오늘은 AI를 사용해서 얼굴을 인식해 나이예측을 진행해볼건데요.
동양인과 서양인은 얼굴에 있어서 eye hole이나 골격같이 차이가 존재합니다.
하지만 대부분의 얼굴나이예측 AI들은 서양인들의 데이터셋이 치우쳐서 학습시켰기 때문에 동양인에 대해서는 정확하지 않을것 이라고 판단했습니다.
본 프로젝트는 동양인의 사진만 있는 얼굴 데이터셋을 학습하여 예측정확도를 높이는것을 목표로 하였습니다.
환경을 colab환경에서 진행하였습니다.
처음 이미지를 동기화 시킬때는 불편한 점들이 있지만 api들의 버전을 맞추는등의 신경을 덜써서 되서 편하더라구요.
데이터셋은 밑의 링크에서 받아 보실수 있습니다.
https://github.com/JingchunCheng/All-Age-Faces-Dataset#all-age-faces-dataset
안에 데이터중 변형이미지를 제외한 원본이미지만을 사용하였습니다.
데이터 개요입니다.

처음엔 일반적인 classification으로 진행하였는데 정확도가 잘 나오지 않아서 정확도 저하시킬 가능서이 있는 몇가지와 해결방법을을 생각해봤습니다.
1.데이터 불균형
해결방안 : dataloader의 sampler인자를 이용해서 극복시도
2.데이터 부족
해결방안 : 좌우변환 augmentation을 이용해서 극복시도
3.모델이 과도하게 깊어서 overfitting 유도
해결방안 : 사용모델을 resnet50->resnet18로 바꾸어 극복시도
4.예측범위 부적합
해결방안 : 나이를 생애주기를 참조하여 차별적으로 범주화시켜서 극복시도
5.배경 노이즈가 학습방해
해결방안 : 얼굴위치 인식모델을 활용하여 극복시도
본격적으로 코드내용을 살펴보겠습니다.
from google.colab import drive
drive.mount('/content/drive')#드라이브 마운트
import os
import torch
import torchvision
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') #GPU 할당
print(device)
from PIL import Image
import glob
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from tqdm import tqdm
from torch.optim import optimizer
from torchvision import transforms
from torchvision import models
from torch.utils.data import Dataset, DataLoader
import cv2
import matplotlib.pyplot as plt
from IPython.display import Image,display코드에 필요한 라이브러리들을 불러줍니다
!pip install face-recognition
import face_recognition as fr배경노이즈를 제거하기 위한 얼굴위치인식 모델을 다운 후 불러줍니다.
CFG = {
'IMG_SIZE':128, #이미지 사이즈128
'EPOCHS':100, #에포크
'BATCH_SIZE':16, #배치사이즈
'SEED':1, #시드
}나중에 사용할 하이퍼파라마터들을 미리 설정해 줍니다
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(CFG['SEED']) #시드고정 함수 선언후 시드고정프로젝트 진행할때마다 결과가 바뀌지 않도록 여러 시드들을 고정하는 함수를 선언후 시드를 고정해줍니다.
train_path=sorted(glob.glob("/content/drive/MyDrive/Deepruning_framework/datasets/All-Age-Faces Dataset/original images/*.jpg")) #파일명으로 정렬후 list로 경로 가져오기기이미지들이 있는 경로를 glob을 사용해서 불러줍니다.
각 이미지들의 각 경로가 정렬후 list안에 들어갑니다.
코드를 활용하실 때는 각자 경로에 맞춰서 사용하시면 됩니다.
print(len(train_path))#총 데이터 갯수데이터 갯수를 확인하니 총13322개 있네요
train_transform = torchvision.transforms.Compose([
transforms.Resize([CFG['IMG_SIZE'], CFG['IMG_SIZE']]),#각 이미지 같은 크기로 resize
transforms.ToTensor(),#이미지를 텐서로 변환
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))#평균과 표준편차를 0.5로 정규화
])
test_transform = torchvision.transforms.Compose([
transforms.Resize([CFG['IMG_SIZE'], CFG['IMG_SIZE']]),#각 이미지 같은 크기로 resize
transforms.ToTensor(),#이미지를 텐서로 변환
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))#평균과 표준편차를 0.5로 정규화
])
Horizontal_transform=torchvision.transforms.Compose([
transforms.Resize([CFG['IMG_SIZE'], CFG['IMG_SIZE']]),#각 이미지 같은 크기로 resize
transforms.RandomHorizontalFlip(1.0),# Horizontal = 좌우반전
transforms.ToTensor(),#이미지를 텐서로 변환
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))#평균과 표준편차를 0.5로 정규화
])추후 custom dataset을 만들때 사용할 transform들을 정의해줍니다.
augmentation을 위한 좌우반전transform도 정의해 주었습니다.
train_path[0] #첫번째 경로의 값 확인/content/drive/MyDrive/Deepruning_framework/datasets/All-Age-Faces Dataset/original images/00000A02.jpg
경로도 잘 들어있네요.
img=cv2.imread('/content/drive/MyDrive/Deepruning_framework/datasets/All-Age-Faces Dataset/original images/06961A64.jpg') #85번째 경로의 이미지 불러오기
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB) #pyplot에서 보기위해서 BGR을 RGB로 변환
plt.imshow(img)
plt.show() #pyplot으로 보기기경로에 있는 사진을 하나 뽑아서 시각화도 해주었습니다.
remomve_list=[]
for i in range(13322):
img=cv2.imread(train_path[i])
if (img[0][0][0]==img[0][0][1]==img[0][0][2] and img[5][5][0]==img[5][5][1]==img[5][5][2] and img[15][15][0]==img[15][15][1]==img[15][15][2] and img[35][35][0]==img[35][35][1]==img[35][35][2]): #특정 픽셀값들의 RGB값이 같을시 흑백사진이라고 판단
remomve_list.append(i) #흑백사진의 인덱스를 리스트에 추가
if i%100==0:
print(i)
print(remomve_list)저희 데이터셋에서는 흑백사진도 일부 들어있어서 흑백사진을 판별하기위한 알고리즘입니다.
판별법은 특정 픽셀들의 rgb값이 같을시 그 train_path의 인덱스를 추출하는 형식입니다
remove_idx=[2, 85, 86, 112, 135, 141.......]
#위의 셀에서 추출한 인덱스 대입
print("삭제하기전 2번째 인덱스 값",train_path[2])
for idx in sorted(remove_idx, reverse = True):
del train_path[idx] #인덱스값으로 경로중 일부 제거
print(len(train_path))
print("삭제한 후 2번째 인덱스 값",train_path[2])앞서 확인한 인덱스 값들로 원래 train_path에서의 요소들을 제거해줍니다.
삭제하기전 2번째 인덱스 값 /content/drive/MyDrive/Deepruning_framework/datasets/All-Age-Faces Dataset/original images/00002A02.jpg
12368
삭제한 후 2번째 인덱스 값 /content/drive/MyDrive/Deepruning_framework/datasets/All-Age-Faces Dataset/original images/00003A02.jpg
프린트 값은 위와같이 확인해보니 잘 제거되었고 총 데이터는 13322개에서12368개로 약 1000개 제거되었네요.
face_list=[]
image_list=[]
num=0
i=0
non_recognition_idx=[]
for person in train_path:
image =fr.load_image_file(person)#넘파이로 이미지 불러들임임
encodings = fr.face_encodings(image)
if len(encodings) > 0:
biden_encoding = encodings[0]
top,right,bottom,left = fr.face_locations(image)[0]
face_image = image[top:bottom,left:right]
face_list.append(face_image)
else:
non_recognition_idx.append(i)
num=num+1
i=i+1
if i%100==0:
print(i)
print("얼굴 인식한 이미지수 : ",len(train_path)-num)
print(non_recognition_idx)
for idx in sorted(non_recognition_idx, reverse = True):
del train_path[idx] #인덱스값으로 경로중 일부 제거
print(len(train_path))위의 코드는 아까 얼굴위치를 확인하는 face_recognition api를 사용하여서 얼굴위치의 상화좌우 픽셀위치를 받아서 기존 이미지의 그 좌표값으로 자른후 face_list에 저장해주는 코드입니다.
또 얼굴을 인식하지 못한 이미지는 그 인덱스를 저장하여서 기존에 path에서 그 인덱스를 활용하여 제거해줍니다.
얼굴 인식한 이미지수는 12124 개로12368개에서 소폭 줄었네요
file_name = []
gender_info=[]
for id in train_path:
if id.count("A") == 3:
name = id.split('A')[3]
name=name.split('.')[0]
file_name.append(name) #파일명의 3번째 A와 .사이의 나이정보를 label로 설정
gender=id.split('/')[8]
gender=gender.split('A')[0]
gender_info.append(gender)#gender id저장장
label_list=list(map(int, file_name)) #str형태를 int로 변경
gender_id=list(map(int, gender_info))#str형태를 int로 변경
print(label_list)
print(len(label_list))
train_y=label_listex) /content/drive/MyDrive/Deepruning_framework/datasets/All-Age-Faces Dataset/original images/00003A02.jpg와 같이 파일 경로가 이루어져 있습니다.
위의 코드는 시각화를 위해 파일의 경로의 /00003A02.jpg에서 나이정보인 A와 .사이의 나이정보와 /와 A사이의 성별정보를 받아서 int 형식으로 바꾼후 list안에 저장해 주는 코드입니다.
age_label=[]
for i in range(2,81):
age_label.append(i)나이 시각화에서 xlabel을 위한 list입니다
num_age=[]
from collections import Counter
result = Counter(train_y)
print(result)
for key in result:
print(key, result[key])
for i in range(2,81):
num_age.append(result[i])
print(num_age)collections의 Counter 라이브러리를 사용하여서 pandas의 value_counts와 유사하게 list안의 값이 각 몇개있는지 dictionary형태로 볼 수 있습니다.
num_gender=[]
male=0
female=0
for value in gender_id:
if value<7381:
female+=1
else:
male+=1
num_gender.append(male)
num_gender.append(female)
print(num_gender)앞의 파일에서 추출한 gender정보를 이용하여서 7381 미만이면 여성 그 이상이면 남성으로 구분 후 그 수를 저장해 줍니다.
plt.figure()
# 각 x축 데이터 지점에 y축 데이터의 길이의 막대를 그린다.
plt.bar(["male","female"], num_gender) #x축 y축
plt.show()
plt.figure()
# 각 x축 데이터 지점에 y축 데이터의 길이의 막대를 그린다.
plt.bar(age_label, num_age) #x축 y축
plt.show()위에서 추출한 정보들을 이용하여서 막대 그래프로 시각화 해주었습니다.
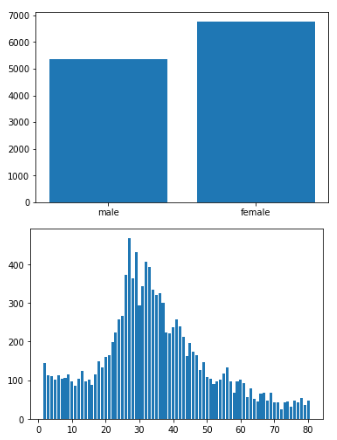
남,여 데이터는 불균형이 심하지 않으나 나이별 데이터는 20,30대 데이터에 편향된 데이터 불균형이 심하네요.
train_y=[]
for i in range(len(label_list)): #정확도 향상을 위해 나이를 생애주기별 요약
if label_list[i]<15:
train_y.append(0)
elif label_list[i]<30:
train_y.append(1)
elif label_list[i]<50:
train_y.append(2)
else:
train_y.append(3)
print(train_y)
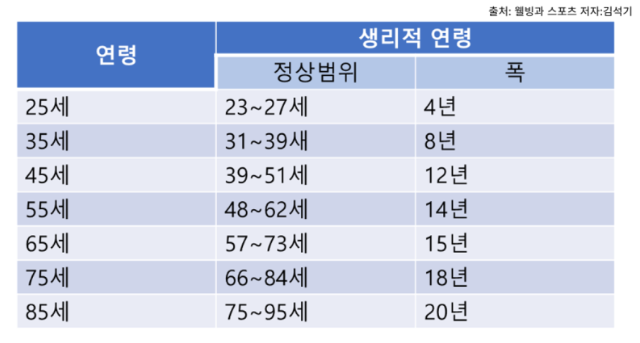
print(len(train_y))저는 나이를 classification으로 구분지을 생각이기 때문에 더 많은 나이일수록 더 넓은 범위의 특정 나이로 잘라서 범주화 하였습니다.
갈수록 범위가 더 넓은 이유는 아래의 자료를 참고하였을때 실제 나이가 많으면 많을수록 생리적 연령의 정상폭이 넓기 때문에 얼굴에 나타내는 노화의 정도도 유사하다 생각해 반영하였습니다.
num_label=[]
from collections import Counter
result = Counter(train_y)
print(result)
for key in result:
print(key, result[key])
for i in range(0,4):
num_label.append(result[i])
print(num_label)plt.bar(["minor","youth","middle-aged","older people"], num_label) #x축 y축
plt.show()범주화시킨 데이터의 수도 시각화 해서 확인했습니다.
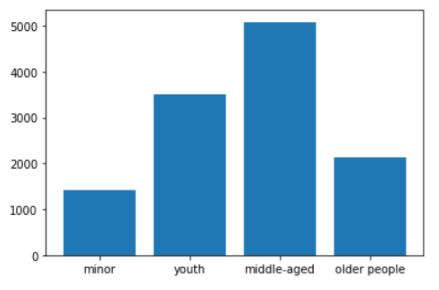
역시 데이터 불균형이 있네요
len(face_list)*0.8 #총 데이터수 갯수*0.8 파악validation과 train데이터의 split을 0.8비율로 하기 위해서 확인해 줍니다.
9699.2로 나오네요
import random
random.Random(19991006).shuffle(face_list) #시드 고정후 셔플
random.Random(19991006).shuffle(train_path) #시드 고정후 셔플
random.Random(19991006).shuffle(train_y) #시드 고정후 셔플
train_img_list=face_list[:9699] #0.8비율로 trainset과 validationset으로 스플릿
train_label_list=train_y[:9699]
valid_img_list=face_list[9699:]
valid_label_list=train_y[9699:]위와 같이 시드를 고정시킨후에 shuffle하면 똑같이 섞이게 되서 독립변수와 종속변수가 어긋나는것을 막을 우 있습니다.
shuffle시킨 후 위에서 확인한 9699로 슬라이싱하여 split해줍니다
plt.imshow(valid_img_list[1])
plt.show()
plt.imshow(valid_img_list[2])
plt.show()잘 되어있는지 확인해 보았습니다.
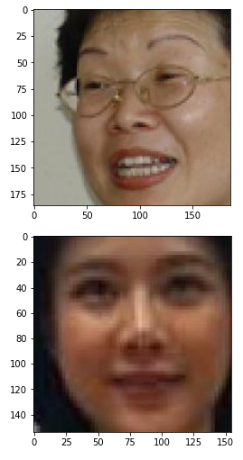
face_recognition을 한번 거친 데이터이기 때문에 얼굴사진만 잘려진채로 잘 나왔네요.
def make_weights(labels, nclasses):
labels = np.array(labels)
weight_arr = np.zeros_like(labels)
_, counts = np.unique(labels, return_counts=True)
for cls in range(nclasses):
weight_arr = np.where(labels == cls, 1/counts[cls], weight_arr)
# 각 클래스의의 인덱스를 산출하여 해당 클래스 개수의 역수를 확률로 할당한다.
# 이를 통해 각 클래스의 전체 가중치를 동일하게 한다.
return weight_arrweights = make_weights(train_label_list, 4)
weights = torch.DoubleTensor(weights)
print(weights)
print(weights.shape)
weights1 = make_weights(valid_label_list, 4)
weights1 = torch.DoubleTensor(weights1)
print(weights1)
print(weights1.shape)
각 weights의 모든 가중치의 합은 1입니다.
sampler = torch.utils.data.sampler.WeightedRandomSampler(weights, len(weights))
sampler1 = torch.utils.data.sampler.WeightedRandomSampler(weights1, len(weights1))위의 세 코드는 데이터 불균형을 해결하기 위한 sampler를 정의해주는 코드입니다.
각 클래스별로 데이터수의 역수에 비례하게 가중치를 부여해서 dataloader의 sampler인자에 설정시 배치 안에 각 클래스가 일정비율로 들어가게 해줍니다.
ex)만약 데이터안에 0이90개 1이 10개고 batchsize가 10이라면 평균적으로 batch안에 0이 9개 1이1개 있다면 sampler를 사용하여 0이5개 1이5개로 들어갈 수 있게 합니다.
class ageDataset(Dataset):
def __init__(self, image,label, train=True, transform=None):
self.transform = transform
self.img_list = image
self.label_list=label
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
label = self.label_list[idx]
img = Image.fromarray(np.uint8(self.img_list[idx])).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label dataloader에 사용하기 위해 custom dataset을 정의해 주었습니다.
특이한 점으로는 input으로 일반적으로 많이 사용하는 경로가 아니라 실제 이미지가 list 형식으로 들어가기 때문에 PIL형식으로 저장하기 위해서 먼저 numpy로 변환해준 후 PIL로 불러주었습니다.
original_dataset = ageDataset(image=train_img_list,label=train_label_list, train=True, transform=train_transform) #original dataset 구축
Horizontal_dataset=ageDataset(image=train_img_list,label=train_label_list, train=True, transform=Horizontal_transform) #horizonal dataset 구축
train_dataset=original_dataset+Horizontal_dataset
train_loader = DataLoader(train_dataset, batch_size = CFG['BATCH_SIZE'], num_workers=2,sampler=sampler) #dataloadet 대입
valid_dataset= ageDataset(image=valid_img_list,label=valid_label_list, train=False, transform=test_transform) #validation custom dataset 구축
valid_loader = DataLoader(valid_dataset, batch_size = CFG['BATCH_SIZE'], num_workers=2,sampler=sampler1) #dataloadet 대입앞서 split한 데이터로 나누어서 train,valid dataset을 만든 후 dataloader에 sampler,batchsize등등과 더불어 넣어줍니다.
train_dataset은 좌우반전 augmentation도 추가해 주었습니다.
model1=torchvision.models.resnet18(torchvision.models.ResNet18_Weights)
print(model1)model1.fc = nn.Sequential(
nn.Linear(512,512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512,4),
nn.Softmax()
)
model1=model1.to(device)모델은 resnet18모델을 프로젝트의 아웃풋에 맞게 수정후 사용했습니다.
custom 모델도 사용해 보았는데 기존 모델보다 정확도가 낮았습니다.
criterion = torch.nn.CrossEntropyLoss() #loss function으로 crossentropy 설정
optimizer=optim.Adam(model1.parameters(),lr=1e-4,weight_decay=1e-4) #최적화 함수로 Adam사용
scheduler = Noneloss function으로는 multioutput classification이기 때문에 crossentropy 최적화 함수는 adam을 사용했습니다.
def train(model, optimizer, train_loader,vali_loader, scheduler, device): #학습 함수정의
model.to(device) #모델에 디바이스 할당
n = len(train_loader) #데이터 갯수 파악악
#Loss Function 정의
#criterion = nn.CrossEntropyLoss().to(device)
best_acc = 0
vali_acc=0
best_apoch=0
val_loss=[]
tr_loss=[]
for epoch in range(1,CFG["EPOCHS"]+1): #에포크 설정
model.train() #모델 학습
running_loss = 0.0
for img, label in tqdm(iter(train_loader)):
img, label = img.to(device), label.to(device) #배치 데이터
optimizer.zero_grad() #배치마다 optimizer 초기화
# Data -> Model -> Output
logit = model(img) #예측값 산출
loss = criterion(logit, label) #손실함수 계산
# 역전파
loss.backward() #손실함수 기준 역전파
optimizer.step() #가중치 최적화
running_loss += loss.item()
train_loss=running_loss / len(train_loader)
print('[%d] Train loss: %.10f' %(epoch, running_loss / len(train_loader)))
tr_loss.append(running_loss / len(train_loader))
if scheduler is not None:
scheduler.step()
#Validation set 평가
model.eval() #evaluation 과정에서 사용하지 않아야 하는 layer들을 알아서 off 시키도록 하는 함수
vali_loss = 0.0
correct = 0
with torch.no_grad(): #파라미터 업데이트 안하기 때문에 no_grad 사용
for img, label in tqdm(iter(vali_loader)):
img, label = img.to(device), label.to(device)
logit = model(img)
vali_loss += criterion(logit, label)
pred = logit.argmax(dim=1, keepdim=True) #4개의 class중 가장 값이 높은 것을 예측 label로 추출
correct += pred.eq(label.view_as(pred)).sum().item() #예측값과 실제값이 맞으면 1 아니면 0으로 합산
vali_acc = 100 * correct / len(vali_loader.dataset)
print('Vail set: Loss: {:.4f}, Accuracy: {}/{} ( {:.1f}%)\n'.format(vali_loss / len(vali_loader), correct, len(vali_loader.dataset), 100 * correct / len(vali_loader.dataset)))
val_loss.append(vali_loss / len(vali_loader))
if best_acc < vali_acc: #early stopping기법 validation의 정확도가 최고치 갱신시 모델 저장장
best_acc = vali_acc
best_epoch=epoch
torch.save(model.state_dict(), '/content/drive/MyDrive/Deepruning_framework/datasets/All-Age-Faces Dataset/best_model.pth') #이 디렉토리에 best_model.pth을 저장
print('Model Saved.')
return best_acc,tr_loss,val_loss학습파트 입니다.
특이점으로는 validation에서 argmax로 제일 높은 값의 인덱스를 뽑아 accuracy를 측정하였고 validation의 정확도가 가장 높을때 model을 저장해 주었습니다.
best_acc,tr_loss,val_loss=train(model1, optimizer, train_loader,valid_loader, scheduler, device) #학습
for i in range(len(val_loss)):
valid_loss.append(val_loss[i].tolist())
print("best_accuracy : ",best_acc)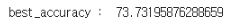
제일 높을때의 정확도는 약74퍼 정도입니다. 아무래도 나이 경계선에 있는 나이층이 정확도 저하의 원인인듯 싶네요.
validation_loss가 데이터 타입 확인결과 torch로 되어 있어서 밑의 시각화를 위해 list형식으로 만들어 주었습니다.
plt.figure(1,figsize=(10,6)) #plt 사이즈 설정
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(tr_loss[:],c='b',label='train_loss')
plt.plot(valid_loss[:],c='r',label='test_loss')
plt.legend(loc='best')train과 validation loss를 시각화 하였습니다.
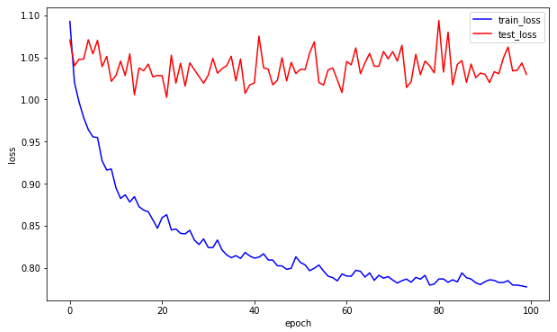
train loss는 잘 학습되어서 떨어지는 추세를 보이지만
validation loss가 train_loss에 비해서 overfitting되는 경향이 있는데 아무래도 데이터 부족이 문제인것 같습니다.
다른 자료를 살펴보니까 데이터셋을 3개를 쓰는 경우도 있더라구요.
하지만 저의 초기 컨셉인 동양인 데이터셋을 이용한 학습에는 부합하지 않았고 추가적인 나이가 라벨링된 동양인 데이터셋을 구할수 없었기 때문에 그대로 진행하였습니다.
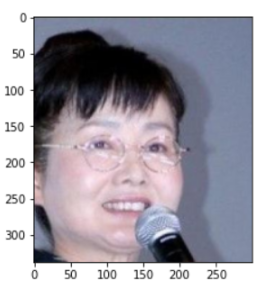
person=glob.glob('/content/drive/MyDrive/Deepruning_framework/datasets/3.jpg')
img=cv2.imread('/content/drive/MyDrive/Deepruning_framework/datasets/3.jpg')
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB) #pyplot에서 보기위해서 BGR을 RGB로 변환
plt.imshow(img)
plt.show()AI모델의 테스트를 위해서 제 사진을 가져와서 나이 예측을 진행해 줬습니다.
num=0
i=0
non_recognition_idx=[]
face_image=[]
image =fr.load_image_file(person[0])#넘파이로 이미지 불러들임임
encodings = fr.face_encodings(image)
if len(encodings) > 0:
biden_encoding = encodings[0]
top,right,bottom,left = fr.face_locations(image)[0]
face_image1 = image[top:bottom,left:right]
face_image.append(face_image1)
else:
non_recognition_idx.append(i)
num=num+1
i=i+1
if num==1:
print("얼굴이 잘 인식되자 않습니다 다른환경에서 사진찍거나 다른사진을 사용해보세요")
else:
plt.imshow(face_image[0])
plt.show()위와 같이 face_recognition을 통과시켜 얼굴파트만 딴 다음
test_dataset= ageDataset(image=face_image,label=[0], train=False, transform=test_transform) #validation custom dataset 구축
test_loader = DataLoader(test_dataset, batch_size = CFG['BATCH_SIZE'], num_workers=2) #dataloadet 대입check_point=torch.load('/content/drive/MyDrive/Deepruning_framework/datasets/All-Age-Faces Dataset/best_model.pth')
model=model1
model=model.to(device)
model.load_state_dict(check_point)제일 학습이 잘 되었을때의 model을 가져옵니다.
with torch.no_grad(): #파라미터 업데이트 안하기 때문에 no_grad 사용
for img, label in tqdm(iter(test_loader)):
img, label = img.to(device), label.to(device)
logit = model(img)
pred = logit.argmax(dim=1, keepdim=True)
print(logit)
print(pred)그후 모델 출력값을 받아서
pred=pred.tolist()
logit=logit.tolist()
print(logit)
print(pred)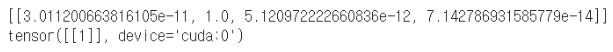
이런 형식으로 나오면
if(pred[0][0]==0):
print("{:.2f}확률로 미성년자입니다.".format(logit[0][pred[0][0]]))
if(pred[0][0]==1):
print("{:.2f}확률로 청년층입니다.".format(logit[0][pred[0][0]]))
if(pred[0][0]==2):
print("{:.2f}확률로 중년층입니다.".format(logit[0][pred[0][0]]))
if(pred[0][0]==3):
print("{:.2f}확률로 노년층자입니다.".format(logit[0][pred[0][0]]))
위와 같이 깔끔하게 정리후 출력값을 받았습니다.
제 사진은 100%로 청년층으로 판별했네요.
긴 글 읽어주셔서 감사합니다~
