
CS231N - Lecture 2 | Image Classification
Image Classification
= A core task in Computer Vision
input image 를 입력받아서 given set of discrete lables 에서 맞는 것에 assign 해준다.
Semantic Gap
Semantic Gap(의미적 차이) : 사람과 컴퓨터의 인식의 차이

- 사람은 직관적으로 사물이 무엇인지 알아낼 수 있지만 컴퓨터는 직관이 없다(그저 숫자일뿐이다).
- 컴퓨터는 픽셀의 색을 표현한 숫자로 된 그리드(격자)를 통해 인식한다.
- 각 픽셀당 0-255 사이의 값을 갖는다.
Challenges
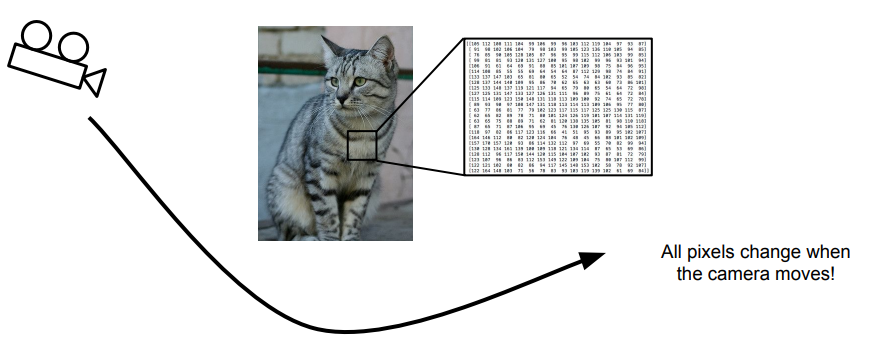
1. Viewpoint variation (시점의 변화)
: 카메라가 움직이면 모든 픽셀들의 값이 바뀐다.
2. Illumination (조명)

3. Deformation (변형)
: 다양한 자세나 형태에 따라 이미지의 분류가 어려울 수 있다.

4. Occlusion (가려짐)

5. Background clutter (배경과 사물이 비슷함)

6. Intraclass variation (다양성)
: 다양한 종류의 Object들을 하나의 label로 분류하기 어려울 수 있다.
ex) 다양한 종의 고양이들

Algortithms should be robust to these different kinds of transformations !!
Image Classifier
no obvious way to hard-code the algorithm for recognizing a cat, or other classes.
def classify_image(image):
# some magic here?
return class_label결국 다음 함수와 같이 input image를 받아서 class label을 반환해주는 함수가 우리가 원하는 함수가 될 것이다.
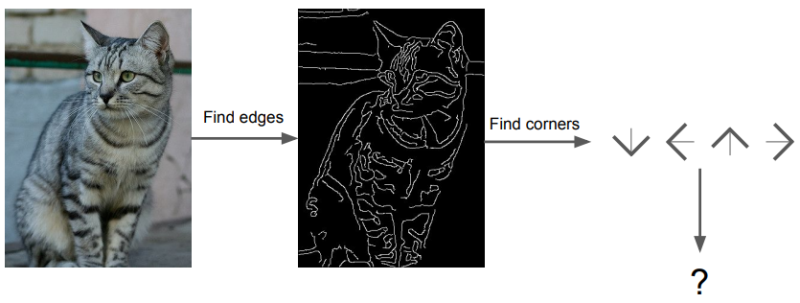
이미지에서 edges를 추출하고 귀모양, 코모양과 같이 고양이에게 필요한 집합들을 하나하나 찾아서 다 있으면 고양이라는 label을 출력하는 방법이 있을 것이다. 하지만, 이와 같은 방법은 변화에 강건하지 않아서 결과값이 잘 나오지 않고, 강아지와 집과 같은 다른 객체들을 인식하려고 할 때 그 클래스에 맞는 집합을 따로 하나하나 만들어야돼서 굉장히 비효율적이다.
Data-Driven Approach (데이터 중심 접근법)
위와 같이 고양이, 강아지 등 특정 객체에 필요한 규칙들을 하나하나 만드는 것이 아니라 엄청나게 방대한 고양이, 강아지, 집 사진들을 컴퓨터에게 제시하고, machine learning classifier을 학습시키는 방법이다.
- Collect a dataset of images and labels
- Use Machine learning to train a classifier
- Evaluate the classifier on new images
Nearest Neighbor Classifier
train : data와 label을 기억한다.
def train(images, labels): # Memorize all data and labels
# Machine Learning!
return modelpredict : 새로운 image를 training image와 비슷한 것을 찾아서 labeling한다.
def predict(model, test_images): # Predict the label if the most similar training image
# Use model to predict labels
return test_labelsimage와 label을 입력 받아 머신러닝을 시키는 train 함수와 train 함수에서 반환된 모델을 가지고 테스트 이미지를 판단하는 predict 함수로 나누어진다.
Example Dataset : CIFAR10

L1 Distance (Manhattan distance)
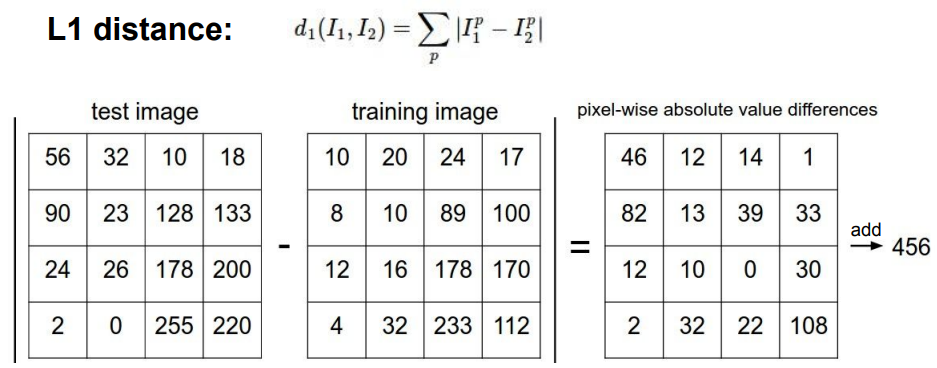
test image와 train image는 각각 같은 사이즈를 갖고, 같은위치의 픽셀값 차이를 구해 단순히 합하게 된다. 이 값이 가장 적은 사진이 비슷한 사진으로 골라지는 것이다. 하지만, 단순히 픽셀값을 비교하는 것으로는 붉은벽돌이랑 붉은지갑이랑 같은 물체로 구분할 수 있는 가능성이 있다.
python code
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
# Memorize training data (just remembers all the training data)
def training(self, X, y):
self.xtr = X # X : matrix (N x D)
self.ytr = y # y : matrix (1 x N)
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in xrange(num_test):
# using the L1 distance
# -> for each test image, find closet train image
distances = np.sum(np.abs(self.xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred - 수행시간 : Train O(1), Predict O(N)
- 보통의 경우 Training이 오래걸리고, Test는 빠르다. 하지만 Nearest Neighbor는 반대이다.
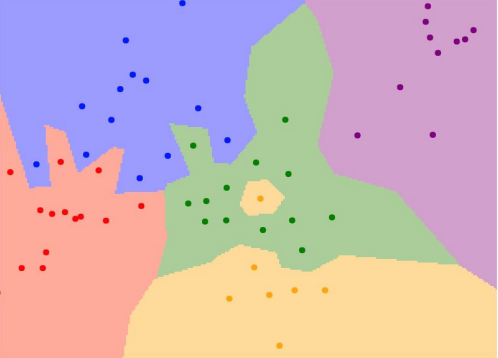
- 점은 학습데이터이고, 점의 색깔은 class label이다.
- 각 좌표가 어떤 학습 데이터와 가장 가까운지를 계산한 후에 그 학습데이터의 label을 반환한다.
- NN 분류기는 space에 따라 데이터를 분류한다.
문제점
- 초록색 label사이에 노란색 label(noise)이 있다.
- 깔끔하게 나누어져있지 않다.
K-Nearest Neighbors
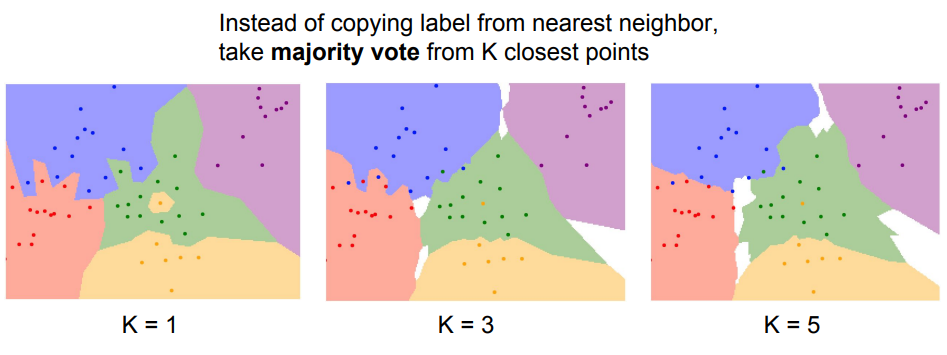
- K-NN방식은 test data와 train data 사이의 거리 (NN방식에서의 픽셀차이값과 같은것) 가 가장 짧은 K개의 train data들을 고르고, 그 중 가장 다수의 class로 결정되는 모델이다.
- K가 커질수록 위의 그림처럼 분류할 때 혼자 튀는 데이터들은 무시해서 train data에서 소수의 오류를 감안하고, test data에서의 성능을 높이게 된다.
Distance metric
데이터간의 거리(distance)란 데이터간의 유사성을 말한다.
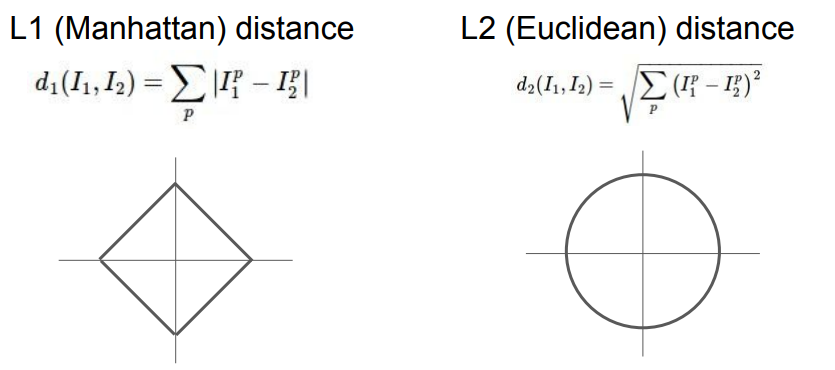
-
L1 Distance
다차원에서 단순히 두 점의 좌표들간의 차이의 절댓값을 더한 것으로 어떤 좌표계를 사용하느냐에 따라 값이 바뀐다. -
L2 Distance
원점을 기준으로 모든 거리가 같기 때문에 좌표계에 따라 값이 바뀌지 않는다.
Q . Where L1 distance might be preferable to using L2 Distance ?
A . Input feature가 개별적인 의미를 가지고 있다면 L1이 좋지만, 일반적인 벡터이고 실질적인 의미를 가지고 있지 않다면 L2가 좋다.
룰루랄라 효니루 - [CS231n] 2강. L1 & L2 distance
Hyperparameters
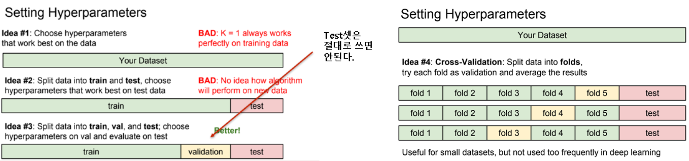
-
train data에서 젤 잘 작동하는 hyperparameter로 결정하는 방식 (K=1이고 검증시에도 학습데이터를 사용)
: K=1의 경우 학습데이터자체는 완벽히 분류하게 되지만, 새로운 데이터로 test해보면 튀는 데이터로 인한 복잡한 분류로 인해 오히려 성능이 떨어지게 된다.
-
train & test data로 나누고, test data에서 최적인 hyperparameter로 결정하는 방식
: 이 역시 새로운 데이터를 만나면 성능이 떨어질 수 있다.
-
가진 데이터를 train, val, test 세개로 나누는 경우
: train data로 알고리즘을 학습하고 validation set으로 최적 hyperparameter를 찾고, test data를 마지막으로 실제 성능을 unseen data에서 확인해본다.
-
Cross-validation (교차검증)
: validation set를 따로 설정하는 것이 의미가 없을정도로 데이터가 부족한 경우, train set를 K개의 fold로 나누어 돌아가면서 validation set 역할을 한다. 이를 K-교차검증이라고 한다.
Dateset이 작다면 사용하지만, 딥러닝은 데이터의 양 자체가 방대하기 때문에 교차검증을 사용하지 않는다.
K-NN 알고리즘을 이미지 분류에 사용하지 않는 이유

- 시간이 오래 걸린다.
- L1/L2 distance가 이미지간의 거리를 구하는 것에 적합하지 않다.
- Curse of dimensionality
- k-nn은 training data를 이용해서 공간을 분할하기 때문에 k-nn이 잘 동작하려면 전체 공간을 조밀하게 커버할만큼의 데이터가 필요하다.
- 즉, 충분한 양의 학습데이터가 필요한데 이 학습데이터는 차원이 증가함에따라 기하급수적으로 증가한다. 1차원에서는 4개의 데이터만 있으면 되지만, 3차원에서는 많은 데이터가 필요하게 된다.
Linear Classification
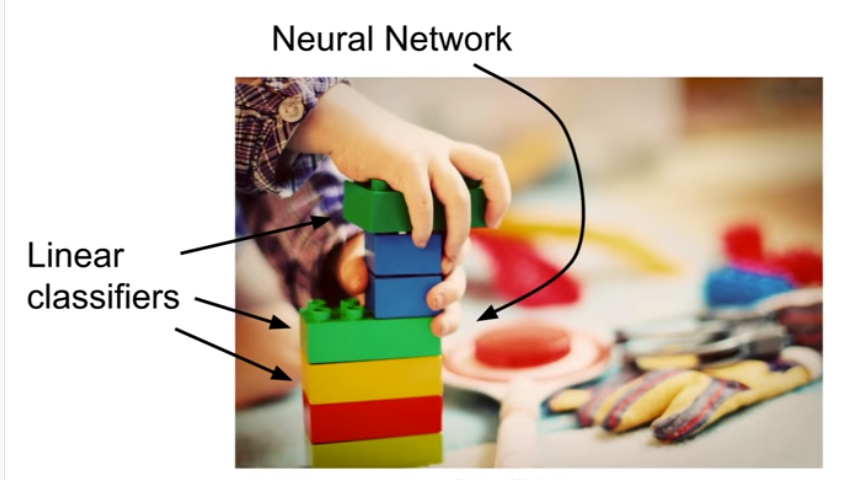
- Neural Network(NN)는 레고 블럭과 같고, Linear classifier은 기본 블럭과 같다.
- 그림과 같이 여러 층을 쌓고, 각 층은 Linear classifier에 의해서 분류과정이 일어나게 된다.
Parametic Approach
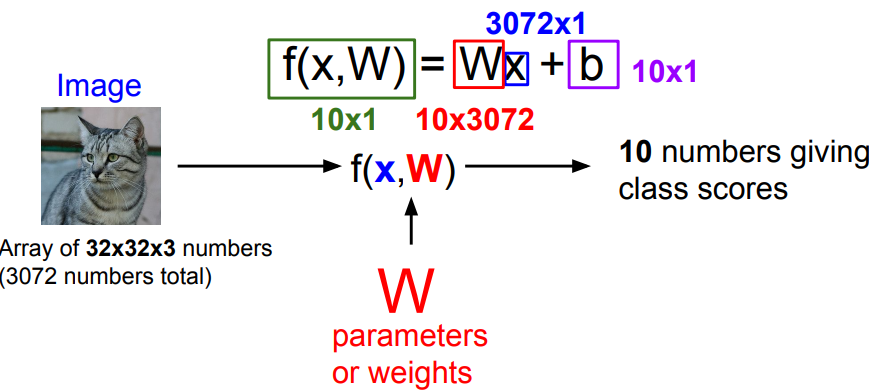
총 개수 가로픽셀수 x 세로픽셀수 x 채널수(컬러면 RGB로 3, 흑백은 1)로 이루어진 데이터들을 행렬계산을 위해 벡터로 쫙 펼치고, 각 클래스를 대변할 수 있는 parameter인 W(가중치, weights)와 b를 설정하여 결괏값을 구해 가장 score가 높은 class로 분류하게 된다. 여기서 사용되는 함수 f(x, W)가 직선의 방정식이라서 linear classifier라고 부른다.
- Score : 이미지의 픽셀값과 가중치 행렬을 내적한 값에 bias term을 더한 것
- 내적 : 클래스간 템플릿의 유사도를 측정하는 것과 유사
- bias : 데이터 독립적으로 각 클래스에 scailing offset을 더함
Linear Classifier로 분류하기 어려운 경우
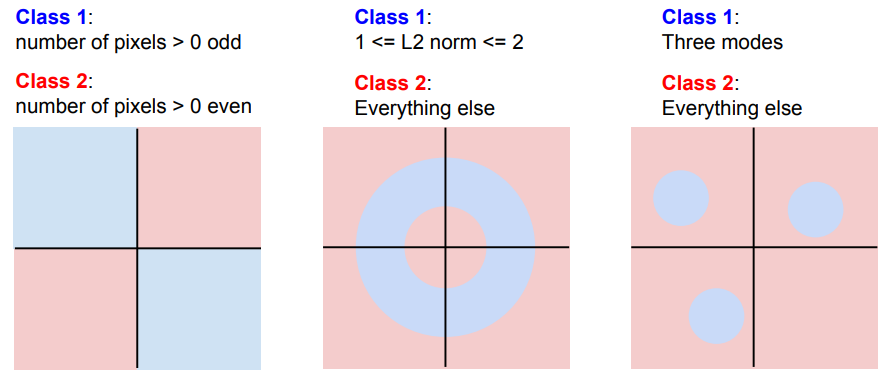
2, 3번째 그림과 같이 직선만으로는 나뉠 수 없는 경우가 있고, 이를 해결하기 위해 여러층의 신경망을 쌓게 되는 것이다.
