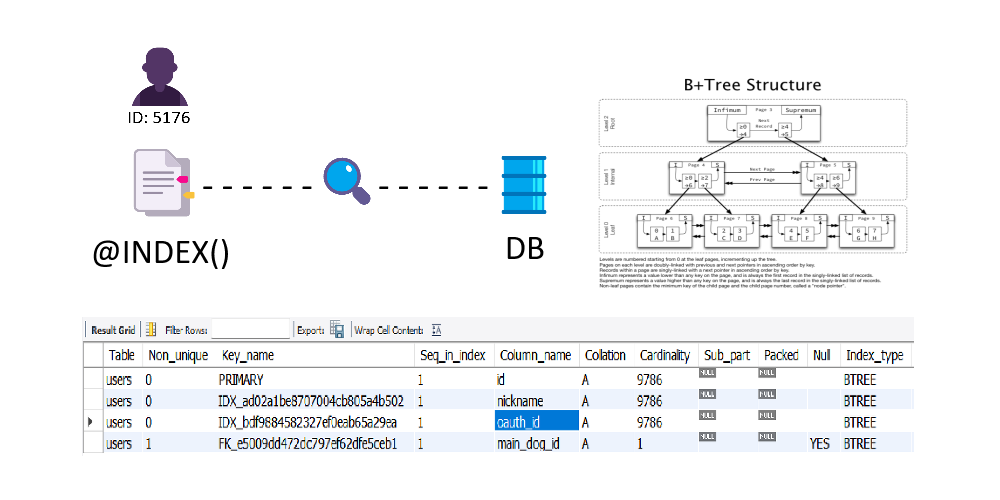
🔍Index 알아보기
Index는 데이터베이스 테이블의 검색 속도를 향상시키기 위해 사용되는 데이터 구조로 특정 column이나 column 집합에 대한 정렬된 참조를 제공하여 데이터를 빠르게 찾을 수 있게 한다.
하지만 Index를 위한 추가 공간이 필요하고, 데이터가 많이 있다면 생성에 많은 시간이 소요될 수 있다.
데이터 검색은 빨라지지만, INSERT, UPDATE, DELETE 작업은 상대적으로 느릴 수 있다. (Index 재배열)
Clustered Index와 Non-Clustered Index
Clustered Index
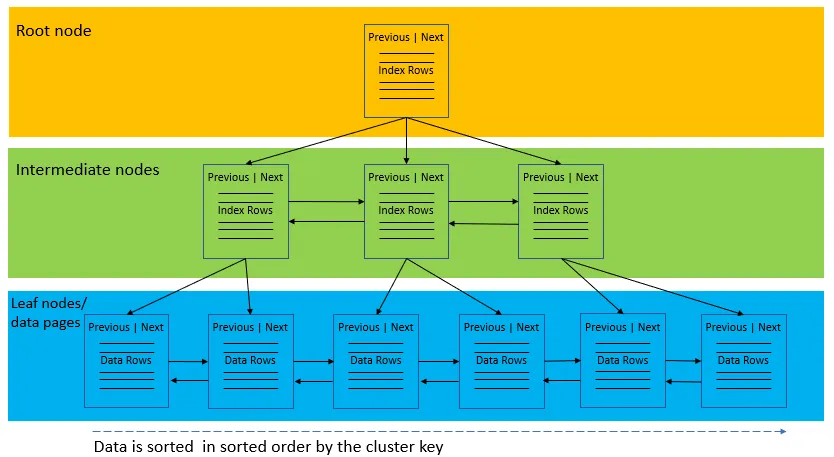
- 테이블당 하나만 존재 가능하다.
- 실제 데이터의 물리적 순서를 결정하며 행 데이터를 포함하는 페이지로 바로 연결된다. (Leaf node = Data page)
- 일반적으로 Primary Key와 동의어이다.
Primary Key가 정의되지 않은 경우,- 첫 번째 UNIQUE index(모든 키 column이 NOT NULL)를 사용한다.
- 적절한 UNIQUE index도 없다면, 'GEN_CLUST_INDEX'라는 숨겨진 index를 생성한다.
- 각 테이블에 Primary Key를 정의할 것이 권장되며 논리적으로 적절한 Primary Key가 없다면 auto-increment column을 추가한다.
Non-Clustered Index (Secondary Index)
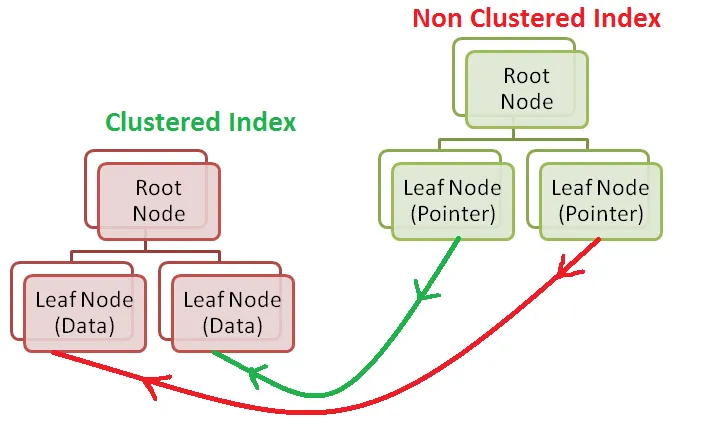
- Clustered Index 외의 Index를 의미한다.
- 테이블당 여러 개 생성 가능하다.
- 실제 데이터와 별도의 구조로 물리적으로 데이터를 정렬하지 않은 상태로 저장된다. (Leaf node = Data page Pointer)
- 검색 속도는 Clustered Index보다 조금 느리지만, 데이터의 INSERT, UPDATE, DELETE 작업은 더 빠르다.
- 여러 컬럼에 대해 생성 가능하여 다양한 쿼리 최적화에 유용하다.
- InnoDB에서 모든 Secondary Index는 해당 레코드의 Primary Key 값을 포함하기 때문에 짧은 Primary Key가 Secondary Index 공간 효율 측면에서 유리하다.
전체 구조 정리
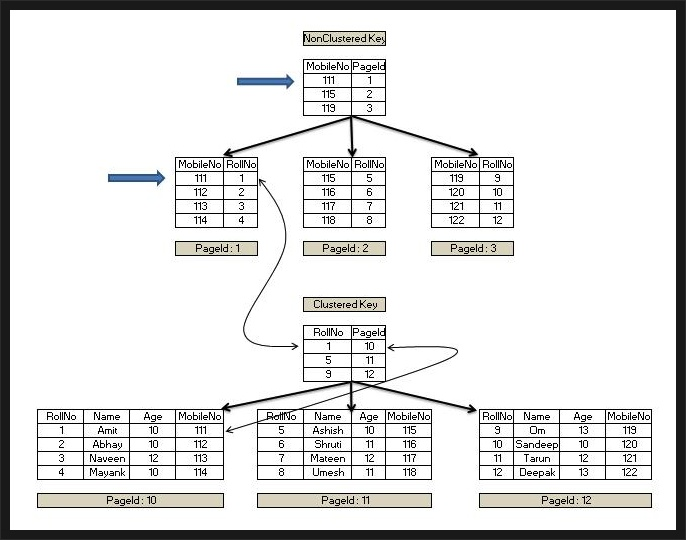
- Clustered Index: index에서 직접 데이터에 접근
- Non-Clustered Index: index → Primary Key → 실제 데이터 순으로 접근
🚀적용해보기
MySQL에서 기본적으로 Clustered Index는 PK(Primary Key)에 적용되므로 Non-Clustered Index를 추가해보자.
프로젝트에서 OAuth로 로그인 후 OAuth 정보를 Users table에 저장한다. oauthId column에 index를 적용해 조회 성능을 향상시켜보자.
- TypeORM을 사용하고 있다. oauthId column은 unique하므로
@Column()또는@Index()decorator에unique: trueoption을 추가하면 된다. - 10만 사용자를 생성해둔 test DB에서 임의로 5176번 사용자로 테스트해보았다.
개선 전
Code
@Entity()
export class Users {
@PrimaryGeneratedColumn()
id: number;
⁝
@Column({ name: 'oauth_id' })
oauthId: string;const { id: userId, oauthRefreshToken } = await this.usersService.findOne({ where: { oauthId } });Analyze
EXPLAIN ANALYZE
SELECT `Users`.`id` AS `Users_id`, `Users`.`nickname` AS `Users_nickname`, `Users`.`email` AS `Users_email`, `Users`.`profile_image_url` AS `Users_profile_image_url`, `Users`.`role` AS `Users_role`, `Users`.`main_dog_id` AS `Users_main_dog_id`, `Users`.`oauth_id` AS `Users_oauth_id`, `Users`.`oauth_access_token` AS `Users_oauth_access_token`, `Users`.`oauth_refresh_token` AS `Users_oauth_refresh_token`, `Users`.`refresh_token` AS `Users_refresh_token`, `Users`.`createdAt` AS `Users_createdAt` FROM `users` `Users` WHERE ((`Users`.`oauth_id` = '5176')) LIMIT 1;-> Limit: 1 row(s) (cost=1051 rows=1) (actual time=3.8..3.8 rows=1 loops=1)
-> Filter: (Users.oauth_id = '5176') (cost=1051 rows=979) (actual time=3.8..3.8 rows=1 loops=1)
-> Table scan on Users (cost=1051 rows=9786) (actual time=0.0252..3.31 rows=5176 loops=1)개선 후
(Index 추가 및 select option으로 가져올 열 명시)
Code
@Entity()
export class Users {
@PrimaryGeneratedColumn()
id: number;
⁝
@Column({ name: 'oauth_id', unique: true })
oauthId: string;SHOW INDEX FROM users;로 Index가 잘 추가된 것을 확인할 수 있다.

const { id: userId, oauthRefreshToken } = await this.usersService.findOne({
where: { oauthId },
select: ['id', 'oauthRefreshToken'],
});Analyze
EXPLAIN ANALYZE
SELECT `Users`.`id` AS `Users_id`, `Users`.`oauth_refresh_token` AS `Users_oauth_refresh_token` FROM `users` `Users` WHERE ((`Users`.`oauth_id` = '5176')) LIMIT 1;-> Limit: 1 row(s) (cost=0..0 rows=1) (actual time=0.00112..0.00121 rows=1 loops=1)
-> Rows fetched before execution (cost=0..0 rows=1) (actual time=99e-6..99e-6 rows=1 loops=1)개선 결과
| 항목 | 개선 전 | 개선 후 | 개선율 |
|---|---|---|---|
| 실행 시간 | 3.8 ms | 0.00121 ms | 99.968% |
| 예상 비용 (cost) | 1051 | 0 | 100% |
| 스캔 행 수 | 5176 rows | 1 row | 99.981% |
- 기존에는 Table scan이 발생하고 있고 많은 열을 조회하고 있어 불필요한 오버헤드가 발생한다.
oauth_id에UNIQUE인덱스 추가로 인덱스를 사용하여 조회하고 불필요한 열 조회를 줄여 필요한 열만 선택한다.- Table scan 대신 인덱스 조회로 인해 query 성능이 대폭 향상된 것을 확인할 수 있다.

이것저것 관심 많은 개발자👩💻