Abstract
- We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions
- Experiments on two machine translation tasks
Introduction
- Recurrent models - fundamental constraint of sequential computation
- Transformer - eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output; allows for significantly more parallelization
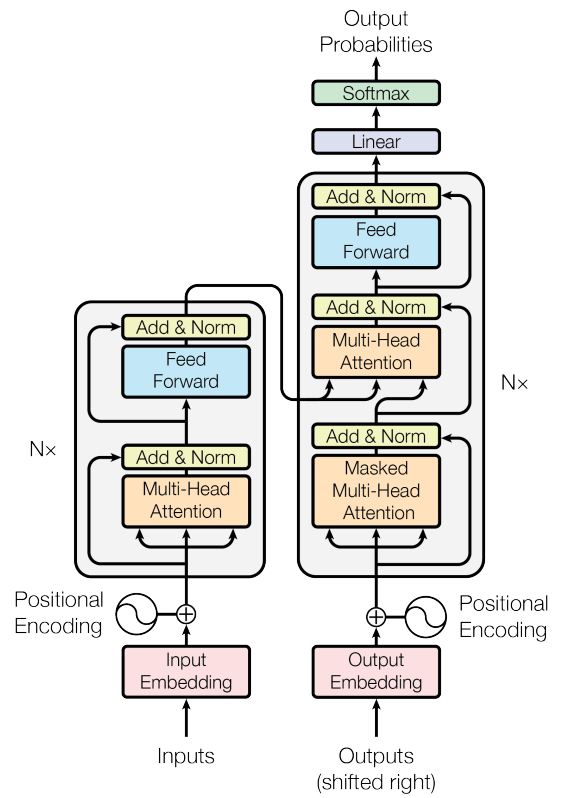
Model Architecture
Encoder and Decoder Stacks
Encoder
- composed of a stack of identical layers
- each layer has two sub-layers
- multi-head self-attention mechanism
- position-wise fully connected feed-forward network
- employ a residual connection around each of the two sub-layers, followed by layer normalization
- To facilitate residual connections, all sub-layers in the model, as well as embedding layers, produce outputs of dimension
Decoder
- also composed of a stack of identical layers
- In addition to the two sub-layers in each encoder layer
- modify the self-attention sub-layer in the decoder stack(masking) to prevent positions from attending to subsequent positions - decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack
- employ residual connections around each of the sub-layers, followed by layer normalization
Attention
Scaled Dot-Product Attention
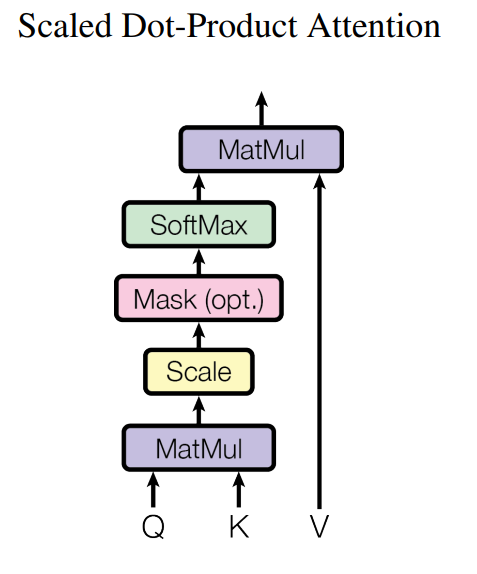
- input consists of
queries and keys of dimension
values of dimension - queries,keys, values are packed into matrices , ,
- compute the matrix of outputs as:
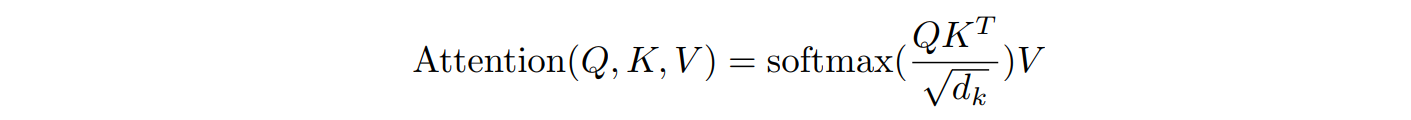
- compute the dot products of the query with all keys
- divide each by
- (only in decoder)
masking out (setting to ) values correspond to illegal connections - apply a softmax function to obtain the weights on the values
- for large values of , the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by
Multi-Head Attention
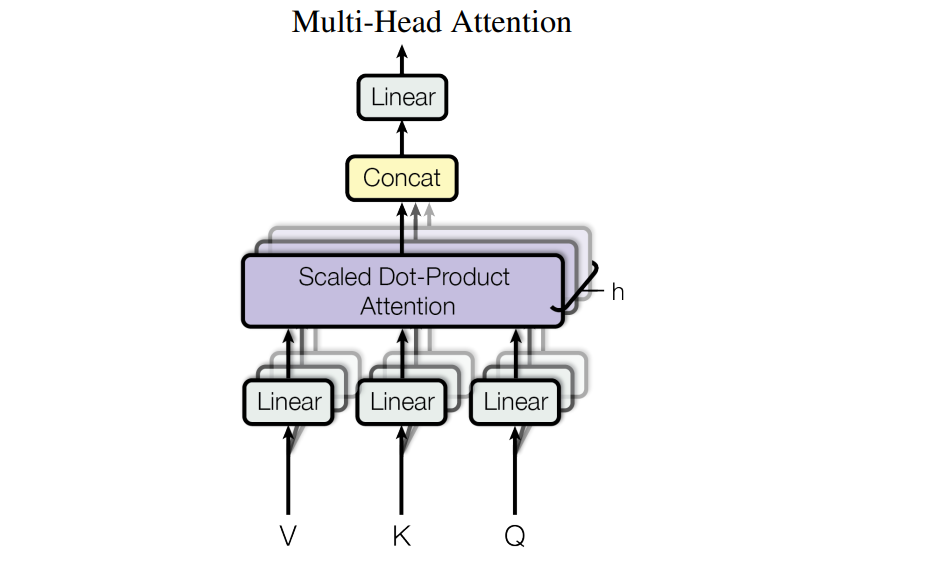
- linearly project the queries, keys and values times
with different, learned linear projections - on each of these projected versions of queries, keys and values, we then perform the attention function in parallel
- these are concatenated
- and once again projected, resulting in the final values

- allows the model to jointly attend to information from different representation subspaces at different positions
Applications of Attention in out Model
Transformer uses multi-head attention in three different ways:
- encoder-decoder attention
queries come from the previous decoder layer
keys and values come from the output of the encoder - self-attention layers in encoder
all of the keys, values and queries come from the output of the previous layer in the encoder - self-attention layers in decoder
all of the keys, values and queries come from the output of the previous layer in the decoder
prevent leftward information flow by masking
Position-wise Feed-Forward Netwoks
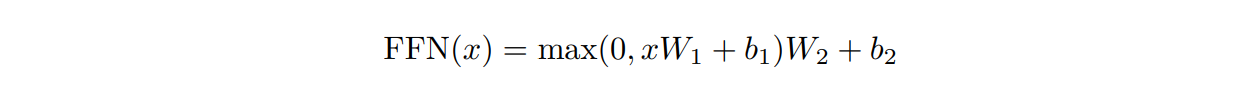
- each of the layers in our encoder and decoder contains a fully
connected feed-forward network, which is applied to each position separately and identically - While the linear transformations are the same across different positions, they use different parameters from layer to layer
- dimensionality of input and output is
- inner-layer has dimensionality
Embeddings and Softmax
- use learned embeddings to convert the input tokens and output tokens to vectors of dimension
- multiply those weights by
- use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities
- share the same weight matrix between the two embedding layers and the pre-softmax linear transformation
Positional Encoding
- add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks
- have the same dimension as the embeddings, so that the two can be summed
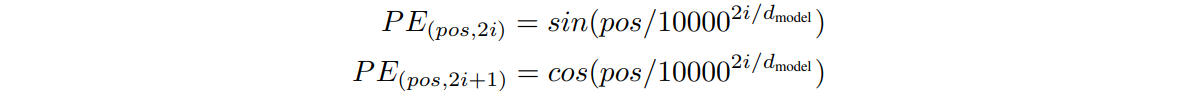
- is the position and is the index of dimension
Training
Training Data and Batching
- trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs
- Sentences were encoded using byte-pair encoding, which has a shared sourcetarget vocabulary of about 37000 tokens
- Sentence pairs were batched together by approximate sequence length
- Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens
Hardware and Schedule
- trained our models on one machine with 8 NVIDIA P100 GPUs
- trained the base models for a total of 100,000 steps or 12 hours
Optimizer
Regularization
Results
Machine Translation
- For the base models, we used a single model obtained by averaging the last 5 checkpoints, which were written at 10-minute intervals
- used beam search with a beam size of 4 and length penalty
- set the maximum output length during inference to input length + 50, but terminate early when possible
Model Variations

feed-forward dimension
number of attention heads
attention key dimension
attention value dimension
dropout rate

개발자 연습생