Abstract
시선 예측위해 appearance랑 scene content 추론 필요함. 기존 연구들은 head, scene encoder 필요. 그리고 depth나 pose 추정 보조 모델들 feature 결합하는 파이프라인 필요함. 이 논문에서는 DINOv2 encoder사용해서 transformer 기반 Gaze-LLE 제안. 사람별 위치 프롬프트 적용해서 디코딩. SOTA 달성, opensource
http://github.com/fkryan/gazelle
1. Inroduction
기존에는 multi-branch 설계로 head, scene, depth, pose같은 모달리티 통합. 기존에는 인간이 라벨링 하여 얻은 소규모 데이터셋에 의존한다는 한계 -> 파운데이션 모델 기반 접근법으로 이점 ㄱㄴ?
기존 아키텍처에 단순히 백본을 DINOv2로 바꾼다고 해서 성능 안나옴. 그냥 썼을 때는 안좋음. 그래서 디코더 설계가 중요.
이 논문에서는 파운데이션 모델을 본 과제에 활용할 때 어려움 분석하고 아키텍처 선택과 트레이드 오프 정량화하기 위한 실험 결과도 제시
- 간결하고(streamlined) 대부분의 기존 방법들이 사용하는 학습 가능 파라미터 수 약 5% 사용
- SOTA 달성
- 범용적, 추가 파인튜닝 없어도 강한 데이터셋 간 일반화
- 학습 용이, 1.5GPU 시간 미만으로 SOTA -> 단일 GPU에서 매우 짧은 시간 학습
2. Related work
시선 추정의 핵심 특징 중 하나는 인물 머리 영역에서 추출된 feature를 다른 장면들이랑 통합 -> head representation 브랜치 입력. 이 외에도 Introduction에서 언급한 head에 대해서 같이 융합 -> 다양한 목적 함수사용 -> 수렴 속도 느림 / 이에 반해 head position를 별도 프롬프트로 제공하는 통합 디코더 아키텍처 사용. 모든 장면 단서들이 디코더 내부에서 추출됨.
기존에도 다중 분기가 아닌 two-branch 연구가 있었음. 이는 head랑 scene만 사용 but 여전히 end2end 방식. 이에 반해 두가지 입증
- head analysis는 디코더 내부에 직접 통합 가능. 이를 통해 헤드 브랜치 자체를 제거하고 아키텍쳐를 더욱 다순화, 정제(streamline) 가능
- frozen 대규모 FM encoder 사용할 경우, 학습 파라메터 수를 두 자릿수 만큼 줄이면서도 더 우수한 성능
3. Gaze-LLE
Problem Definition
RGB + 특정 인물 머리 바운딩 박수 -> 시선 확률 heatmap 예측
+) 추가로 인물이 바라보고 있는 시선 대상이 프레임 내부에 존재할 확률 나타내는 값
3.1 Model Architecture
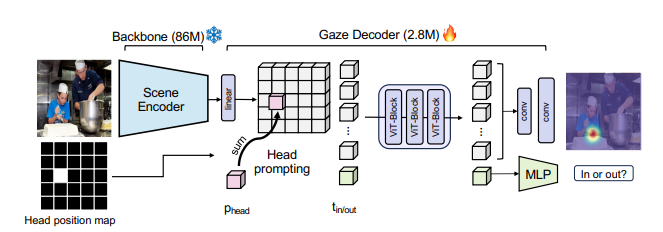
백본 뒤에 gaze decoder는 헤드 프롬프팅 수행하고, 소형 트랜스포머 모듈 통해 시선 히트맵, 시선 대상 프레임 내부에 있는지 여부 예측
Scene Encoder
DINOv2 사용 -> feature map -> linear layer : feature map
Head Position Embedding
헤드 위치 프롬프팅을 어떻게 통합할 것인가?
-> 기존 연구들과 달리 scene encoder 이전이 아니라 이후에 head 위치를 통합하는 것이 가장 좋음. head 바운딩 박스로부터 추출된 scene feature map 상에서 다운샘플링 & 마이진화 된 마스크 M 구성. 마스크 M 사용하여 머리에 해당하는 장면 토큰들에 학습 가능한 위치 임베딩을 더함.
Transformer Layers
작고 학습 가능한 트랜스포머 모듈 T 학습. Self attention 사용해서 head position embedding 특징 처리. T 입력으로 헤드 위치가 추가된 feature map S를 flatten하여 토큰 리스트 구성. 추가로 모델 시선 대상이 프레임 내부에 있는지 확인하는 토큰 t도 추가 아래가 토큰 리스트
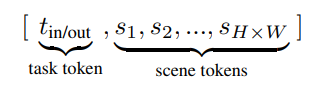
spatial 성격 가지므로 장면 토큰들 T가 입력되기 전, 2D sinusoidal positional embedding P를 추가함.
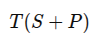
을 트랜스포머 입력으로. 3개 레이어 구성
Prediction Heads
갱신된 장면 feature S`와 테스크 토큰 t`을 얻음. S`를 feature map으로 다시 재구성되며, 이를 시선 디코더 D_hm에 전달. D_hm은 두개 Conv layer 구성, 이걸 H_out x W_out으로 업샘플링.
2개의 MLP layer에서 t_in/out 받아서 프레임 내부인지 외부인지 분류 점수 출력
Training objective
heatmap 예측을 위해 픽셀 단위 binary cross-entropy 사용하여 학습. supervisory signal는 각 정답 좌표 주변에 표준편차가 3인 2차원 가우시강 분포 배치하여 구성된 heatmap
모델이 시선의 프레임 내부인지 외부인지를 동시에 예측해야 하는 벤치마크 설정의 경우 multitask loss 사용
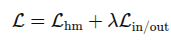
L_hm은 픽셀 단위 binary cross-entropy
L_in/out은 in/out을 위한 cross entropy loss
Loss func 간단하고 학습 파라메터 2.8M
3.2 Key Design Decisions for Foundation Models
사전 학습 FM을 단일 백본으로 사용할 때 인코더를 통합하는 방식의 설계가 존재. 여기서는 백본관련 실험 진행
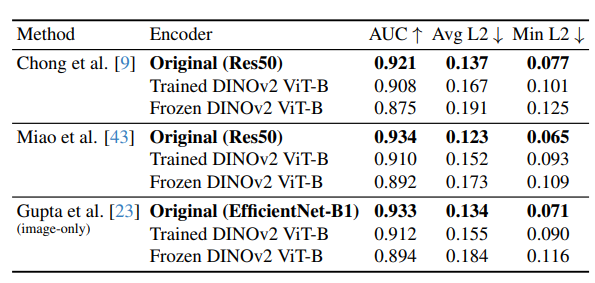
표 보면 기존 아키텍쳐에 DINOv2 갖다 쓴거. 파인튜닝을 하든 말든 기존의 더 약한 백본보다 안좋음. -> 기존에도 gaze following에서 ResNet-50이 더 좋을 때도 있었음.
이 논문에서는 그래서 GazeFollow 데이터셋에서 베이스라인 실험을 함. Frozen DINOv2를 사용하여 scene feature와 head feature를 추출하고 단순 concatenate 한 후 시선 히트맵으로 디코딩하는 방식. 실험을 통해 3가지 아키텍쳐 선택의 영향 정량화 함
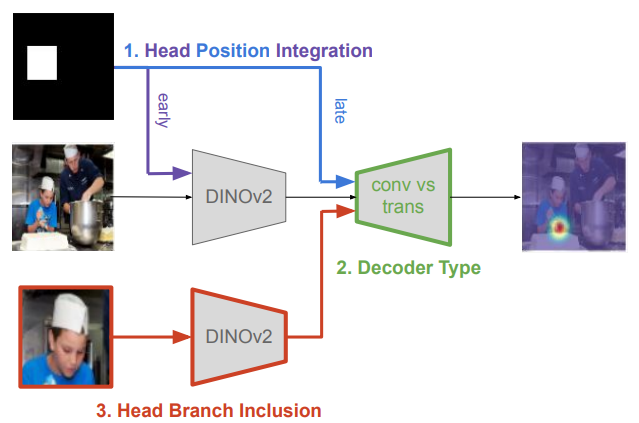
- Head position 통합하는 방식
- Feature decoding의 설계
- Head branch의 사용 여부가 각각 성능에 미치는 영향 분석
Where shoud we inject the head position?
거의 모든 기존 연구들은 Head 위치를 scene 브랜치의 추가 채널로 제공함. 이 방식은 gaze 학습 과정에서 scene 인코더가 머리 위치를 어떻게 활용할지를 새로 학습해야 함을 의미
이는 Encoder를 frozen한 채 활용하고자 할 때 문제 -> 머리 위치를 인코딩 하려면 파인튜닝해야 하기 때문. -> DINOv2 특징 추출한 이후에 머리 위치를 단순히 concatenate 하는게 성능 더 좋음 아래 표 a vs c
How shoud we decode the DINOv2 features?
대부분 기존 연구들은 Head feature은 여러개 Conv layer 사용해 디코딩 -> gaze 특화에만 좋음. DINOv2 사용할 때는 소수의 Conv Layer가 가지는 receptive field가 멀리 떨어진 시선 대상을 추출하기에는 너무 작을 수 있음.
이 논문에서는 전통적으로 6개 layet 스택으로 히트맵 디코딩하는 방식 vs 트랜스포머 다음 2 Conv layer 디코더 비교. 두 구성은 파라메터가 동일하지만 트랜스포머 레이어가 global information 활용 가능하기 때문에 성능 좋음. 표 c vs d
Do we need a head branch?
기존에는 head branch 사용 but 이 논문에서는 DINOv2 같은 FM에 그런 정보 있다고 생각.
검증하기 위해 Head branch 사용한거랑 안한거 비교함. 트랜스포머 기반이랑 별 차이 없음. 표 d vs f
주목할 점은 Conv 디코더 사용할 때는 이러한 현상이 없음. 표 c vs e.
-> 이는 시선 단서들이 DINOv2 쓸 때 트랜스포머 써야지 효과적으로 뽑아냄.
4. Experiments
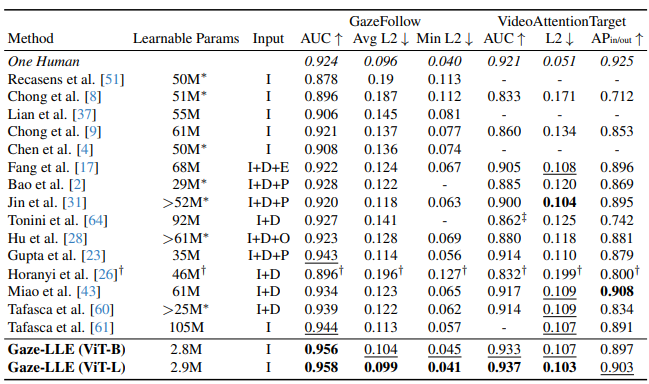
이 논문에 의하면 굳이 depth module 없어도 DINO단에서 예측이 이미 되어있을거다... 라고 이야기하는 거랑 같음.
그렇다면?
일단 exo -> ego로 객체 매칭해주는 논문 읽어보자
