Abstract
휴머노이드 로봇 위한 오픈 파운데이션 모델.
GROOT N1은 이중 시스템 아키텍처를 갖는 VLA 모델. vision-language module(system2)는 시각 정보와 언어 지시를 통해 환경 해석. diffusion transformer module(system1)은 실시간으로 유연한 모터 행동 생성. 두 모듈이 긴밀하게 합쳐져 E2E 방식으로 공동 학습
GROOT N1을 실제 로봇 궤적 데이터, 인간 비디오, 합성으로 생성된 데이터셋이 혼합된 데이터 셋으로 학습시킴.
최신 IL보다 우수한 성능 보임. 실제 휴머노이드에 배치해서 language-conditioned bimanual mainpulation에서 강력한 성능 보임
1. Introduction
인간 수준의 물리적 지능을 향해 나아가기 위해 하드웨어, 모델, 데이터라는 세 가지 핵심 요소를 통합하는 풀스택 솔루션 주장
- 로봇은 물리적 세계에 구현된(embodied) 에이전트, 그 하드웨어는 로봇 능력 범위 결정 - 휴머노이드 로봇은 로봇 지능 구축하기 위해 매우 매력적인 형태
- 실제 세계의 다양성과 변동성은 로봇이 open-ended objective를 다루고 다양한 작업 수행을 요구 - 강력한 범용모델 필요
- 실제 세계에서 수집된 휴머노이드 로봇 데이터는 대규모로 확보하기에 비용이 크고 시간이 많이 듦. 따라서 효과적 데이터 전략 필요.
파운데이션 모델은 범용 로봇의 백본 구축의 로드맵 제시
but 휴머노이드 로봇 데이터셋의 인터넷 존재x. 다양한 로봇으로부터 데이터 모아서 확장하는 cross-embodiied learning 연구되었지만 로봇 차이로 인해 오히려 data islands 형성
범용 휴머노이드 로봇을 위한 오픈 파운데이션 모델인 GROOT N1 소개. VLA 모델로 테이블탑 로봇 팔부터 휴머노이드 로봇까지 아우르는 cross-embodiment 자원 가짐
인간의 인지 처리 방식에서 영감 받은 dual-system compositional architechure. System2 추론 모듈은 사전 학습된 VLM으로 NVIDIA L40 GPU에서 10Hz 동작 - 로봇의 시각 인식 정보와 언어 지시를 처리하여 환경 해석, 작업 목표 이해
System1은 action flow-matching으로 학습된 Diffusion Transformer. VLM 출력 토큰에 대해 cross-attention 수행. 구현체별 인코더와 디코더 사용하여 서로 다른 산태 차원과 행동 차원을 처리해서 action 생성 120Hz로 closed-loop 모터 action 생성
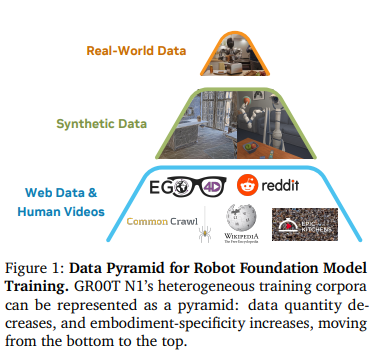
Data island 문제 완화하기 위해 Fig1에 나오는 데이터 피라미드 구조로 구성. web data, 인간 비디오는 피라미드 하단, 물리 시뮬레이션 or 증간 합성 데이터는 중간, 실제 로봇 하드웨어 수집된 real-world data가 최 상단 구성
pre-training, post=training 단계 모두에서 전체 데이터 피라미드에 걸쳐 학습할 수 있는 co-training 전략 개발.
인간 비디오나 신경망으로 생성된 비디오 같이 action 정보가 없는 데이터 소스로 학습시키기 위해 latent-action codebook을 학습하고 학습된 역동역학 모델 (Inverse Dynamics Model, IDM)을 사용하여 pseudo-action을 추론. -> 라벨 없는 action에 주석 부여하고 모델 학습을 위해 추가적인 로봇 구현체로 취급 가능.
GR-1 휴머노이드 로봇 사용한 실제 환경에서 SOTA 달성. GROOT-N1-2B 모델 체크포인트, 학습 데이터, 시뮬레이션 벤치마크 공개함.
2. GROOT N1 Foundation Model
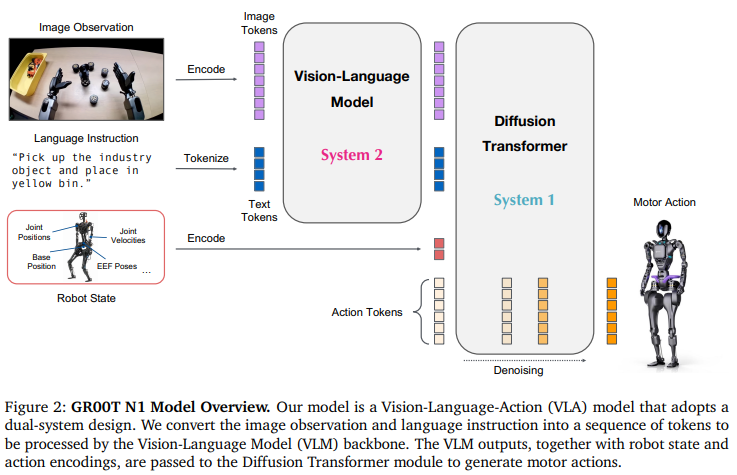
Vision-Language backbone + DiT(Diffusion Transformer) 기반 flow-matching policy 구성. - backbone은 NVIDIA Eagle-2 VLM 사용.
공개된 GROOT-N1-2B 모델을 2.2B 파라미터, VLM이 1.34B 차지. 16개 action chunk 샘플링 추론 시간은 L40 GPU에서 63.9ms.
- VLM 추론 모델과 DiT를 하나의 통합 학습 프레임워크 안에서 결합하는 compositional 모델 설계
- 일반화 + 강건성 위해 인간 비디오, 시뮬 및 증강 데이터, 실제 로봇 시연 데이터와 혼합하여 사용하는 효과적인 사전 학습 전략 개발.
- 대규모 다중 작업(massively multi-task)가 가능하고 language-conditioned인 정책을 학습하여 광범위한 로봇 구현체 지원, post-training 통해 새로운 작업에 빠르게 적응하도록 함.
2.2 Model Architecture
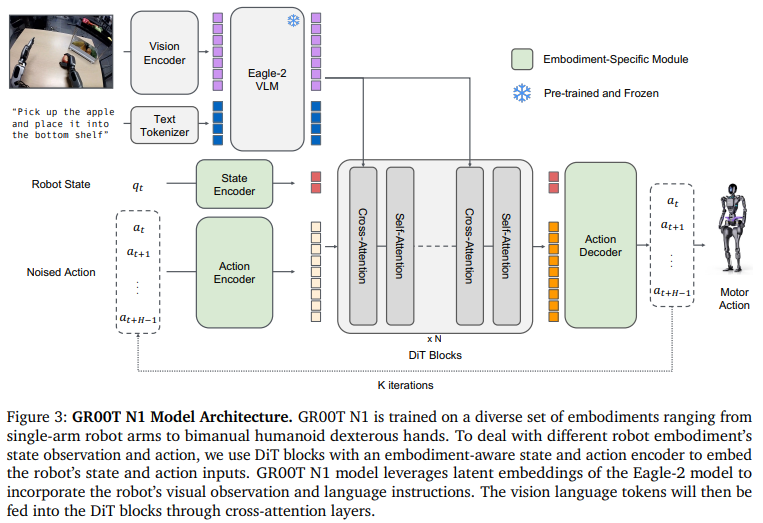
GROOT N1은 action generation을 위해서 flow matching 사용. DiT는 proprioceptive state와 action 처리하고, 이후 Eagle2-2 VLM 백본으로부터 나온 이미지 & 텍스트 토큰과 cross-attention 수행 하여 action 출력
State and Action Encoders
서로 다른 로봇 embodiments에서 다른 dimension과 state, aciton 처리를 위해 embodiment 별 MLP 사용하여 공유 임베딩 차원으로 투영. 이를 DiT 입력으로 사용. action encoder MLP는 diffusion timestep을 noised action vector와 인코딩.
action flow matching 사용하여 iterative denoising 통해 행동 샘플링. 노이즈 추가된 action 뿐만 아니라 robot proprioceptive state, image, text 토큰 입력 받음. action은 chunk 단위로 처리.
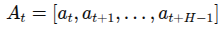
H = 16으로 설정
Vision-Language Module (System 2)
Eagle-2 VLM 사용. Eagle-2는 SmolLM2(small LLM model)와 SigLIP-2 이미지 인코더 기반으로 파인튜닝됨
이미지는 224x224 인코딩 된 후 픽셀 셔플이 적용됨. 그 결과 프레임 64개의 이미지 토큰 임베딩 생성됨. 이 임베딩들은 이후 Eagle-2 VLM의 LLM 구성 요소에서 텍스트와 함께 추가로 인코딩 됨. LLM과 이미지 인코더는 광범위한 vision-language 작업들에 대해 정렬됨. -> 한마디로 이미지 토큰 하고 Eagle에 들어감
policy training 동안 작업에 대한 텍스트 설명과 가능한 경우 여러장의 이미지가 VLM에 chat형식으로 입력됨. 이후 batch size x sequence length x hidden dimension의 형태로 LLM으로부터 feature 추출.
LLM의 최종 layer 대신 중간 레이어의 임베딩을 사용하는 것이 추론 속도를 더 빠르게 하면서 다운스트림 정책의 성공률을 더 높인다는 것을 확인. - 12 레이어의 표현 사용.
Diffusion Transformer Module (System 1)
GROOT N1은 DiT의 변형 구조 사용. DiT는 adaptive layer normalization 통해 denoisiing step conditioning을 수행하는 트랜스포머로 로 표현. cross-attention, self-attention 블록이 번갈아 배치된 구조.
self-attention block은 노이즈가 추가된 action 토큰 임베딩 와 상태 임베딩 에 대해 연산을 수행. cross-attention block은 VLM이 출력한 vision-language 토큰 임베딩 에 조건화 할 수 있도록 함.
최종 DiT 블록 이후에는 embodiment-specific Action Decoder로 사용하는 또다른 MLP 적용하여 개의 토큰으로부터 action 예측.
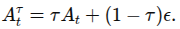
로 계산.
모델의 예측 는 아래 loss func 최소함으로써 denosing 벡터필드 근사하도록 학습
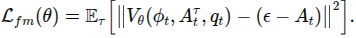
사용(어느정도 노이즈를 자주 보게 할 지의 분포)
추론 단계에서는 K-step denoising 통해 aciton chunk 생성. 를 무작위 샘플링 후 forward Eular integration 사용하여 반복적으로 action chunk 갱신.
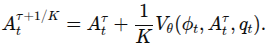
실험적으로 모든 embodiment에서 의 추론 스텝이 효과적임을 확인.
2.2 Training Data Generation
이 단에서는 내가 필요한 부분만 집중해서 정리
Latent Actions - 좀 중요함. 뭔가 SAGE 논문에서 LLM 학습 하는거랑 비슷할지도
인간 1인칭 영상이나 신경망이 만든 궤적에는 행동 데이터가 없음
-> VQ-VAE (Ye et al., 2025) 기반 latent action
VQ-VAE는 연속변화를 descrete한 codebook token으로 바꾸는 모델
인코더는 고정된 윈도우 크기 를 갖는 비디오에서 현재 프레임 와 미래 프레임 를 입력으로 받아 latent action 출력. 디코더는 와 를 입력으로 받아 를 재구성하도록 학습. 이 모델이 VQ-VAE 목적함수로 학습됨. 인코더에서 나온 연속 임베딩은 코드북에서 가장 가까운 임베딩으로 매핑
학습후에는 인코더를 inverse dynamics model로 사용.
, 쌍이 주어지면 양자와 이전의 연속 임베딩 추출하여 사전 학습 시 latent action label로 사용. 동일한 flow matching loss를 적용하되, 별도의 LAPA(Latent Action Policy Adaptor) 구현체로 취급.
-> 모든 데이터를 동일한 latent space로 통합할 수 있으며 embodiment 간 일반화 성능 향상

쉽게 정리하기
- Encoder: 에서 로 가기 위해 필요한 행동을 로 요약 -> 상태 변화의 원인을 압축한 표현
- Decoder: , 를 입력으로 받아서 미래 프레임 를 재구성
-> 하나만으로 지금->미래 변화를 설명할 수 있도록 만들기
Quantization이 중요 포인트
인코더는 연속 벡터 출력. 이 벡터는 codebook에서 가장 가까운 토큰으로 치환 -> 유한개의 행동 타입
학습 후
디코더 거의 쓰지 않고 인코더만 사용 - 두 프레임 사이에 어떤 행동이 있었는지 추론 가능. -> Inverse Dynamics Model로 사용
Inverse Dynamics Model: 뽑아내기
이때 VQ-VAE에서 하는것처럼 Quantization 하지 않고 그 전의 continuos한 vector 사용 - DiT이기 때문
다양한 Embodiment로 해석하기 위해 "LAPA" embodiment로 취급 -> 모두 같은 형태의 action 처럼 취급
2.3 Training Details
요약
GR00T N1의 학습은 사전 학습(pre-training)과 사후 학습(post-training)의 두 단계로 구성된다.
사전 학습 단계에서는 flow-matching 손실을 사용하여, 실제 로봇 데이터·합성 데이터·인간 비디오를 포함한 다양한 구현체와 데이터 소스를 동시에 학습한다. 행동 라벨이 없는 인간 비디오에는 잠재 행동(latent action)을 사용하고, 로봇 데이터에는 실제 행동과 잠재 행동을 함께 사용한다. 신경망 생성 궤적(neural trajectory)의 경우에는 잠재 행동과 역동역학 모델(IDM)이 예측한 행동을 함께 사용한다.
사후 학습 단계에서는 각 로봇 구현체별 데이터셋에 대해 개별적으로 파인튜닝을 수행하며, 이때도 VLM의 언어 부분은 고정한다. 데이터 부족 문제를 해결하기 위해, 사후 학습에서도 신경망 생성 궤적을 활용한 데이터 증강을 수행한다. 생성된 비디오는 행동 라벨이 없기 때문에 잠재 행동 또는 IDM 기반 의사 행동(pseudo-action)을 사용해 학습한다. 실제 로봇 데이터와 신경망 생성 데이터는 1:1 비율로 샘플링하여 공동 학습한다.
학습 인프라는 NVIDIA OSMO 기반 대규모 GPU 클러스터를 사용하며, 최대 1024개의 H100 GPU로 학습한다. GR00T-N1-2B 사전 학습에는 약 5만 GPU-시간이 소요되었다. 제한된 연산 환경에서는 어댑터 레이어만 튜닝하는 방식으로 단일 GPU에서도 파인튜닝이 가능하다.
확인할 부분
GR00T N1의 학습은 사전 학습(pre-training)과 사후 학습(post-training)의 두 단계로 구성된다.
Pretraining에서는 flow-matching loss 사용 - 실제 로봇 데이터-합성 데이터-인간 비디오 포함한 다양한 embodiment랑 데이터 소스를 동시에 학습.
Post-training에서는 각 로봇 embodiment 데이터셋에 대해 개별적으로 finetunning 실행 - VLM 언어 frozen
뒤는 대충 마무리
