
Contents
01. 자연어 처리
자연어 처리란
자연어 처리(Natural Language Processing, NLP)는 컴퓨터를 통해 인간의 언어를 분석 및 처리하는 인공지능의 한분야
자연어 처리의 적용 사례
- 문서 분류
- 키워드 추출
- 감정 분석
자연어 처리 + 머신 러닝
학습 가능한 데이터양의 증가 및 연산 처리 속도의 발전으로 자연어 처리 또한 더욱 복잡한 머신러닝 알고리즘 적용 가능
머신러닝 기반 자연어 처리의 적용 사례
- 문서 요약
- 기계 번역 (ex. Papago)
- Chat bot
02. 텍스트 전처리
모델링을 위한 데이터 탐색 및 전처리
- 데이터 탐색
- 데이터 통계치 -> 단어의 개수
- 변수별 특징 -> 단어별 빈도수
- ...
- 데이터 전처리
- 이상치 제거 -> 특수기호 제거
- 정규화 (normalization) -> 단어 정규화
- ...
Tokenization
텍스트 1: Hello, my name is Elice! What is your name?
-> 텍스트 1: Hello, | my | name | is | ... | name?
가장 기본적인 토큰화의 기준은 공백
-> 텍스트 1: hello | my | name | is | ... | name
소문자 처리 및 특수기호 제거를 통해 동일한 의미의 토큰은 동일한 형태로 변환
단어의 개수 및 빈도수 확인
counter = dict()
with open(파일명, 'r') as f:
for line in f
for word in line.rstrip().split():
if word not in word_counter:
word_counter[word] = 1
else:
word_counter[word] += 1자연어 처리 + 머신러닝
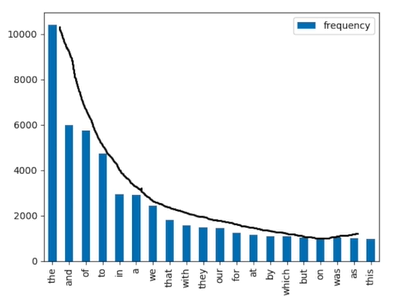
대부분 단어 빈도수의 분포는 지프의 법칙(Zipf's law)를 따름
전처리 1: 특수기호 제거
import re
word = "123hello993 $!%eli$@ce^"
regex = re.compile('[^a-x A-Z]')
print(regex.sub('', word))
# hello elice전처리 2: Stopword 제거

문법적인 기능을 지닌 단어 및 불필요하게 자주 발생하는 단어를 제거
import nltk
from nltk.corpus import stopwords
sentence = ["the", "green", "egg", "and", "ham", "a", "an"]
stopwords = stopwords.words('english')
new_sentence = [word for word in sentence if word not in stopwords]
print(new_sentence)
# ["green", "egg", "ham"]import nltk
from nltk.corpus import stopwords
new_stopwords = ["none", "는", "가"]
stopwords = stopwords.words('english')
stopwords += new_stopwords전처리 2: Stemming
(Studies, Studied, Studying) => Studi
(Dogs, Dog) => Dog
동일한 의미의 단어이지만, 문법적인 이유 등 표현 방식이 다양한 단어를 공통된 형태로 변환
import nltk
import nltk.stem import PorterStemmer
words = ["studies", "studied", "studying", "dogs", "dog"]
stemmer = PorterStemmer()
for word in words:
print(stemmer.stem(word)) # studi, studi, studi, dog, dog03. 단어 임베딩
컴퓨터 - 언어
컴퓨터는 텍스트를 포함하여 모든 데이터를 0과 1로 처리
따라서 자연어의 기본 단위인 단어를 수치형 데이터로 표현하는 것이 중요
단어 임베딩
단어 임베딩이란 각 단어를 연속형 벡터로 표현하는 방법을 의미
엘리스 => [0.23, 0.401, 0.482, 0.42, 0.99, ...]
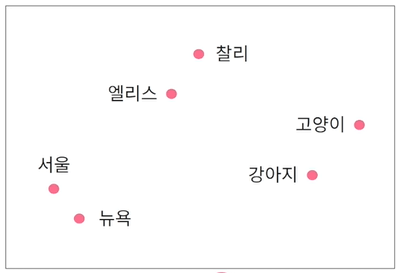
- 서울에 살고 있는 엘리스는 강아지를 좋아한다.
- 뉴욕에 살고 있는 찰리는 고양이를 좋아한다.
=> 비슷한 문맥에서 발생하는 단어는 유사한 의미를 지님
따라서 유사한 단어의 임베딩 벡터는 인접한 공간에 위치
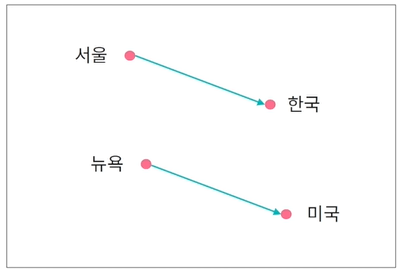
이를 통해 임베딩 벡터 간 합과 차로 단어의 의미적 특징을 활용 가능
04. word2vec
word2vec
word2vec은 단일 신경망(Newral Network)을 통해 단어 임베딩 벡터를 학습
주어진 문맥에서 발생하는 단어를 예측하는 문제로 단어 임베딩 벡터를 학습
Ex) 서울에 살고 있는 엘리스는 강아지를 좋아한다.

각 단어의 벡터는 해당 단어가 입력으로 주어졌을 때 계산되는 은닉층의 값을 사용
gensim
from gensim.models import Word2Vec
doc = [["서울에", "살고", "있는", "엘리스는", "강아지를", "좋아한다"]]
w2v_model = Word2Vec(min_count=1, window=2, vector_size=300)
w2v_model.build_vocab(doc)
w2v_model.train(doc, total_examples=w2v_model.corpus_count, epochs=20)min_count: 최소 빈도수
window: 해당 단어 앞뒤로 인자로 사용할 단어의 개수
corpus_count: 학습 데이터안 문서의 개수
epochs: 학습 반복횟수
similar_word = w2v_model.wv.most_similar("엘리스는")
print(similar_word)
# [('있는', 0.05005083233118057), ('좋아한다', 0.03316839784383774), ...]
score = w2v_model.wv.similarity("엘리스는", "좋아한다")
print(score)
# 0.0331683978438377405. fastText
fastText
word2vec은 학습 데이터 내 존재하지 않았던 단어 벡터는 생성할 수 없음.(미등록 단어 문제)
fastText는 각 단어를 문자 단위로 나누어서 단어 임베딩 벡터를 학습
이를 통해 학습 데이터에 존재하지 않았던 단어의 임베딩 벡터 또한 생성이 가능.
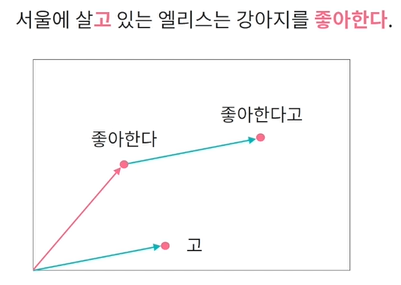
from gensim.models import FastText
doc = [["서울에", "살고", "있는", "엘리스는", "강아지를", "좋아한다"]]
ft_model = FastText(min_count=1, window=2, vector_size=300)
ft_model.build_vocab(doc)
ft_model.train(doc, total_examples=ft_model.corpus_count, epochs=20)similar_word = ft_model.wv.most_similar("엘리스는")
print(similar_word)
# [('있는', 0.05005083233118057), ('좋아한다', 0.03316839784383774), ...]
new_vector = ft_model.wv["좋아한다고"]
print(new_vector)
# array([-5.9223123e-04, -1.3244342e-03, ...])
좋은 글 감사합니다. 자주 올게요 :)