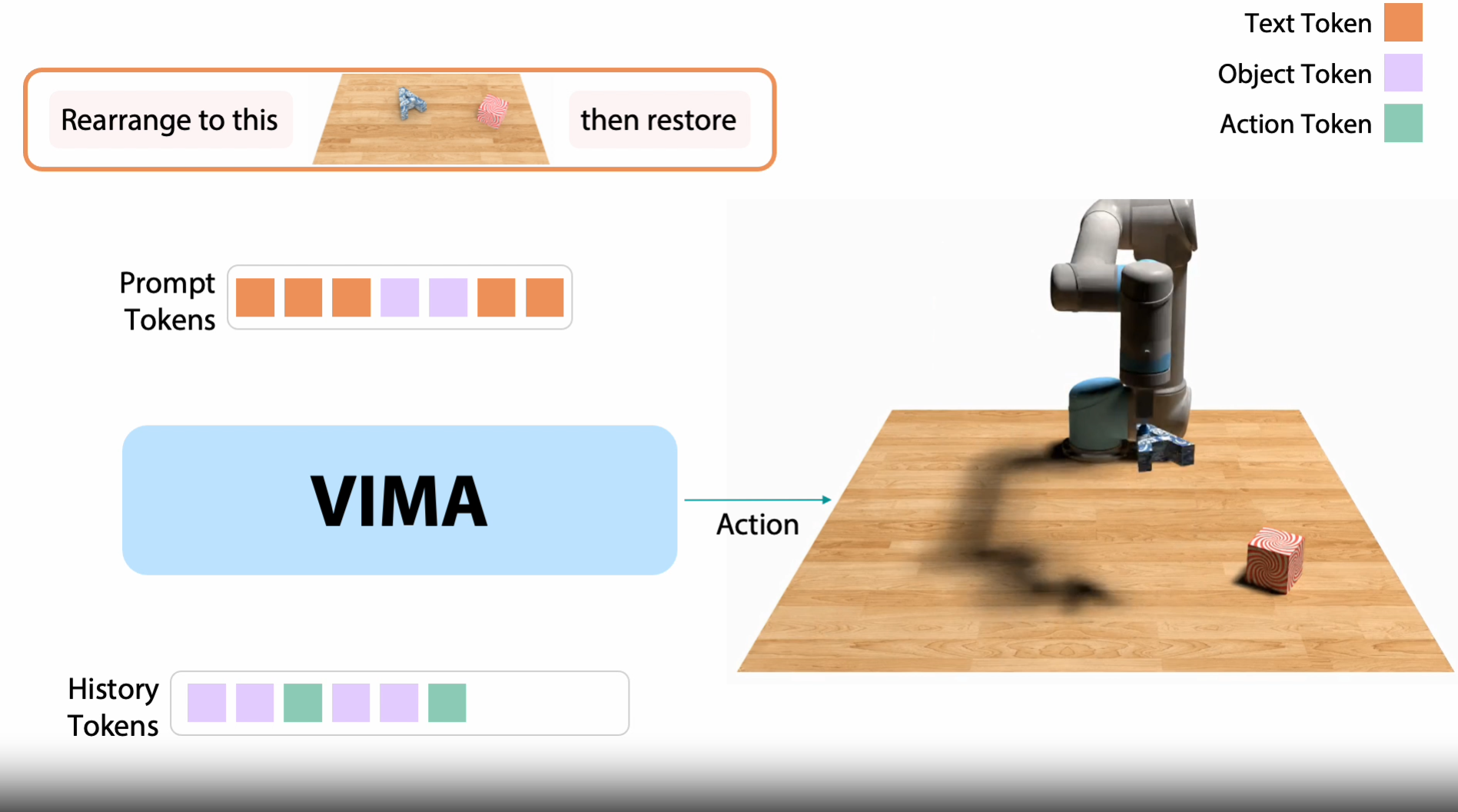
일단 이 논문의 경우 History Token을 넣는 부분에서 읽게 됨. memory를 대체할 수 있을 지 확인
Abstract
광범위한 로봇 조작 작업들이 텍스트 & 시각 토큰이 교차(interleaving)된 멀티모달 프롬프트로 표현될 수 있음을 보임.
수천 개의 preocedurally-generated tebletop task, 멀티모달 프롬프트, IL 위한 60만개 이상의 expert trajectories, 시뮬 벤치마크 구축
프롬프트 처리하고 autoregressively한 transformer based 로봇 에이전트인 VIMA 제안 - 강력한 모델 확장성과 데이터 효율성 달성. 동일 학습 데이터 사용 시, 가장 어려운 zero-shot 일반화에서 기존 설계 대비 최대 2.9배 높은 작업 성공률 달성. 학습 데이터 10분의 1만 사용하더라도 SOTA 모델보다 2.7배 더 높은 성능 보임.
1. Instruction
새로운 skill이 필요한 작업의 경우, 소수의 비디오 시연만으로 적응해 학습할 수 있어야 함. 추가로 범용 로봇이 task specification을 위해 직관적이고 표현력이 풍부한 인터페이스가 필요함. 이미지 + 텍스트 형태의 프롬프트도 가능해야 함.
아래는 contribution
- 광범위한 로봇 조작 작업을 하나의 sequence 모델링 문제로 변환하는 새로운 멀티모달 프롬프팅 정식화
- 에이전트의 확장성과 일반화 성능을 체계적으로 평가하기 위한 다양한 작업으로 구성된 대규모 벤치마크
- 멀티태스크 수행과 제로샷 일반화가 가능한 멀티모달 프롬프트 기반 로봇 에이전트
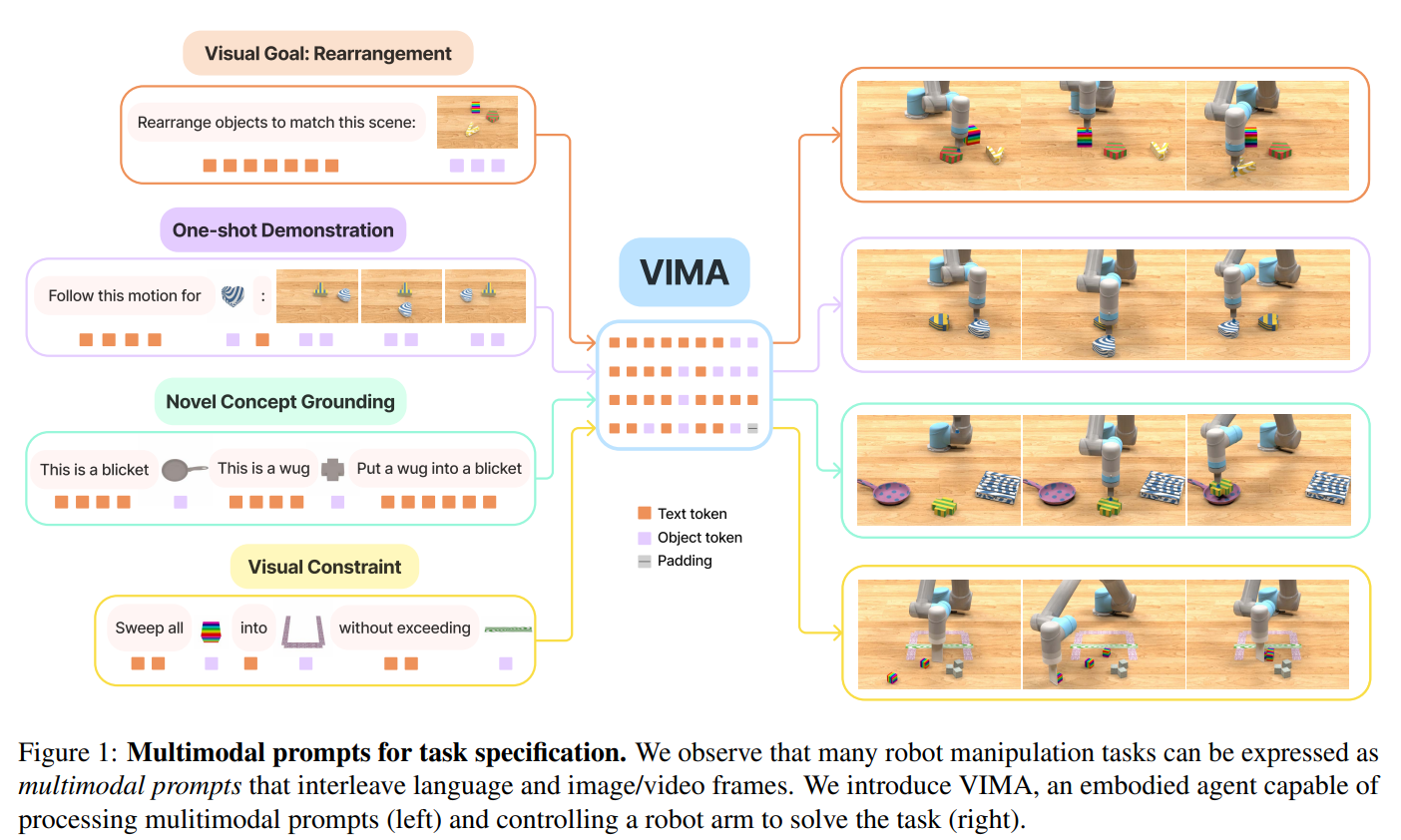
많은 manipulation 작업들이 언어와 이미지 또는 비디오 프레임을 교차하여 구성한 멀티모달 프롬프트로 정식화 될 수 있다는 점에서 출발
Fig 1에서 보이듯이 "이미지와 동일하도록 재배치", "비디오 프레임의 궤적 따라하기" 등등
멀티모달 프롬프트는 개별 모달리티 사용하는 것 보다 더 높은 표현력 제공 + 범용 로봇 학습을 위해 통일된 입출력 IO 인터페이스 가능하게 함
멀티모달 프롬프트 에이전트 평가 위해 Ravens 시뮬 기반한 새로운 벤치마크 VIMA-BENCH 개발. - 벤치마크 관련은 생략
멀티모달 프롬프트로부터 로봇 조작 학습하는 VIMA(VisuoMotor Attention Agent) 제안. pretrain된 언어모델 사용하여 텍스트-시각 토큰이 교차된 입력 시퀀스 인코딩 + 각 상호작용 단계마다 로봇 제어 행동을 autoregressive 디코딩
raw image 직접 처리 대신 VIMA는 object-centric 접근 방식 채택. 객체 검출기 사용하고 객체 토큰 시퀀스로 평탄화함. 2M~200M 규모의 모델 7개 학습함.
2. Multimodal Prompts for Task Specification
task specification문제 - 서로 상이하고 상호 호완되지 않는 인터페이스 요구
-> 멀티모달 프롬프트 제안 - 아래와 같은 작업 명세 형태
- Simple object manipulation
- Visual goal reaching
- Novel concept grounding
- One-shot video imitation
- Visual constraint satisfaction
- Visual reasoning
3. VIMA-BENCH: Benchmark for Multimodal Robot Learning
멀티모달 작업 풍부하게 포함하고 종합적인 테스트베드 제공하는 벤치마크 제안
멀티모달 프롬프트 템플릿 갖춘 17개ㅐ 작업 제공
전면뷰와 top-down뷰 객체 중심 모델 학습하기 위해 segmantation 정보와 bbox제공. action의 경우 end effector 자세로 파라메터화
뭐 뒤에는 비슷비슷함
4. VIMA:Visuomotor Attention Agent

로봇 정책 학습
여기서 는 과거 상호작용 나타냄
frozen 언어 모델로 인코딩, cross-attention 사용하여 인코딩된 프롬프트에 waypoint commands 디코딩.
VIMA는 bbox 좌표와 잘라낸 RGB 패치로부터 토큰 계산하는 object-centric 표현 채택
Tokenization
프롬프트에는 텍스트, 단일 객체 이미지, 테이블탑 이미지 입력됨.
텍스트의 경우 T5 토크나이저와 단어 임베딩 사용해서 단어 토큰 생성
images of full scenes의 경우 도메인에 맞게 파인튜닝된 Mask R-CNN 사용하여 객체 추출. 이후 bbox encoder와 ViT사용하여 객체 토큰 계산.
images of single objects도 동일한 방식으로 토큰 생성하되, 더미 bbox생성.
이런 프롬프트 tokenization통해 텍스트 토큰과 시각 토큰이 교차된 하나의 시퀀스 생성함. 이후 T5 잌노더 사용하여 프롬프트 인코딩
Robot Controller
멀티태스크 정책 설계에서 도전적인 요소 중 하나는 적절한 조건화(conditioning) 메커니즘 선택하는 것. 위 모델 구조에서 로봇 컨트롤더 디코더는 프롬프트 시퀀스 와 궤적 이력 시퀀스 사이의 cross-attention 층을 통해 프롬프트에 조건화 됨.
프롬프트로부터 와 시퀀스를 계산하고 궤적 이력으로부터 쿼리 계산. 각 cross-attention 층은 아래 식과 같은 출력 시퀀스 ` 생성
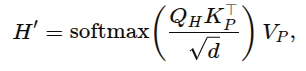
이런 residual connection은 상위 층의 출력을 입력 롤아웃 궤적 시퀀스와 연결하는데 사용됨. 아래와 같은 장점을 가짐
- 프롬프트와의 연결이 강화됨
- 원본 프롬프틍 토큰의 흐름이 손상되지 않을 채 깊게 유지
- 계산 효율성 우수
VIMA의 디코더는 cross-attention과 self-attention층이 번갈이 배치된 L개 층으로 구성됨.
프롬프트를 K, V로 두고 현재 상테 + 과거 이력을 Q로 두기.
하지만 이 부분은 long horizson, 메모리 역할 못함
