Abstract
사람의 객체 상호작용, 시선 패턴, 그리고 그에 대한 예측은 긴말하게 연결되어 있음. 하지만 대부분의 기존 모델들은 gaze와 action을 분리해서 다뤄서 상호의존성뿐만 아니라 통합 이점 놓침
-> SAGE(Synchronized Action and Gaze Estimation) 제안. 인간의 물체 상호작용과 인간 시선의 동시 인식 및 예측 end-to-end 학습 가능한 모델 결합
-> exocentric 비디오에서 인간 물체 상호작용과 시선 분석하는 데이터셋 부족해서 Exo-Cook이라는 새로운 벤치마크 구축
-> VidHOI, EGTEA Gaze+, Exo-Cook 세가지 벤치마크 실험 결과, 현재 및 미래 프레임 걸쳐 시선과 행동 모델링 일관된 성능 + 몇몇 task에서 SOTA 달성
1. Introduction
사람이 어디를 바라보고 무엇과 상호작용하는지를 바탕으로 현재 행동 인식하고 미래 행동 예측하는 능력이 사람의 하나의 인지 모델을 통해서 이루어짐
Intelligent system이 사람과 자연스럽게 상호작용하기 위해서 인식과 예측 통합해야 함. 보조 로봇 등등 다음에 무슨일 일어날 지 예측 필요. 이때 시선이 인산의 의도를 드러내는 단서를 제공함.
보통 이 주제에 대해서 거의 분리해서 접근하거나 통합하는 시도가 있어도 극히 드뭄. 중요하게 대부분의 기존 연구들은 시선과 행동이 시간에 따라 함께 어떻게 미래로 전개되는지 모델링 xx
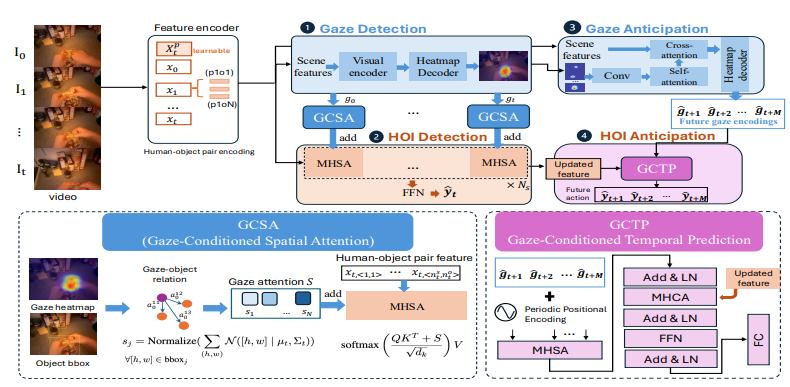
SAGE (Synchronized Action and Gaze Estimation) 제안 현재, 미래에 대한 gaze와 action 예측
Transformer 기반 백본 기반 gaze를 spatiotemporal attention 매커니즘으로 통합시켜 어디를 보는지와 무엇을 하는지 사이의 결합 관계 포착 & 학습
GCSA (Gaze-Conditioned Spatial Attention)모듈. 시선 정보를 공간적 attention에 주입하여 인간-물체 상호작용 cue 강조.
GCTP(Gaze-Conditioned Temporal Prediction)모듈. 미래 시선과 행동 사이의 시간적 상관관계 모델링.
+) 기존 연구들이 ego 혹은 exo 중 하나에만 제한되어 있었지만 분리된 학습으로 두 시점 모두 지원
이러한 모델 학습 + 평가 위해서 데이터 셋 필요. 행동+시선이 있긴 하지만 egocentric 한정(Ego4D). Ego-Exo4D는 gaze와 action에 대해서 주석 제공하지만 공동 모델링과 평가 위한 벤치마크는 제공xx +이 task에 쓰기 어려움(gaze-action 모델링 위해서 주석 전처리, 새로운 라벨 생성, 모달리티 정령 등등 필요) 그래서 이 논문에서는 Ego-Exo4D부터 파생된 Exo-Cook 3인칭 벤치마크 소개
2. Related Works
2.1 Gaze Detection And Anticipation
이 모델들은 gaze estimation이 주 목적이지만 행동 인식 보조용으로도 사용됨. 반대로 행동 정보를 활용해서 시선 추정 보완은 거의 이루어지지 않았고 오히려 성능 저하시킬 수 있다는 보고도 있었음. 이 프레임워크에서는 action과 gaze가 상호 보완적으로 강화할 수 있음을 보임
gaze estimation의 경우 egocentric 환경에서만 + 행동 상호작용 고려x -> 의도 이해 부족 / exocentric 비디오에서의 시선 예측 다룬 기존 연구는 존재x
2.2 Recognizing And Anticipating Actions
시선을 모델에 통합하여 공간적 위치 추정 정확도와 맥락적 정밀도 향상 보여줌. 행동 예측도 발전함.
최근에는 goal-conditioned reasoning / motion primitive, 오디오 같은 멀티모달로 확장. 하지만 gaze는 action 예측에 충분히 활용 xx -> attention과의 상호작용이 시간에 따라 어떻게 함께 진화하는지 이해에 큰 공백 존재
-> 현재와 미래 모두에서 시선과 행동 간 양방향적이고 예측 관계 포착하는 통합 모델 필요함
3. ExoCook Dataset
Ego-Exo4D 데이터셋 - 시간 정렬된 설명 + 3D 자세, 시선, 객체 마스크와 같은 dense annotation 제공하지만 딥러닝 모델에 바로 사용하기는 힘듦
이 논문에서는 Cooking 도메인의 exocentric 비디오 사용. 658개 요리 비디오와 189,225개 텍스트 설명 추출 후 아래 전처리 수행
a) 인간 bbox - 3인칭 시점에서의 카메라와 전신, 멀리 bbox 검출
b) 객체 bbox - Ego-Exo4D 메타데이터에 포함된 인스턴스 마스크로부터 상호작용 가능한 객체들의 bbox 생성
c) 시선 히트맵 - 두 눈의 벡터 뽑아내서 3인칭 카메라 좌표계로 변환하여 투영 + 히트맵
d) spaCy 사용하여 텍스트 기반 행동 설명으로부터 가능한 명사, 동사 추출 후, 단순화된 주석에 BERT 적용하여 임베딩. 이후 Elbow Method로 결정한 K=10의 K-means 알고리즘으로 유사한 행동들을 10개 카테고리로 인덱싱&그룹화
e) 이러한 라벨들을 DeepSORT로 퀘적 추적
최종적으로 학습 25,650개, 검증 3,200개, 테스트 3,200ro qnsgkf
4. SAGE
짧은 비디오 클립 = 가 주어졌을 떄, 라벨 y를 예측하는 과제. M 스텝 이후의 미래 action 즉,
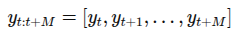
예측하고 이는 미래 gaze
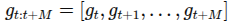
에 조건화 됨.

4.1 Gaze Detection
visual encoder랑 gaze fixation heatmap 출력 디코더로 구성.
1. 입력 비디오는 겹치지 않는 패치들로 분할된 뒤 flatten되어 linear mapping 통해 D 차원 임베딩 공간으로 투영. 이 토큰들이 self-attention 포함한 Transformer 레이어 처리.
시선 히트맵 생성하기 위해 MViT의 다중 스케일 self-attention기반한 Transformer 디코더 사용하여 T\` x H\` x W\` x D\` 의 맵으로 업샘플링한 후 softmax 적용하여 최종 시선 히트맵 을 얻음.
Egocentric 비디오의 경우 GLC 사용하고, Exocentric 비디오의 경우 (Chong et al. 2020) 아키텍처 채택. 해당 모델 사전학습 가중치 초기화.
GCSA(Gaze-conditioned Spatial Attention)
HOI 인식 모델은 p(|, ) 예측하여 현재 행동 를 gaze 와 비디오 특징 에 조건화하여 추정하는 것. 이미지 내 객체 j에 대해 bbox가 주어졌을 때 gaze-conditioned score 를 계산.
모듈 1에서 예측된 시선 히트맵을 gaze 분포 로 뒀을 때 시선 조건 점수를 아래와 같이 계산
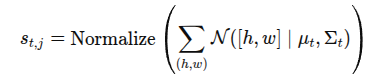
[h, w]는 객체 j의 bbox 내부에서 샘플링 된 좌표.
각 gaze-object 쌍에 대해 계산하고 모든 프레임에 시선 조건 점수 행렬 생성
이 점수가 Transformer의 Multi-Head Self-Attention 레이어에서 바이어스로 적용됨
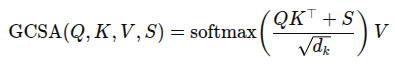
4.2 HOI Detection
spatio-temporal transformer를 HOI 검출에 적용. spatial, temporal encoder로 구성
spatial encoder는 인간-객체 가능한 상호 공간적 관계 이해함
spatial encoder는 아래를 입력으로 받음. egocentric 비디오의 경우 이며 는 프레임 t에서 검출된 객체의 개수를 의미
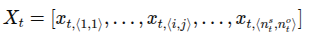
학습 가능한 토큰 를 추가해서 와 함께 스택하여 HOI 검출 모델의 입력으로 사용. 개의 MHSA 레이어 통과 후 각 토큰 간 관계를 로 표현
앞의 GCSA 모듈이 MHSA의 바이어스로 작용되며 통합. GCSA로 강화된 self-attention은 아래 식과 같음. 여기서 는 레이어의 개수임
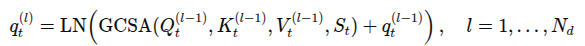
이후 에 대해 FFN 적용하여
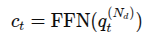
토큰 를 얻음. 이 토큰은 다양한 공간적 특징을 인코딩함.
시간적 모델링을 위해 프레임 수준의 전역 특징에 대해 cross-attention을 사용함. FaceFormer에서 제안한 PPE(Periodic Positional Encoding)을 토큰 에 추가하여
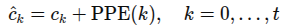
로 정의. 이후 MHSA레이어 적용하여 시간적 상관관계 암묵적 인코딩
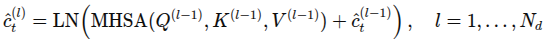
마지막으로 모델은 입력 시퀀스의 마지막 프레임에 대한 행동을 FFN 레이어에서 MLP레이어를 통해 예측하며, 아래와 같이 표현
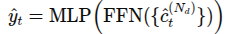
4.3 Gaze Anticipation
gaze 예측 모델로 입력비디오와 이전 인코더 출력 기반으로 미래 gaze 얘측하는 것. Transformer 기반. gaze estimation 로델로 받은 히트맵에 conv 적용하여 특징벡터 생성 여기에 PPE 더하고 디코더 거쳐서
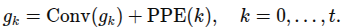
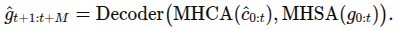
이렇게 형성
디코더에서 각 레이어는 아래와 같이 정의
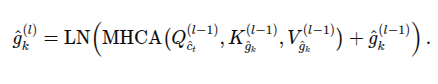
4.4 HOI Anticipation
action 과 미래 gaze 특징 사이 공동 시간적 의존성 모델링 하는 GCTP(Gaze Conditioned Temporal Prediction) 모듈 제안. 아래와 같음
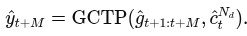
먼저 self-attention 적용해서 미래 gaze 인코딩 사이의 시간적 상관관계 인코딩. 이후 cross-attention적용해서 gaze와 action 특징간 상호갖용 학습 -> 암묵적으로 미래 action-gaze 관계 학습 아래 식 같이 됨.
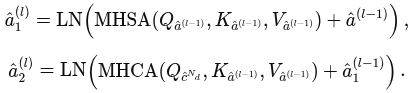
MLP 거쳐서 최종 형태
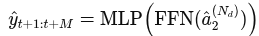
4.5 Adaptability across viewpoints
exo랑 ego랑 시점 분리되어서 연구했지만 여기서는 통합함.
먼저 feature encoding에서 인간-물체 쌍 생성하는 에서 인간과 물체 간의 공간적 관계 인코딩.
등등등... 내가 알고싶진 않음
4.6 Loss Function
gaze detection
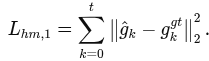
gaze anticipation
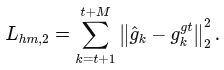
In-Out loss -> gaze 목표가 화면 안에 있는지 없는지. label이 제공되는 경우에만 적용
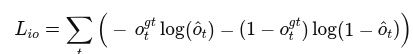
action loss
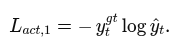
HOI anticipation loss
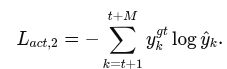
total loss
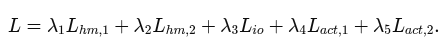
여기서 말하는 action은 Categorical label 즉, Ego-Exo4D에서 나온 행동을 k mean으로 10개 추려서 한 카테고리 ex) cut tomato 같은거 -> 뭐야... 그냥 카테고리로 예측하는거잖아 이미지 말고
시이발 ㅋㅋ... 바보네 나
