결정 트리(Decision Tree) 와 랜덤 포레스트 (Random Forest)
1. 결정 트리(Decision Tree)란 ?
결정 트리(Decision Tree) 는 '의사결정 규칙'을 'Tree' 자료구조로 표현 한 모델이다. 모델은 데이터에 대해 연속적인 질문을 던져가며 가중치를 보정하고, 끝내 데이터가 어떤 그룹에 속하는지 분류 하거나 어떤 값인지(회귀) 에 대한 결론에 도달한다.
# 필요한 라이브러리 불러오기
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 1. 데이터 준비
iris = load_iris()
X = iris.data
y = iris.target
# 2. 모델 생성 및 학습
dt_clf = DecisionTreeClassifier(max_depth=3, random_state=42)
dt_clf.fit(X, y)
# 3. 학습된 트리 시각화
plt.figure(figsize=(15, 10))
plot_tree(dt_clf,
filled=True, # 노드의 클래스에 맞게 색을 채웁니다.
feature_names=iris.feature_names, # 각 노드가 어떤 특성으로 분기했는지 표시합니다.
class_names=iris.target_names) # 잎 노드의 클래스 이름을 표시합니다.
plt.title("Decision Tree Visualization")
plt.show()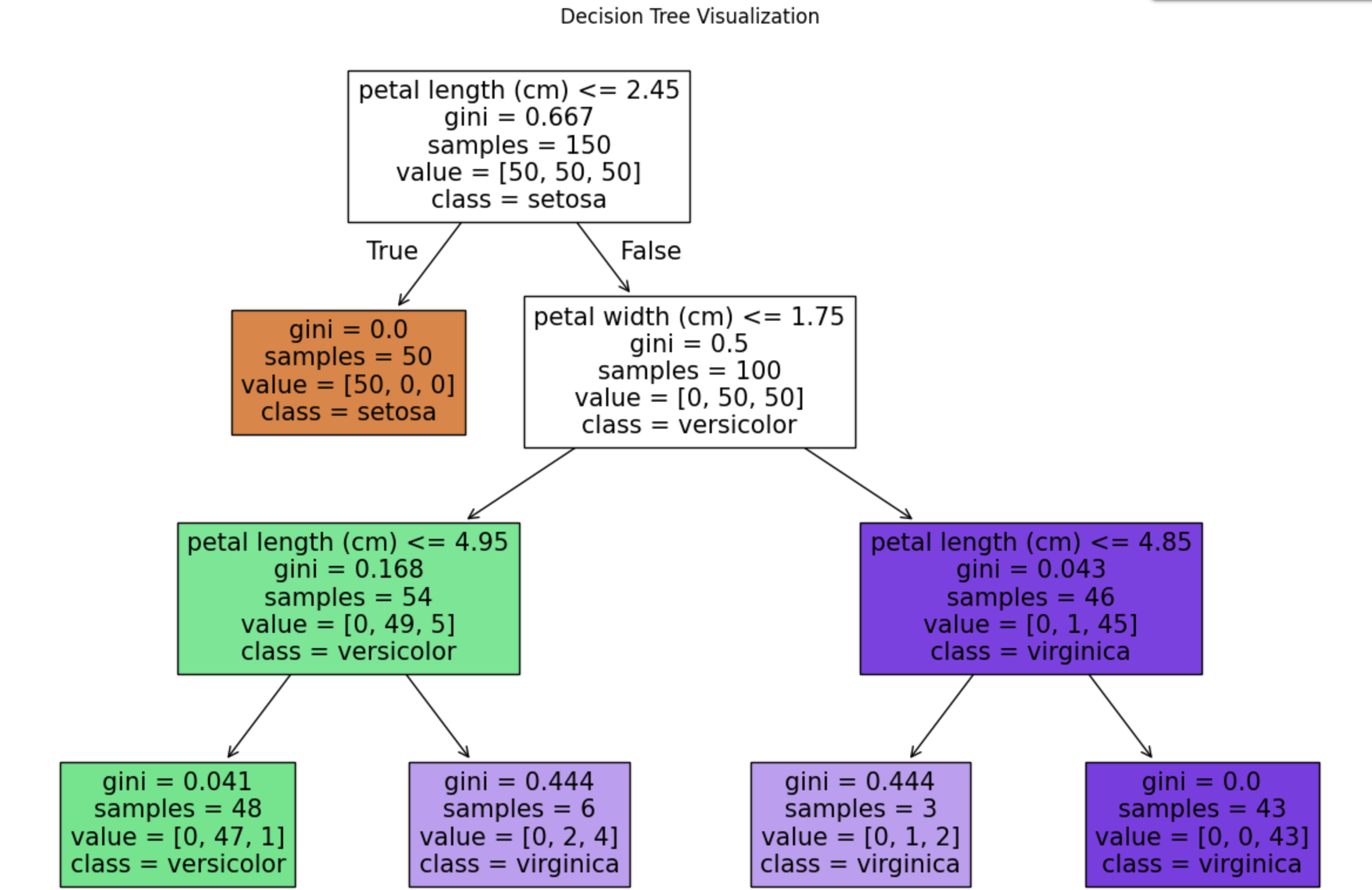
- 위에 트리를 확인해보면, 모델이 어떤 기준을 통해 붗꽃의 품종을 찾아가는지 한눈에 확인할 수 있다.
2. 과적합과 가지치기
결정 트리의 가장 큰 단점은 훈련 데이터에 과하게 최적화되는 과적합(Overfitting) 이 다. 모델이 훈련 데이터의 사소한 노이즈까지 모두 학습하게 되어 새로운 데이터에 대한 예측 성능이 떨어지게 된다.
이를 해결하기 위해 가지치기(Pruning) 개념이 등장했다. 말 그대로 너무 복잡한 트리의 가지를 쳐내어 모델을 단순화 하는 과정이다.
위 코드의 DecisionTreeClassifier의 파라미터들을 조절하여 가지치기를 할 수 있다.
max_depth: 트리의 최대 깊이를 제한한다.min_samples_split: 노드를 나누기 위해 필요한 최소 데이터 수를 지정한다.min_samples_leaf: 마지막 잎 노드가 되기 위해 필요한 최소 데이터 수를 지정한다.
3. 랜덤 포레스트 (Random Forest)
랜덤 포레스트(Random Forest)는 결정 트리의 과적합 문제를 해결하기 위해, 조금씩 다른 여러 개의 결정 트리를 만들어 그 결과를 종합하는 앙상블(Esemble)기법이다.
두가지 핵심적인 '무작위성' 을 통해 다양성을 확보한다.
1. 데이터의 무작위성 (Bagging) : 훈련 데이터에서 무작위로 데이터를 샘플링하여 각. 트리를 학습시킨다.
2. 특성의 무작위성 : 각 트리의 노드를 분할할 때, 전체 특성 중 일부만 무작위로 뽑아 사용한다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 1. 데이터 준비 (훈련/테스트 데이터 분리)
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=42
)
# 2. 모델 생성 및 학습
# n_estimators=100 : 숲을 구성할 나무의 개수를 100개로 지정합니다.
rf_clf = RandomForestClassifier(n_estimators=100, random_state=42)
rf_clf.fit(X_train, y_train)
# 3. 예측 및 성능 평가
y_pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"랜덤 포레스트 모델의 정확도: {accuracy:.4f}")랜덤 포레스트 모델의 정확도: 1.0000다음은 100개의 트리중 첫번째 트리만을 시각화 한 결과이다.
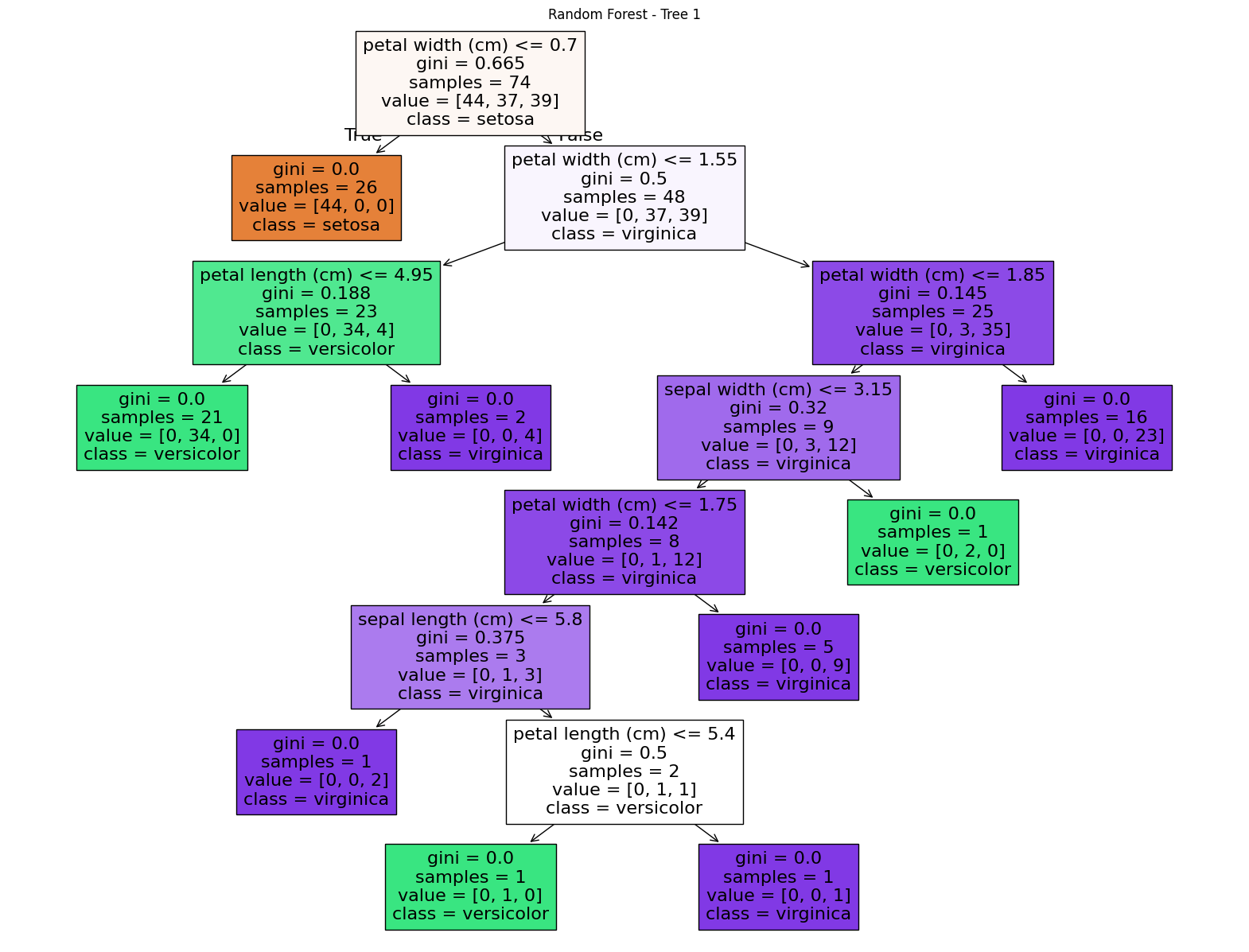
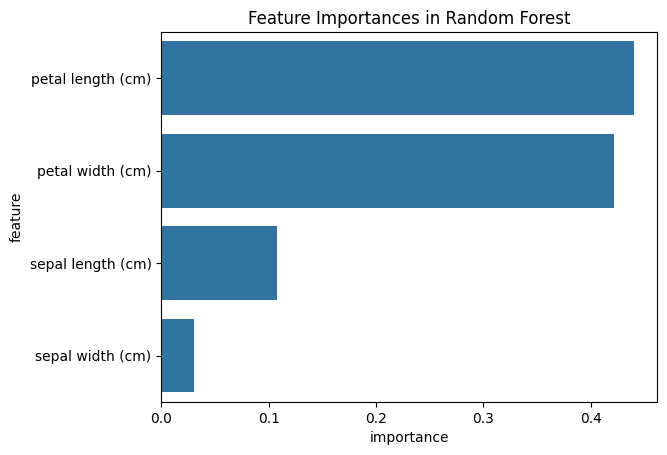
다음은 특성 중요도(Feature Importance)를 시각화 한 결과이다.

Bioinformatics and Data science