Preliminaries
Normed Vector Spaces
Normed Vector Spaces (놈 공간)은 vector space X와 X의 원소에 대한 norm ∥⋅∥으로 정의된다.
Norm은 매핑 X→R으로 정의된다.
단, 다음 조건들을 만족해야 한다.
- ∥x∥≥0,∀x∈X 와 ∥x∥=0⇒x=0
- ∥αx∥=∣α∣∥x∥ (homogeneity)
- ∥x1+x2∥≤∥x1∥+∥x2∥ (triangle inequality, 삼각부등식)
이 수업에서는 아래와 같이 표기한다.
- Vector spaces: X=Rd
- Norms:
- max-norm/L∞ norm ∥⋅∥∞
- (weighted) L2 norm: ∥⋅∥2,ρ
Contraction Mapping
X가 norm ∥⋅∥를 갖는 벡터공간일 때, 매핑 T:X→X이 x1,x2∈X,∃α∈[0,1]에 대하여
∥Tx1−Tx2∥≤α∥x1−x2∥
를 만족한다면 이를 α-contraction 매핑이라고 한다.
- 만약 α∈[0,1]라면 우리는 T를 non-expanding이라고 부른다.
- 모든 contraction은 정의에 의하여 Lipshitz이기도 하며, 그러므로 연속함수이다. 좀 더 구체적으로는 이런 뜻이다.
xn→∥⋅∥x⇒Txn→∥⋅∥Tx
Fixed point
점이나 벡터 x∈X가 연산자 T에 대하여 Tx=x를 만족한다면 이를 fixed point라 한다.
Banach Fixed Point Theorem
X가 완전한 normed vector space라고 하자. 그리고 이 X는 norm ∥⋅∥와 γ-contraction mapping인 T:X→X를 갖는다면,
-
T는 유일한 고정점 x∈X:∃!x∗∈X s.t. Tx∗=x∗를 갖는다.
-
∀x0∈X에 대해, 수열 xn+1=Txn은 다음 경향을 따라 x∗로 수렴한다.
∥xn−x∗∥≤γn∥x0−x∗∥
따라서 n→∞lim∥xn−x∗∥≤n→∞lim(γn∥x0−x∗∥)=0 이 성립한다.
Bellman Operators
The Bellman Optimality Operator
Bellman Optimality Operator TV∗
MDP M=⟨S,A,p,r,γ⟩이 주어졌을 때, V≡VS를 S에 대한 유계 실수 함수들의 공간이라고 하자.
이때 우리는 각각에 대하여 다음과 같이 Bellman Optimality Operator TV∗:V→V를 정의할 수 있다.
(TV∗f)(s)=amax[r(s,a)+γs′∑p(s′∣a,s)f(s′)],∀f∈V
일반적으로는 index V를 떼어버리고 간단히 T∗=TV∗로 쓴다.
Properties of the Bellman Operator T∗
-
유일한 고정점 v∗를 갖는다.
-
T∗는 ∥⋅∥∞에 대하여 γ-contraction이다.
∥T∗v−T∗u∥∞≤γ∥v−u∥∞,∀u,v∈V
-
T∗는 단조성을 갖는다.
∀u,v∈V s.t. u≤v⇒T∗u≤T∗v
Value Iteration through the lens of the Bellman Operator
이 Bellman Operator를 사용하면 훨씬 간단하게 VI를 나타낼 수 있다.
- v0로 시작한다.
- 값을 다음 식을 통해 업데이트한다. vk+1=T∗vk
여기에서 k→∞,vk→∥⋅∥∞v∗를 증명할 수 있다.
간단히 바나흐 고정점 정리를 적용하기만 하면 된다.
∥vk−v∗∥∞=∥T∗vk−1−v∗∥∞=∥T∗vk−1−T∗v∗∥∞≤γ∥vk−1−v∗∥∞≤γk∥v0−v∗∥∞
The Bellman Expectation Operator
Bellman Expectation Operator TVπ
MDP M=⟨S,A,p,r,γ⟩이 주어졌을 때, V≡VS를 S에 대한 유계 실수 함수들의 공간이라고 하자.
이때 우리는 임의의 정책 π:S×A→[0,1]에 대하여 다음과 같이 Bellman Expectation Operator TVπ:V→V를 정의할 수 있다.
(TVπf)(s)=a∑π(s,a)[r(s,a)+γs′∑p(s′∣a,s)f(s′)],∀f∈V
Properties of the Bellman Operator Tπ
-
유일한 고정점 vπ를 갖는다.
Tπvπ=vπ
-
Tπ는 ∥⋅∥∞에 대하여 γ-contraction이다.
∥Tπv−Tπu∥∞≤γ∥v−u∥∞,∀u,v∈V
-
Tπ는 단조성을 갖는다.
∀u,v∈V s.t. u≤v⇒Tπu≤Tπv
Policy Evaluation
- v0로 시작한다.
- 값을 다음 식을 통해 업데이트한다. vk+1=Tπvk
여기에서 위에서와 같은 방법으로 k→∞,vk→∥⋅∥∞vπ를 증명할 수 있다.
Similarly for qπ:S×A→R
Bellman Expectation Operator TQπ
MDP M=⟨S,A,p,r,γ⟩이 주어졌을 때, Q≡QS,A를 S×A에 대한 유계 실수 함수들의 공간이라고 하자.
이때 우리는 임의의 정책 π:S×A→[0,1]에 대하여 다음과 같이 Bellman Expectation Operator TQπ:Q→Q를 정의할 수 있다.
(TQπf)(s)=r(s,a)+γs′∑p(s′∣a,s)a′∈A∑π(a′∣s′)f(s′,a′),∀f∈Q
이 연산자 또한 유일한 고정점을 가지며, Tπ와 같이 γ-contraction과 단조성을 갖는다.
Similarly for q∗:S×A→R
Bellman Optimality Operator TQ∗
MDP M=⟨S,A,p,r,γ⟩이 주어졌을 때, Q≡QS,A를 S×A에 대한 유계 실수 함수들의 공간이라고 하자.
이때 우리는 다음과 같이 Bellman Optimality Operator TQ∗:Q→Q를 정의할 수 있다.
(TQ∗f)(s)=r(s,a)+γs′∑p(s′∣a,s)a′∈Amaxf(s′,a′),∀f∈Q
이 연산자도 유일한 고정점을 가지며, T∗와 같이 γ-contraction과 단조성을 갖는다.
Approximate Dynamic Programming
지금까지 우리는 MDP에 대한 완벽한 지식과, value function에 대한 완벽한 표현을 갖고 있다고 가정했었다.
그러나 실제로는 아닌 경우가 훨씬 빈번하다.
- 우리는 MDP를 알 수가 없다.
- 우리는 value function을 각 업데이트마다 완벽하게 알 수가 없다.
따라서 여기에서 우리의 목표는 위 환경 속에서 최적과 근접한 정책 π를 찾는 것이 될 것이다.
Approximate Value Iteration
Approximate Value Iteration은 Approximation 연산자 A를 도입하여 업데이트 함수를 다음과 같이 나타낸다.
vk+1=AT∗vk
그러면 여기에서도 k→∞,vk→∥⋅∥∞v∗가 성립할까?
일반적으로는 아니다.
ADP: Approximating the value function
θ∈Rm에 대해 function approximater vθ(s)를 사용한다고 하자.
이때 k 스텝에 대한 value function은 vk=vθk가 될 것이다.
물론 여기서도 마치 MDP를 알고있던 것처럼 vθk+1를 구하기 위해같은 방식으로 dynamic programming을 사용할 것이다.
T∗vk(s)=amaxE[Rt+1+γvk(St+1)∣St=s]
그러나 여기에서는 θk+1을 vθk+1≈T∗vk(s)가 되도록 맞춰나갈 것이다.
θk+1=θk+1argmins∑(vθk+1(s)−T∗vk(s))2
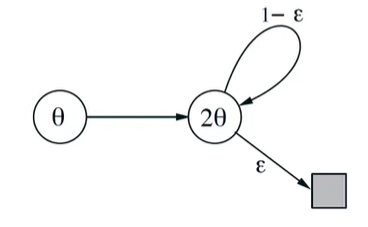
이 방법은 위와 같은 문제에서 충분히 발산할 수 있다.
그러나 희망이 없는 편은 아니다.
- 이 알고리즘의 Sample 버전에서는 웬만한 환경에서 수렴할 수 있다.
- 심지어 function approximation에서도 발산의 이론적 위험은 실제로는 굉장히 드물게 발생한다.

