Method, Information Criterion Approach의 세 가지 방식이 있다.- 초기 중심점을 선택한다.
초기 중심점을 선택하는 방법으로 Randomly. Manually assign, K-means++가 있고 K-means++ 를 실제로 사용한다.- 데이터를 군집으로 할당
거리 상 가장 가까운 주심점이 속한 군집으로 배정한다.- 중심점 갱신하기
중심점을 해당 군집의 데이터의 평균 위치로 재설정한다.- 3~4의 과정을 반복한다.
만약 4번의 과정에서 중심점이 변하지 않으면 종료한다.
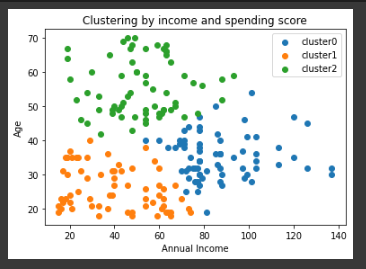
Kaggle의 Mall_Customers.csv 파일을 이용해 군집화를 시도했다.
열은 Annual Income과 Age를 사용했다.
실제로 군집화를 시행 해 본 결과는 좋은 열 선택은 아니었던 것 같다.
데이터 전처리 과정에서 MinMaxScaler를 사용하여 정규화를 수행했다. 정규화는 모든 값을 0~1 사이의 값으로 바꾸는 과정이다.
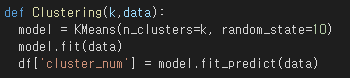
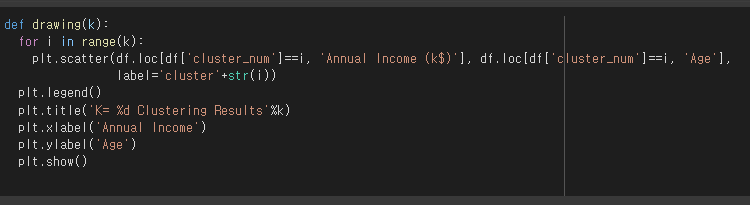
def drawing(k):
for i in range(k):
plt.scatter(df.loc[df['cluster_num']==i, 'Annual Income (k$)'], df.loc[df['cluster_num']==i, 'Age'],
label='cluster'+str(i))
plt.legend()
plt.title('K= %d Clustering Results'%k)
plt.xlabel('Annual Income')
plt.ylabel('Age')
plt.show()
물론 일반화를 위해서 선택한 열을 함수의 파라미터로 전송하는 것이 더 좋지만
빠르게 결과를 확인하기 위해 Annual Income과 Age를 대상으로만 확인할 수 있는 코드를 작성했다.
K=3
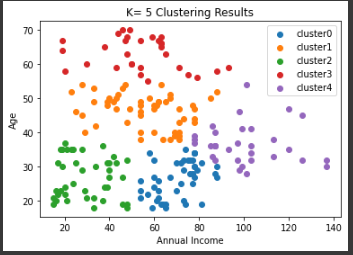
K=5
K=10
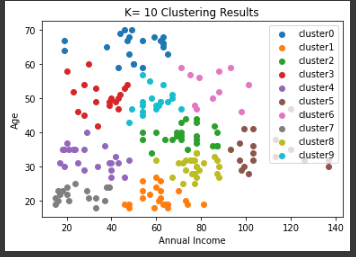
결과를 살펴보면 K=3 이나 5 정도가 적당해 보인다.
Elbow Method 등을 이용하면 적절한 K 값의 후보를 제안받을 수 있다.
3. Auto Encoder
Auto Encoder를 통해서 차원을 축소하거나 입력에 노이즈를 추가하여 학습시켜 실제의 더러운 이미지를 원본으로 복구하는 네트워크의 학습 등을 수행한다.
Auto encoder는 입력 데이터를 일종의 label로 삼아 학습하므로 self-supervised learning이라고 하지만 y를 사용하지 않기 때문에 비지도 학습이다.
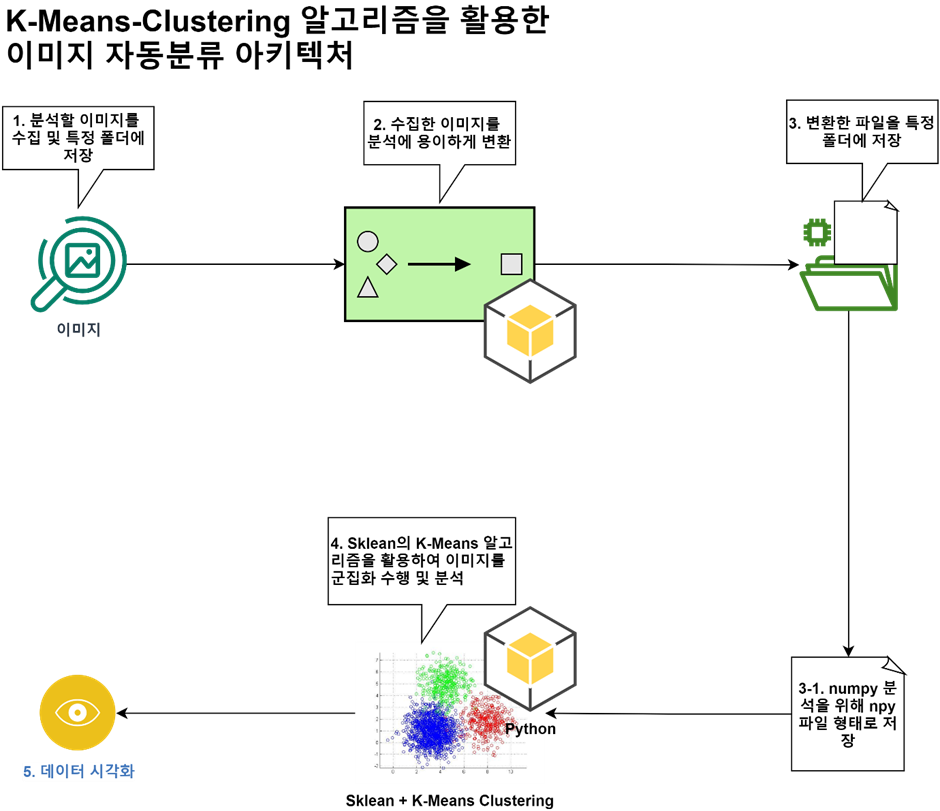
Auto Encoder를 통해서 이미지에서 의미있는 데이터를 뽑아내어 군집화의 데이터로 사용할 수 있는지 테스트 해보려고 Auto Encoder를 학습해보았다.
Auto Encoder의 종류로
1. Undercomplete
2. Stacked
3. Denoising (DAE)
4. Sparse
5. Variational Auto Encoder (VAE)
을 꼽을 수 있다.
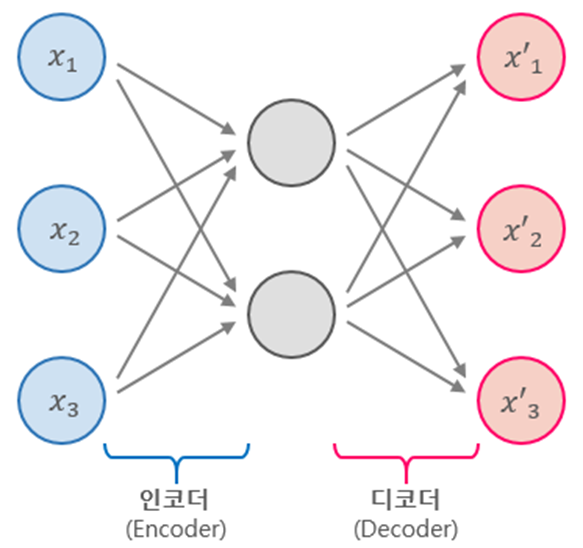 인코더 부분이 압축하는 부분이고 디코더가 확장하는 부분이다. 구조 자체는 MLP와 유사하다.
인코더 부분이 압축하는 부분이고 디코더가 확장하는 부분이다. 구조 자체는 MLP와 유사하다.
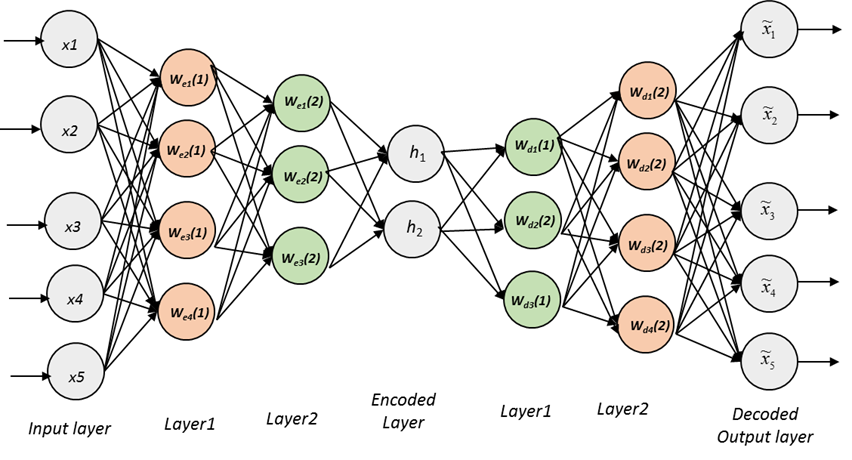 입력 층 + encoding 층 <-> 출력 층 + decoding 층이 대칭을 이루고
입력 층 + encoding 층 <-> 출력 층 + decoding 층이 대칭을 이루고
encoded layer에 Codings라는 노드들에는 대표적인 특성을 추출한 층이 있다.
그러므로 Encoded Layer의 노드 개수를 정하는 것은 매우 중요한 일이다. (파라미터로 전달하게 됨.)
Mnist 손글씨 이미지를 이용하여 Auto Encoder 실습을 진행해보았다.
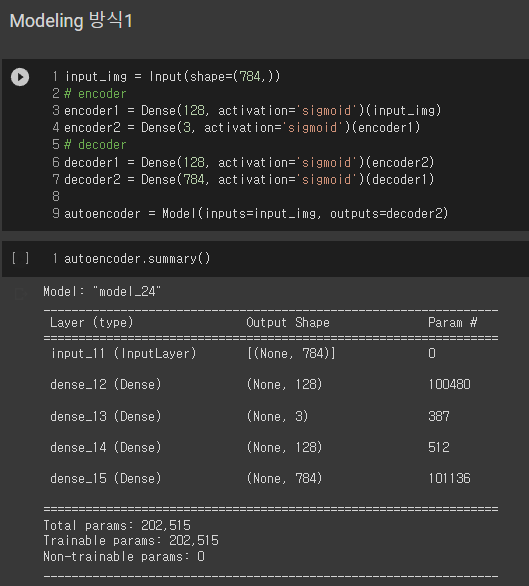 CNN처럼 층을 쌓아서 딥러닝 모델을 생성한다.
CNN처럼 층을 쌓아서 딥러닝 모델을 생성한다.
Sequential을 이용해서 모델을 쌓아서 생성할 수 도 있다.
위의 그림에서 보면 알 수 있는 encoder 부분과 decoder 부분을 생성한다.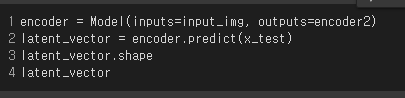
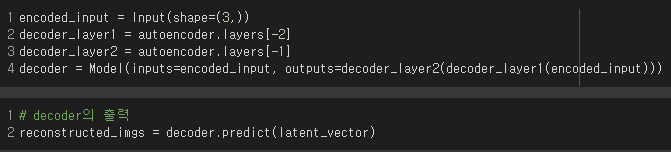
결과를 확인하면 아래의 출력을 얻을 수 있다.
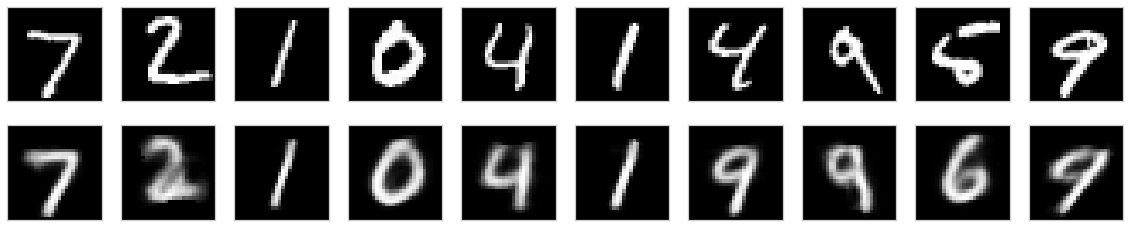
위 쪽은 입력 손글씨이고 아래쪽이 출력 이미지이다.
이미지를 매우 잘 복구하는 것을 알 수 있다. 2개 정도의 이미지를 제외하고 전부 성공했다.

좋은 글이네요! Clustering에 대해 조금 알게 됐습니다.
감사합니다~