
Contributions
-
Source data 없이 오직 target data 만으로 진행할 수 있는 Fully test-time adaptation을 강조한다.
-
를 adaptation 목표로 사용하는 를 제안한다.
-
왜곡에 강건함을 보이기 위해 ImageNet-C에서의 결과를 비교한다.
-
Domain adaptation이 가능함을 보이기 위해 Digit classification (SVHN-MNIST)과 시뮬레이션-실제 환경에서의 Semantic Segmentation을 비교한다.
Setting: Fully Test-Time Adaptation
Source data 로 학습된 는 shifted target data 에 대해 적용되기 어렵다.
우선 기존의 TTA를 위한 연구를 나열한다.
- Transfer learning by fine-tuning: Supervised loss 를 계산하기 위해 target label이 필요함.
- Domain Adaptation: Cross-domain loss 로 학습시키기 때문에 source 데이터와 target 데이터가 모두 필요함.
- Test-time Training(TTT): Adaptation 이전에 먼저 supervised loss 와 self-supervised loss 를 최적화하도록 설정함.
그러나 예상 못한 test data가 있기 때문에, TTT와 본 논문은 model을 테스트 중 unsupervised loss 를 최적화해야 한다.
Fully Test-Time Adaptation은 로 표현되는 training data와 training loss에 독립적이며, 이를 변조하지 않고, 적은 데이터와 연산으로 adaptation을 수행한다.
- 정리하면 아래와 같다.

Method: Test Entropy Minimization via Feature Modulation
본 논문은 Feature를 변조함으로써 예측 엔트로피를 최소화하는 방향으로 테스트 중 model을 최적화한다.
Model은 반드시 supervised task로 훈련되어 있어야 하며, 확률적이고, 미분가능해야한다.
- 테스트 중에는 어떤 지도도 이루어지지 않기에, Model은 이미 훈련되어있어야 한다.
- Entropy의 계산은 prediction의 분포를 사용하기 때문에 모델이 확률분포로 나타나야 한다.
- 또한 빠르고 iterative한 최적화를 위해 Gradient를 계산해야 하므로, 미분가능해야 한다.
전형적인 지도학습을 위한 DNN 네트워크는 이를 충족할 것이다.

Entropy Objective
Test-time의 목표 는 모델의 예측 에 대해 엔트로피 를 최소화하는 것이다.
더 자세히, 클래스 의 확률 에 대해 Shannon entropy 를 계산한다.
한 개의 예측을 최적화하기 위해 모든 확률을 가장 높은 확률에게 몰아주는 방법이 있다.
- 이를 막기 위해 Tent에서는 여러 데이터 포인트를 묶은 배치를 사용하고, 더 넓은 범위의 입력에 대해 안정적인 예측을 할 수 있도록 돕는다.
- 또한 배치 내의 모든 예측을 공유된 파라미터를 사용하여 최적화함으로써 모델이 배치를 일관성있게 처리하도록 한다.
- Proxy task도 고려할 수 있으나, 업데이트를 제한하거나 혼합해야 하며, 적절한 프록시를 선택하기 위해 매우 많은 노력을 해야한다. Entropy objective는 이런 노력이 필요 없다.
Modulation Parameters
Model parameter 는 test-time에서 사용할 수 있는 자연스러운 선택이며, 선행 연구들에서도 사용되었다.
그러나 는 source data를 표한할 수있는 유일한 수단이며, 이를 변형하는 것은 모델이 훈련 데이터로부터 벗어나게 만들 수 있다.
더 나아가 는 비 선형적이고, 는 높은 차원을 갖기 때문에, test-time에 사용하기에는 너무 민감하고 비효율적이다.
따라서 안정성과 효율성을 위해, 선형적이고 저차원의 feature 만 업데이트한다.

- 먼저 Input 를 로 정규화한다.
- 그리고, 를 affine 매개변수 (scale 와 shift )를 사용하여 로 업데이트 한다.
구현을 위해 tent는 model의 normalization layer를 단순히 재활용하여 테스트 동안 모든 레이어에 대해 매개변수들을 업데이트한다.
Algorithm
Initialization
- Optimizer가 source model의 각 정규화 레이어 과 채널 에 대해 아핀변환 매개변수 를 수집한다.
- 남아있는 매개변수 는 그대로 고정되어 있다.
def setup_tent(model):
model = tent.configure_model(model)
params, param_names = tent.collect_params(model) // parameter 수집
optimizer = setup_optimizer(params) // optimizer에게 전달
tent_model = tent.Tent(model, optimizer, steps=cfg.OPTIM.STEPS, episodic=cfg.MODEL.EPISODIC)
return tent_model
def setup_optimizer(params):
if cfg.OPTIM.METHOD == 'Adam':
return optim.Adam(params, lr=cfg.OPTIM.LR, ... ) // optimize 대상을 params로 설정def collect_params(model):
params = []
names = []
for nm, m in model.named_modules():
if isinstance(m, nn.BatchNorm2d): // 배치 정규화 레이어
for np, p in m.named_parameters():
if np in ['weight', 'bias']: # weight is scale, bias is shift
params.append(p)
names.append(f"{nm}.{np}")
return params, namesIteration
매 스텝마다 normalization statistics와 transformation parameter를 각 배치마다 업데이트한다.
- Normalization statistics는 forward pass 중 계산된다.
- Transformation parameter 는 backward pass 중 예측 엔트로피의 gradient 를 통해 업데이트된다.
class Tent(nn.Module):
...
def forward(self, x):
...
for _ in range(self.steps):
outputs = forward_and_adapt(x, self.model, self.optimizer)
return outputs@torch.enable_grad() # ensure grads in possible no grad context for testing
def forward_and_adapt(x, model, optimizer):
outputs = model(x) // output 계산
loss = softmax_entropy(outputs).mean(0) // -(x.softmax(1) * x.log_softmax(1)).sum(1)
loss.backward() // gradient 계산
optimizer.step() // parameter 업데이트
optimizer.zero_grad() // gradient 초기화
return outputsTermination
- Online adaptation에서 termination은 필요없습니다. 테스트 데이터가 있는 한 계속 수행된다.
- Offline adaptation에서는 먼저 업데이트를 수행한 후, 여러 Epoch에 걸쳐 추론을 반복한다.
Experiments
Datasets
-
Image classification for corruption
- ImageNet (1000 class, 1.2M training set + 50,000 validation set)
- CIFAR-10/CIFAR-100 (10/100 class, 50,000 training set + 10,000 test set)
-
Image classification with domain adaptation
- SVHN as source (73,257 training set + 26,032 test set)
- MNIST/MNIST-M/USPS as targets (60,000/60,000/7,291 training set + 10,000/10,000/2,007 test set)
Models
- ResNet을 사용한다.
- CIFAR-10/100에 대해서는 26레이어(R-26), ImageNet에서는 50레이어(R-50)를 사용한다.
Optimization
- ImageNet은 SGD with momentum, 다른 데이터셋에서는 Adam을 사용한다.
- ImageNet에서는 Learning Rate = 0.00025, Batch size = 64
- 다른 데이터셋에서는 Learning Rate = 0.001, Batch size = 128을 사용한다.
Baselines
대조군을 다음과 같이 설정한다.
- Source: Adaptation을 수행하지 않은 classifier
- RG: Adversarial domain adaptation
- UDA-SS: Self-supervised domain adaptation
- TTT: Test Time Training
- BN: Target data에 대한 batch normalization
- PL: Pseudo labeling: 일정 threshold 이상의 예측을 label로 사용하여 모델을 학습시킴.
BN, PL, TENT 만이 fully test-time adaptaion이며, 나머지는 source 데이터가 필요하다.
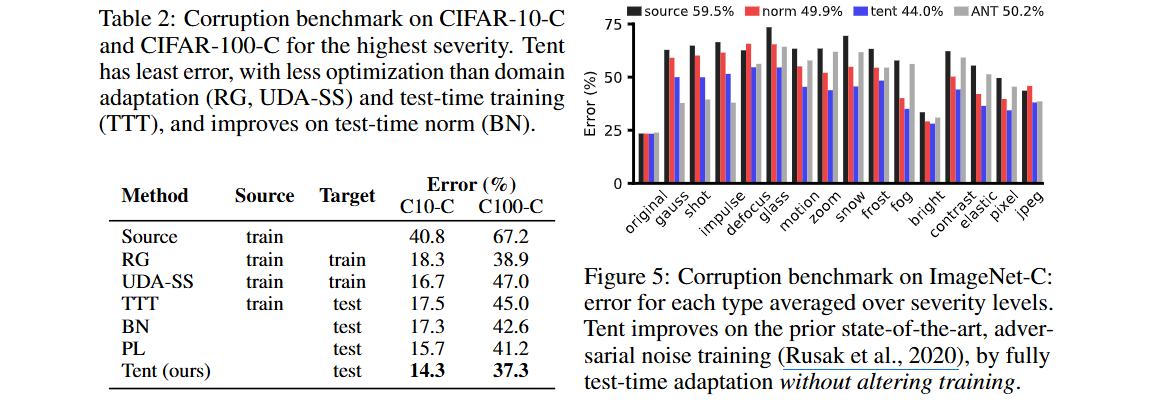
Robustness to Corruption
15가지 유형의 corruption을 다섯가지 심각도로 적용하여 CIFAR-10/100, ImageNet-C에서 테스트한다.

Source-Free Domain Adaptation
SVHN(거리의 집 번호, 유채색) -> MNIST(손글씨 숫자, 무채색)
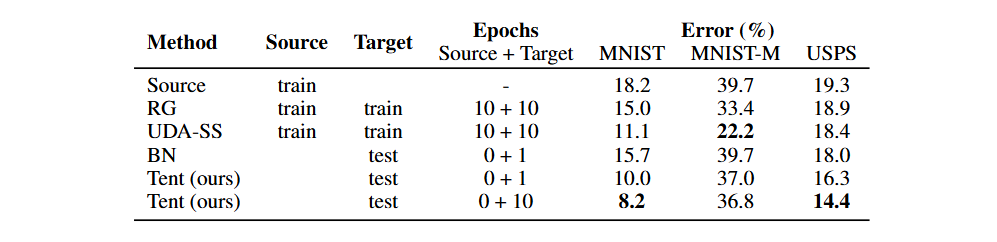
- Source 데이터 없이도 adaptation이 가능한 것을 보임.
- 더 적게 연산하지만 더 좋은 성능을 보임.
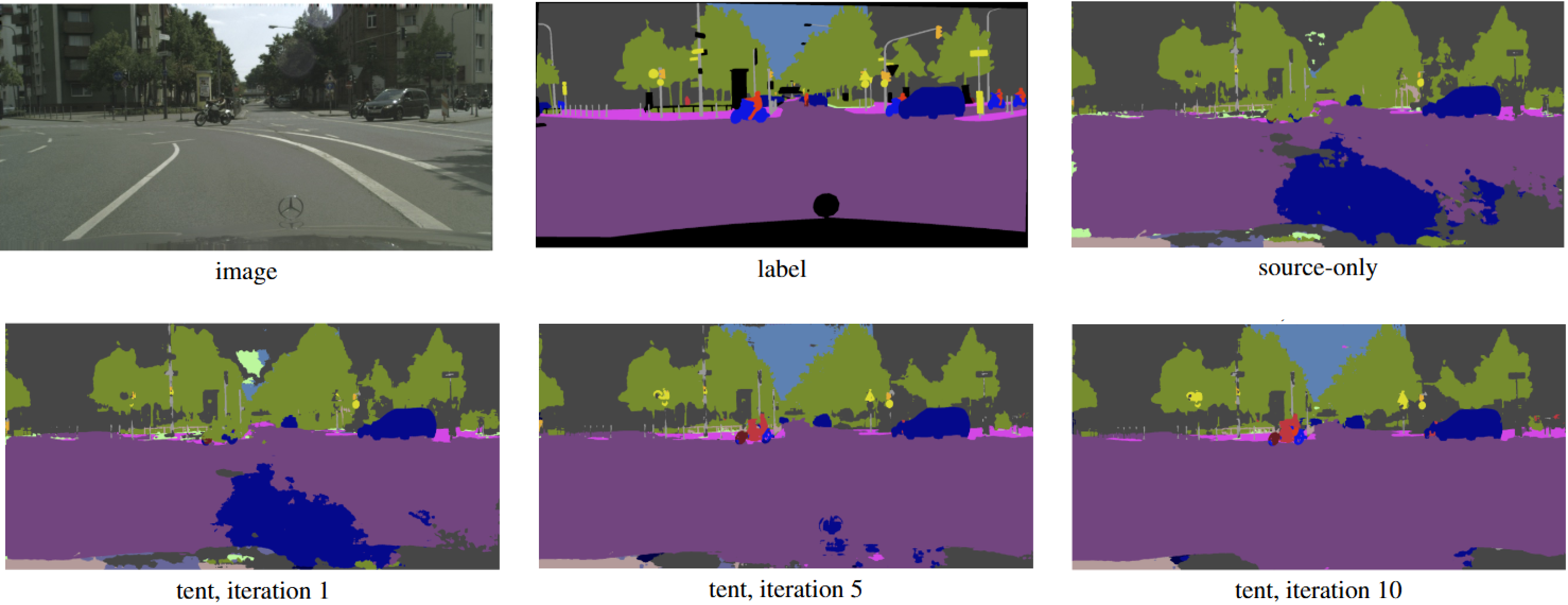
GTA(게임) -> CityScape(자율주행 데이터셋) 에서의 Semantic Segmentation 결과
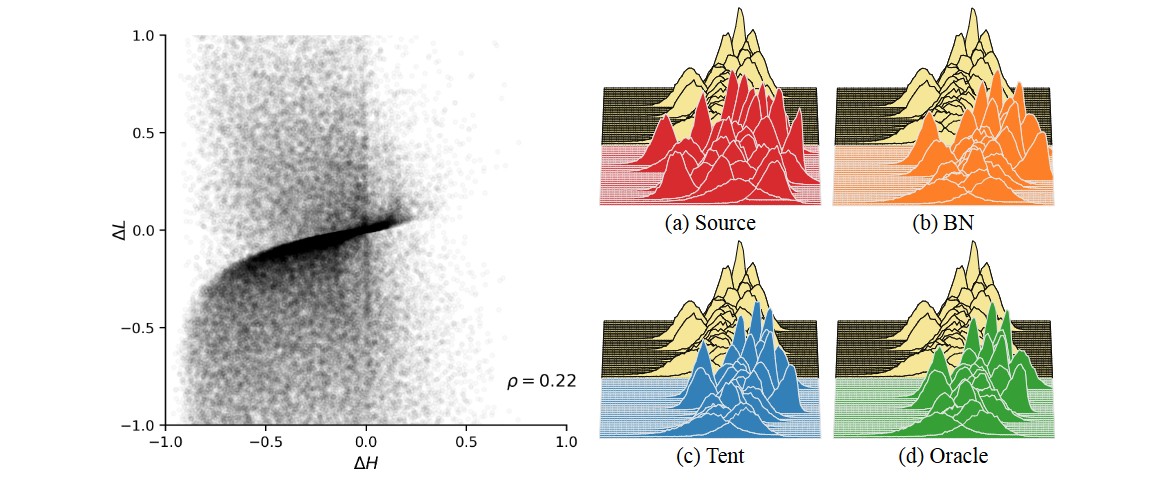
Analysis
- 대부분의 점이 왼쪽 아래에 있음 -> TENT가 Loss와 Entropy를 모두 감소시킴
- 진한 대각선 () -> Loss와 Entropy간에 상관관계가 존재함.
Ablation study
- Normalization을 수행하지 않는 경우: BN이나 PL보다 에러가 높아짐.
- Transformation을 수행하지 않는 경우: BN
Alternative architecture
- Tent는 model-agnostic함.
- 아래 표는 Self-Attention (SAN)과 Equilibrium solving (MDEQ)에 대해 corruption robustness를 평가한 결과임.

