Abstract
대규모 행동 궤적 데이터셋 기반 VQ-action tokenizer 제안.
기존 접근들보다 100배 이상 많은 데이터 활용 -> 시공간적 동역학 학습 가능
한번 학습한 토크나이저는 별도 추가 학습 없이 다양한 작업에 zero-shot 가능
본 연구 발견 중 합성 행동 궤적과 실제 행동 궤적 사이의 도메인 차이가 매우 적음. -> 합성 궤적 데이터 증가할수록 downstream task 성능이 유의미하게 향상. 특히 long-horison 시나리오 성공률 향상 업.
action tokenizer가 솔루션이 될 수 있음을 보여줌
1. Introduction
최근 생성 모델들에서 tokenization이 매우 중요함 - 고차원 연속 데이터를 간결한 토큰 시퀀스로 변환하면서 복잡도 감소 - action 시퀀스의 경우 시공간적 연속성 가지기 때문에 압축이 더 쉬움
최근 VLA모델에 action quantized tokenization 연구 늘어남.
이 논문에서는 action tokenization 잠재력 분석 + 확장선 + 정확성 초점 - 정확할수록 좋음 -> 충분히 데이터가 많아야 함
action tokenizer는 전체 VLA 모델 스케일 비해 계산 낮음
VQ-VAE 프레임워크를 action-tokenizer 학습에 제아ㅏㄴ
progressive training 전략 도입
- OpenX-Embodiment 같은 실제 로봇 데이터셋 사용하여 학습 - 노이즈와 진동 포함
- LIBERO, ManiSkill 같은 시뮬에서의 깨끗한 synthetic 데이터 통합
-> 부드럽고 안정적인 표현으로 수렴
실제 + 시뮬 환경에서 실험함. LIBERO에서 VQ-VAE action tokenizer 평가
주요 contribution
- 일반적인 convolutional residual VQ-VAE 기반 action tokenizer 프레임워크 제안
- 대규모 시뮬 action 데이터 활용한 tokenizer 확장 가능성 입증
- VLA 모델 성능, 추론 속도, long horizon 능력 향상시킴을 증명
2. Related Works
저수준 action을 직접 예측 -> 연속 action을 이산화
- binning
- VQ-VAE
- cosine transform
Tokenizer
- 언어는 BPE(byte pair encoding) 주로 사용
- 비전 생성에서는 vector quantization 주로 사용
- 로봇은 행동 예측을 생성 문제로 모델링, 로봇 action을 토큰화해서 스킬 내부의 다중 모달 분포 포착
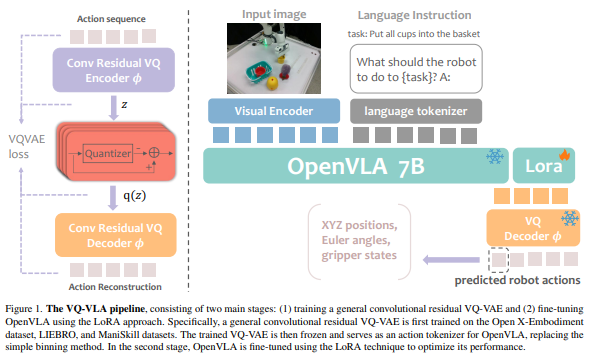
3. Methods
3.1 Preliminaries: VLA models
백본으로 OpenVLA 사용 - 7B VLM 백본 파인튜닝해서 로봇 action prediction에 discrete tokenization strategy 채택
이 방법은 vision-language 문제로 정식화, 입력 관측 이미지와 자연어 명령을 discrete robot action sequence로 매핑
continous robot action은 각 차원마다(x, y, gripper state 같은 것) 256개의 bin으로 이산화 됨. bin 경계는 최대 최소가 아니라 학습 데이터 분포의 1번째 및 99번째 퍼센트를 기준으로 설정하여 이상치의 영향을 완화함. 이러한 이산화 과정을 통해 N 차원 action은 N개의 이산 정수 값(0~255)으로 변환됨.
이 행동 토큰들을 LLM의 vocabulary에 임베딩하기 위해 OpenVLA는 LLaMA tokenizer에서 가장 사용 빈도가 낮은 마지막 256 토큰을 덮어서 사용. 이는 기존 special token 100개만 예약하고 있어서 별도의 특수 토큰 추가 대신 기존 토큰을 재활용하는 방법임
-LLaMA는 정수 토큰 ID 스퀀스만 처리 가능 -> 그래서 이 action 토큰들을 0~255 사이 정수로 매핑해서 넣는 것
3.2 Action Tokenizer via Residual VQ_VAE
Residual VQ-VAE 기반 action tokenizer설계, 인코더와 디코더 구조는 pyramidal flow matching에서 사용된 VAE 구조에서 영감 받음.
기존 Residual VQ-VAE에서 사용된 MLP대신 2D temporal conv (TCN인지 아닌지 모르겠음) 레이터 통합함. 이는 local relationship과 hierarichical temporal dependencies를 효율적으로 포착할 수 있어서 MLP의 스케일 한계를 해결함.
길이 n이고 차원 d인 action 시퀀스 가 주어졌을 때 2D temporal convolution으로 구성된 encoder 가 latent space x로 변환함. 이 x를 압축하기 위해 RVQ(Residual Vector Quantization)을 적용함.
(https://www.youtube.com/watch?v=ehosSKUWw2A 이거 참고해서 보기. 인코더에서 residual로 해서 좀 더 정확하게 )
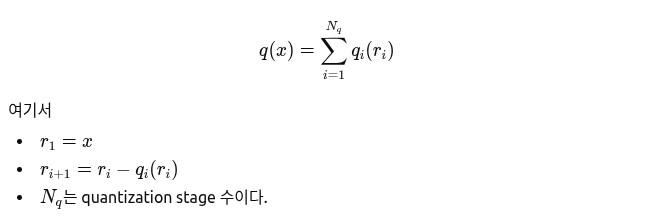
가 residual 횟수라고 생각하면 됨.
이 이러한 embedding q(x)는 디코더 를 통해 action 시퀀스 로 복원됨.
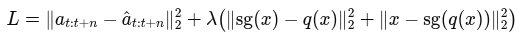
위와 같은 loss func 사용. sg는 stop-gradient 연산이며 는 loss 간 계수. 실험에선 4 사용
3.3 Training Residual VQ_VAE
Action tokenizer의 스케일링 능력 평가를 위해 세가지 버전의 Residual VQ-VAE학습
- Open X-Embodiment 데이터셋만 사용
- Open X-Embodiment + LIBERO 데이터 셋
- Open X-Embodiemnt + LIBERO + ManiSkill 데이터셋
Time Embedding
sinusoidal time embedding 사용 - 저주파 및 고주파 시간적 패턴을 모두 포착하 수 있음. fine-grained 시간적 세부 정보 표현 능력 향상
Action-Type Embedding
action 시퀀스를 구성하는 서로 다른 구성요소들(ex) XYZ, Euler angles, and gripper states)에 대해 학습 가능한 임베딩이 추가됨. action vector의 7개 차원은 각각 서로 다른 의미를 가지므로 strong prior 제공
범용 로봇 action tokenizer 학습하고 연산 옵버헤드를 줄이기 위해 행동 시퀀스만을 입력으로 사용하여 학습함. A100 GPU 1주일
3.4 Integrating Residual VQ-VAE as Action Tokenizer in VLA - VLA에서 Residual VQ-VAE를 action tokenizer로 통합
표현력과 정밀도 향상 위해 OpenVLA에서 사용된 bin 기반 토크나이저를 Residual VQ-VAE action tokenizer로 대체
행동 시퀀스를 이산화하는 대신 action sequence 는 사전 학습되고 동결된 를 통해 처리되며 latent space를 생성. 이 표현들은 이후 개의 Residual VQ레이어 대응되는 descrete codebook index 로 양자화된다. 이는 VLM에서 action token으로 사용됨.
OpenVLA와 달리 생성된 토큰들은 서로 겹치지 않는 고유한 범위가 할당됨. - 서로 다른 레이어에서 동알한 ID 갖는 토큰들이 서로 다른 특징 갖는것을 방지.
VLM은 이러한 토큰들을 직접 예측하도록 학습됨
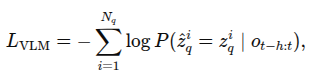
위 loss func으로 학습. VAE가 생성한 토큰과 cross entropy로 계산됨.
추가로 OpenVLA랑 유사하게 어휘 사용 빈도가 낮은 토큰들은 파인튜닝 단계에서 교체됨.
한마디로 VLM을 VQ-VAE에서 나온 값을 정답으로 하고 학습시킨 것
4. Experiments
LIBERO 벤치마크 Maniskill, RLBench 혼합해서 학습 - 유효성과 확장성 검증을 위해
4.1.2 Effectiveness of Conv Residual VQ-VAE
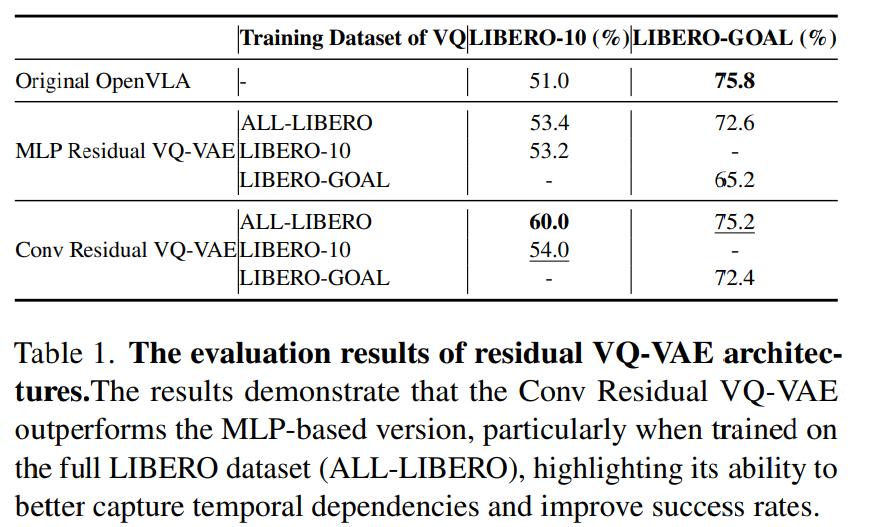
4.1.3 Scaling Data Improves VQ-VAE Action Tokenizer Performance

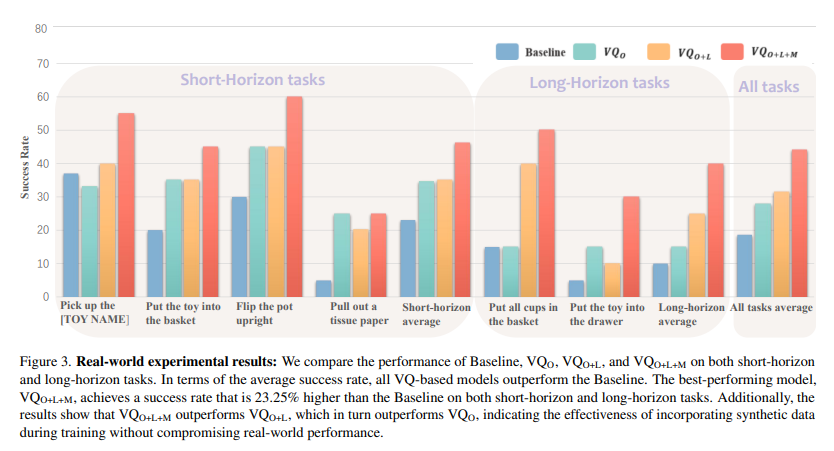
보면 실험이 OpenVLA(baseline)하고만 진행됨. 베이스라인 대비 좋긴 하지만 실험이 조금 아쉬움...
본인 모델들에 데이터셋을 얼마나 썼냐에 대해서는 성능 잘 나오는 것 같긴 함.
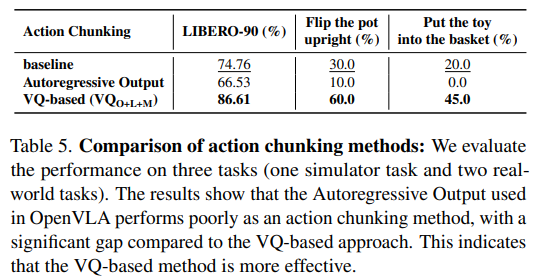
autoregressive 방식과 비교해서 기존것에 autoregressive 넣으면 sr 떨어짐 + 동일행동 반복하는 shortcut learning 문제
VQ는 좋았다
임베딩 부분

조금 그럼
단점이 명확해 보임
VQ-VAE를 학습시킬 때 데이터 셋이나 VQ-VAE의 인코더가 성능이 충분하지 않다면 똥이 될 가능성이 농후해 보임
VQ-VLA는 학습시킨 후 VLM 모델에서 latent space를 잘 뽑아내게 fine tunning 시켜야 함 -> 그렇다면 그냥 엔코더랑 다를게 뭐냐??
따라서 엔코더 or 디코더가 scale이 확연히 크고, 데이터 셋도 많아야 유효함
그리고 codebook이 모든 latent space에 따라 다 다르게 매칭되니 이게 일반화가 될까도 싶음.
