
Contents
1. 한국어 자연어 처리
자연어 처리의 기본 요소
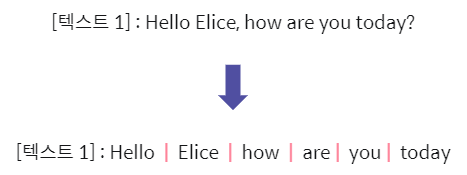
자연어 처리의 기본은 단어 추출에서 시작합니다.
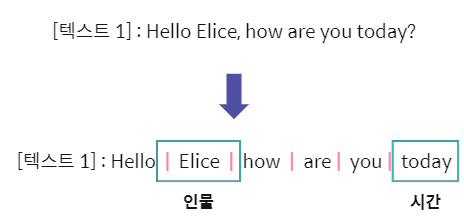
텍스트의 단어를 통해 문장의 의미, 구성 요소 및 특징을 파악할 수 있습니다.
한국어에서 단어란
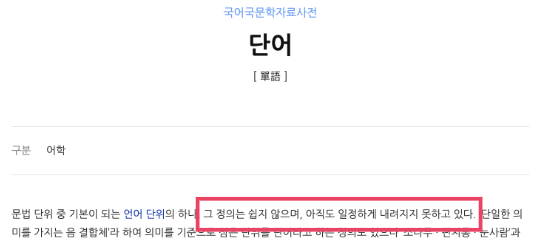
그러나 한국어에서 단어의 기준은 명확하지 않습니다.

교착어인 한국어에서 단어는 의미적 기능을 하는 부분과 문법적인 기능을 하는 부분의 조합으로 구성됩니다.
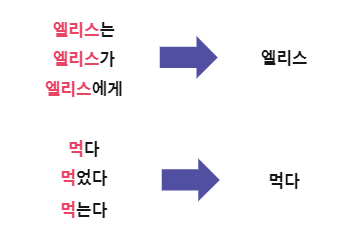
따라서 한국어 자연어 처리에서는 단어의 의미적 기능과 문법적인 기능을 구분하는 것이 중요합니다.
2. KoNLPy
형태소 분석
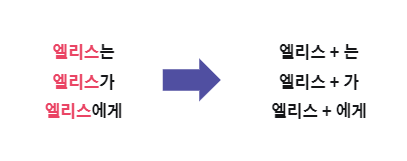
형태소 분석이란 주어진 한국어 텍스트를 단어의 원형 형태로 분리해 주는 작업입니다.
KoNLPy
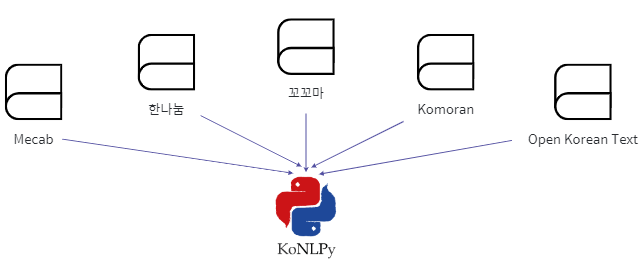
KoNLPy는 여러 한국어 형태소 사전을 기반으로 한국어 단어를 추출해 주는 파이썬 라이브러리입니다.
각 형태소 분석기는 Hannanum(), Kkma(), Komoran(userdict), Mecab(), Okt()의 형태로 호출할 수 있습니다.
from konlpy.tag import Kkma, Okt
kkma = Kkma()
okt = Okt()형태소 분석기를 통해서 명사가 무엇인지, 각 형태소의 품사가 무엇인지 등을 알 수 있습니다.
from konlpy.tag import Kkma, Okt
sent = "안녕 나는 엘리스야 반가워. 너의 이름은 뭐야?"
kkma = Kkma()
print(kkma.nouns(sent)) # ['안녕', '나', '엘리스', '너', '이름', '뭐']
print(kkma.pos(sent)) # [('안녕', 'NNG'), ('나', 'NP'), ('는', 'JX’),
# ('엘리스', 'NNG'), ('야', 'JX’), ...
print(kkma.sentences(sent)) # ['안녕 나는 엘리스야 반가워. 너의 이름은 뭐야?']또, Stemming도 진행할 수 있습니다.
print(okt.pos(sent, stem = True)) # ... ('반갑다', 'Adjective') ...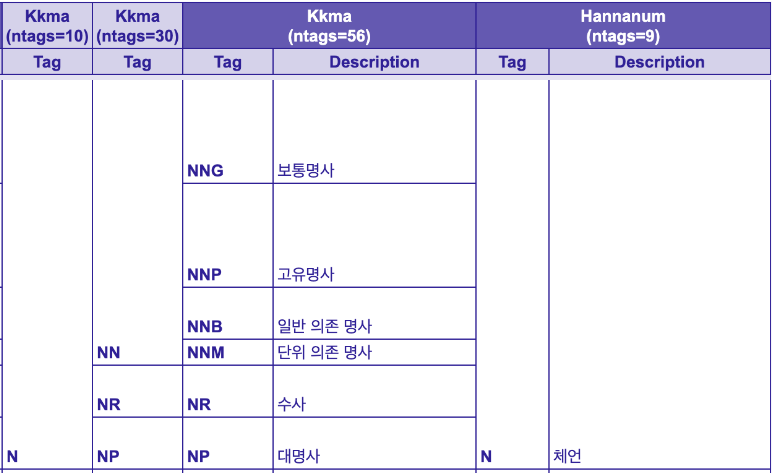
각 형태소 사전별 형태소 표기 방법 및 기준의 차이가 있기 때문에 용도에 따라 사용하면 됩니다.
3. soynlp

그러나 사전 기반의 단어 처리의 경우, 여기서도 또한 미등록 단어 문제가 발생할 수 있습니다.
soynlp
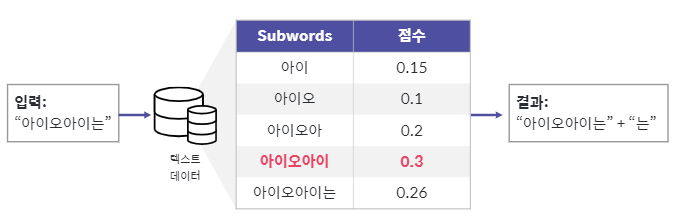
soynlp는 학습 데이터 내 자주 발생하는 패턴을 기반으로 단어의 경계선을 구분합니다.
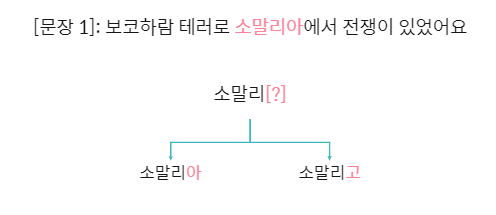
단어는 연속으로 등장하는 글자의 조합이며 글자 간 연관성이 높다는 가정을 깔고 있습니다.
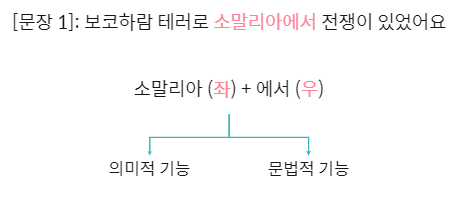
또한 한국어의 어절이 좌 - 우 구조로 2등분할 수 있다는 것도 이용합니다.
from soynlp.utils import DoublespaceLineCorpus
from soynlp.word import WordExtractor
from soynlp.noun import LRNounExtractor_v2
train_data = DoublespaceLineCorpus(학습데이터의경로) # 데이터기반패턴학습
noun_extractor = LRNounExtractor_v2()
nouns = noun_extractor.train_extract(train_data) # [할리우드, 모바일게임 ...
word_extractor = WordExtractor()
words = word_extractor.train_extract(train_data) # [클린턴, 트럼프, 프로그램...4. 문장 유사도
문장 유사도

문장 간 유사도는 공통된 단어 혹은 의미를 기반으로 계산합니다.
자카드 지수

자카드(Jaccard) 지수는 문장 간 공통된 단어의 비율로 문장 간 유사도를 정의합니다.

위와 같은 식으로 계산하며, 그에 따라 자카드 지수는 문장 간 유사도를 0~1 사이로 정의하게 됩니다.
코사인 유사도
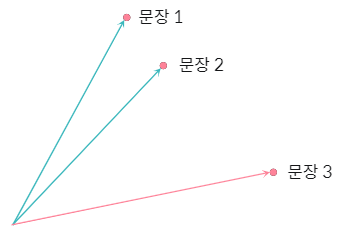
코사인 유사도는 문장 벡터 간의 각도를 기반으로 계산합니다.
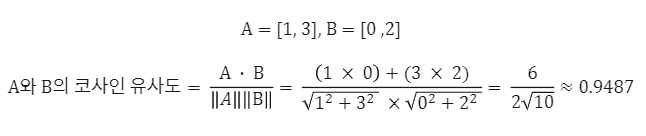
이는 간단히 벡터 간 내적을 사용하여 계산할 수 있습니다.
코사인 유사도는 고차원의 공간에서 벡터 간의 유사성을 잘 보존한다는 장점이 있습니다.
