
Contents
1. 감정 분석 서비스
2. 나이브 베이즈
3. 나이브 베이즈 기반 감정 예측
4. scikit-learn을 통한 나이브 베이즈 구현
5. 기타 감정 분석 기법
1. 감정 분석 서비스
텍스트 데이터의 종류
뉴스, 백과 사전 같은 텍스트는 객관적인 정보를 제공
| 문장 | 감정 |
|---|---|
| 영상미가 뛰어나고 너무너무 재미있었어요... | 기쁨 |
| 배우들의 뛰어난 연기... | 기쁨 |
| 허무한 결말... | 분노 |
리뷰, 소설 같은 텍스트는 저자의 주관적인 평가나 감정을 표현합니다.
하지만 대량의 텍스트가 있는 경우, 일일히 데이터를 하나씩 살펴보고 판단하기 어렵습니다.
감정 분석이란
비슷한 감정을 표현하는 문서는 유사한 단어 구성 및 언어적 특징을 보이지 않을까?
문장 감정 영상미가 뛰어나고 너무너무 재미있었어요... 기쁨 배우들의 뛰어난 연기... 기쁨 너무 흥미진진한 구성... 기쁨

감정 분석(Sentiment Analysis)는 텍스트 내에 표현되는 감정 및 평가를 식별하는 자연어 처리의 한 분야입니다.
텍스트내 감정을 분류하거나 긍정/부정의 정도를 점수화 합니다.
감정 분석 서비스
머신러닝 기반 감정 분석 서비스의 경우, 데이터를 통한 모델 학습부터 시작합니다.
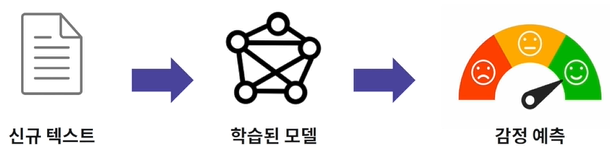
학습된 머신러닝 모델을 통해 신규 텍스트의 감정을 예측하는 것입니다.
2. 나이브 베이즈
나이브 베이즈의 원리
[텍스트 1]: 영상미가 | 뛰어나고 | 너무너무 | 재미있었어요
=> (S: 감정, T: 텍스트)
나이브 베이즈 기반 감정 분석은 주어진 텍스트가 특정 감정을 나타낼 확률을 예측하는 문제로 정의합니다.
베이즈 정리를 사용하여 텍스트의 감정 발생 확률을 추정합니다.
즉, 다음과 같은 식으로 이루어 집니다.
[텍스트 1]: 영상미가 | 뛰어나고 | 너무너무 | 재미있었어요
[텍스트 1의 감정]: 해당 감정 내 단어들이 발생할 가능성 감정의 발생 확률
감정의 발생 확률과 텍스트를 구성하는 단어들의 가능도(likelihood)로 텍스트의 감정을 예측합니다.
단어의 가능도
: 단어, : 감정
(감정 내 단어의 빈도수) / (감정 내 모든 단어의 빈도수)
"재미있었어요"기쁨 = (기쁨을 표현하는 문서 내 재미있었어요의 빈도수) / (기쁨을 표현하는 문서 내 모든 단어의 빈도수)
텍스트 데이터에서 가능도는 단어의 빈도수로 추정합니다.
감정의 발생 확률
감정 (해당 감정을 표현하는 문서의 수) / (데이터 내 모든 문서의 수)
감정의 발생 확률은 주어진 텍스트 데이터 내 해당 감정을 표현하는 문서의 비율로 추정합니다.
텍스트의 감정
이렇게 텍스트의 감정별 확률 값을 구한뒤, 이 중 최대 확률값을 나타내는 감정을 해당 문서의 감정으로 예측하게 됩니다.
3. 나이브 베이즈 기반 감정 예측
스무딩 (smoothing)
앞의 나이브 베이즈를 통해 감정 발생 확률을 예측하게 된다면
학습 데이터 내 존재하지 않은 단어가 포함된 문장의 감정 발생 확률은 0이 된다.
"재미있었어요"기쁨 = (기쁨을 표현하는 문서 내 재미있었어요의 빈도수 + 1) / (기쁨을 표현하는 문서 내 모든 단어의 빈도수 + 1)
따라서 스무딩(smoothing)을 통해 학습 데이터 내 존재하지 않은 단어의 빈도수를 보정한다.
소수
[텍스트 1]: 영상미가 | 뛰어나고 | 너무너무 | 재미있었어요
[텍스트 1]이 기쁨을 나타낼 확률 :
[텍스트 1]이 기쁨을 나타낼 확률 :
단어의 감정별 가능도와 감정의 발생 확률은 모두 소수로 표현합니다.

따라서 단어의 수가 많아질 수록 텍스트의 확률값은 컴퓨터가 처리할 수 있는 소수점의 범위보다 작아질 수 있습니다.
로그
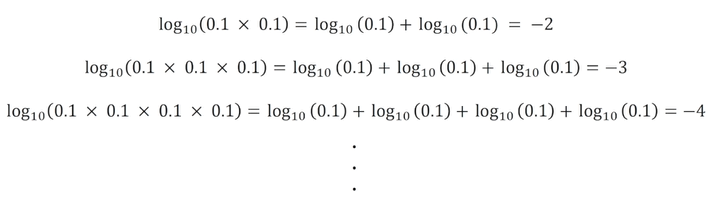
이때 로그를 사용하면 끊임없이 숫자가 작아지는 것을 방지할 수 있습니다.
따라서 로그 확률값의 합으로 텍스트의 감정을 예측하게 됩니다.
4. scikit-learn을 통한 나이브 베이즈 구현
scikit-learn

scikit-learn은 각종 데이터 전처리 및 머신 러닝 모델을 간편한 형태로 제공하는 파이썬 라이브러리입니다.
Example
from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNB doc = ["i am very happy", "this product is really great] emotion = ["happy", "excited"] cv = CountVectorizer() csr_doc_matrix = cv.fit_transform(doc) # 각 단어 및 문장 별 고유 ID 부여 및 단어의 빈도수를 계산 print(csr_doc_matrix) # (0, 0) 1, (0, 7) 1 clf = MultinomialNB() # Count Vectorizer로 변환된 텍스트 데이터를 사용 clf.fit(csr_doc_matrix, emotion)
Test
test_doc = ["i am really great"] # 학습된 CountVectorizer 형태로 반환 transformed_test = cv.transform(test_doc) pred = clf.predict(transformed_test)\ print(pred) # array(['excited'], dtype=`<U7`)
5. 기타 감정 분석 기법
감정 분석
감정 분석은 지도 학습(supervised learning) 기반의 분류 및 예측의 문제입니다.
감정 분석 + 머신러닝
| 문장 | 감정 |
|---|---|
| 영상미가 뛰어나고 너무너무 재미있었어요... | 기쁨 |
| 허무한 결말... | 분노 |
| 인생 최고의 영화... | 감동 |
학습 데이터에 감정만 존재하면 머신러닝 알고리즘 학습이 가능합니다.

더 구체적으로는 임베딩 벡터를 사용하여, 머신러닝 알고리즘 적용이 가능합니다.
예시: 평균 임베딩 벡터

가장 간단한 방법으로 단어 임베딩 벡터의 평균을 사용할 수 있습니다.
예시: CNN
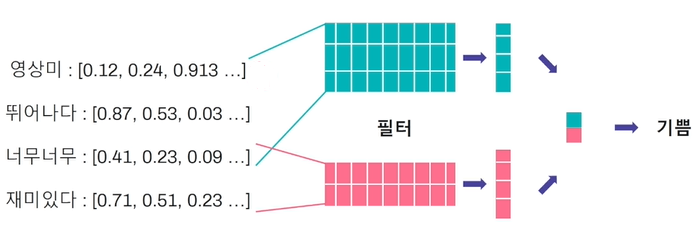
단어 임베딩 벡터에 필터를 적용하여 CNN 기반으로 감정을 분류할 수 있습니다.
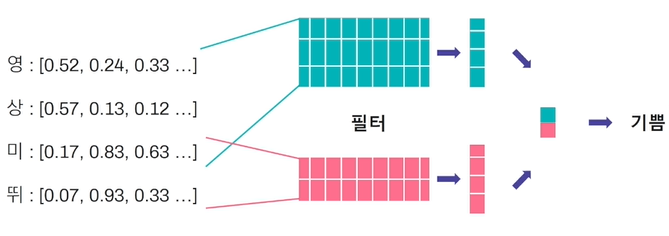
또는 문자 임베딩 벡터에 필터를 적용하여 CNN 기반으로 감정을 분류할 수도 있습니다.
예시: RNN
LSTM, GRU를 사용하여 RNN 기반으로 분류 및 예측할 수도 있습니다.
RNN 역시 문자 단위로 단어를 분리하여 분류 및 예측할 수 있습니다.
