1. Abstract
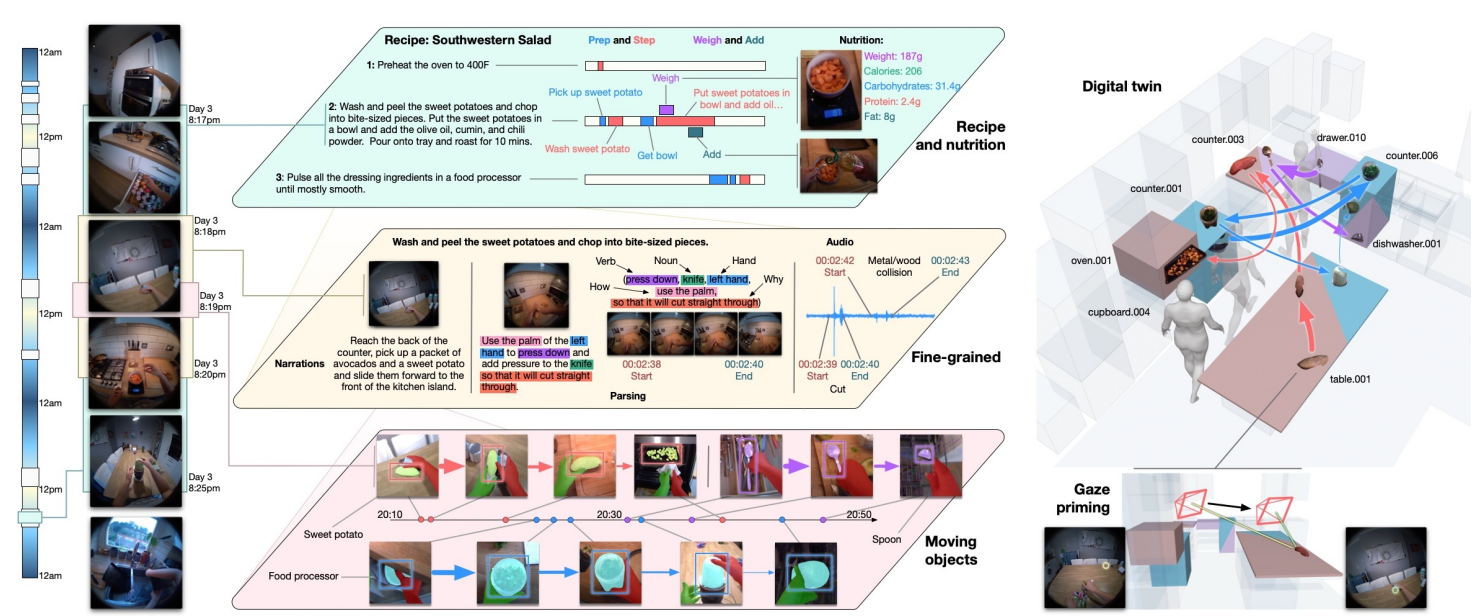
HD-EPIC egocentric 비디오 데이터 셋
- 41시간 영상, 9개 주방
- 69개 레시피
- 59K 행동, 51K 오디오 이벤트
- 20K 객체 이동, 37K 3D 객체 마스크
- 분당 평균 annotation -> 현존 egocentric 데이터셋 중 최고 밀도
**
- 레시피, 행동, 재료, 객체 이동, 오디오, gaze까지 초고밀고 멀티모달 주석
중요하게 볼 부분 - 내가 중점적으로 쓸 부분
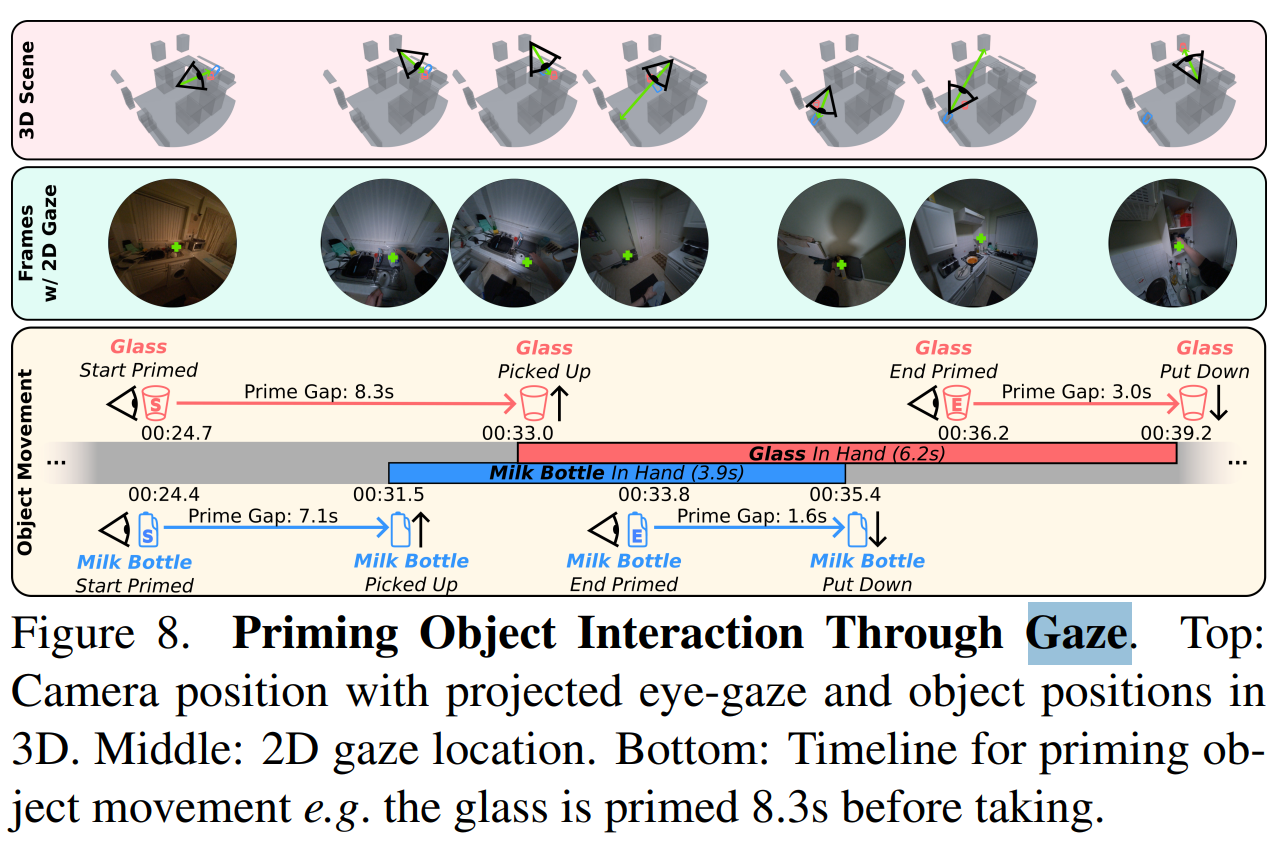
논문 Page 5에서
4.3 Digital Twins: Scene & Object Movements
Priming Object Movement.
The behaviour of gaze when picking up and placing objects is well-studied [32, 40]. We combine eye-gaze and 3D object locations, to find when an object is primed, i.e. the moment in time when the gaze attends to the object’s location before picking it up (pick-up priming) or when the gaze attends to the future location of an object before it’s put down (put-down priming). We calculate the priming time for all objects, excluding those taking or placed off screen. Additionally, at times, a person is already manipulating an object well before picking it up. We thus exclude objects with a pick up location lready close to the gaze 10s earlier. In Fig. 8 we show gaze priming for two objects: milk bottle and glass. The glass’s end location, a cupboard, is primed 3s before the glass is put away. Fig. 9 displays priming statistics. Of those objects feasible for priming, 94.8% are primed, an average of 4.0s before being picked up, compared to 88.5% primed an average of 2.6s before being placed.
-> 즉 객체에 대해서 pick and place를 하기 전 객체 위치에 시선이 향하는 순간(pickup priming) 또는 놓기 전 객체의 미래 위치에 시선이 향하는 순간.
화면 밖에서 집거나 놓는 객체 제외하고
집기 전 94.8% 객체가 priming 되었고 평균 4.0초 놓기전 프라이민됨.
놓기 전 88.5% 객체가 priming 되고 평균 2.6초 전
4.2 HD-EPIC vs Prior Egocentric Datasets
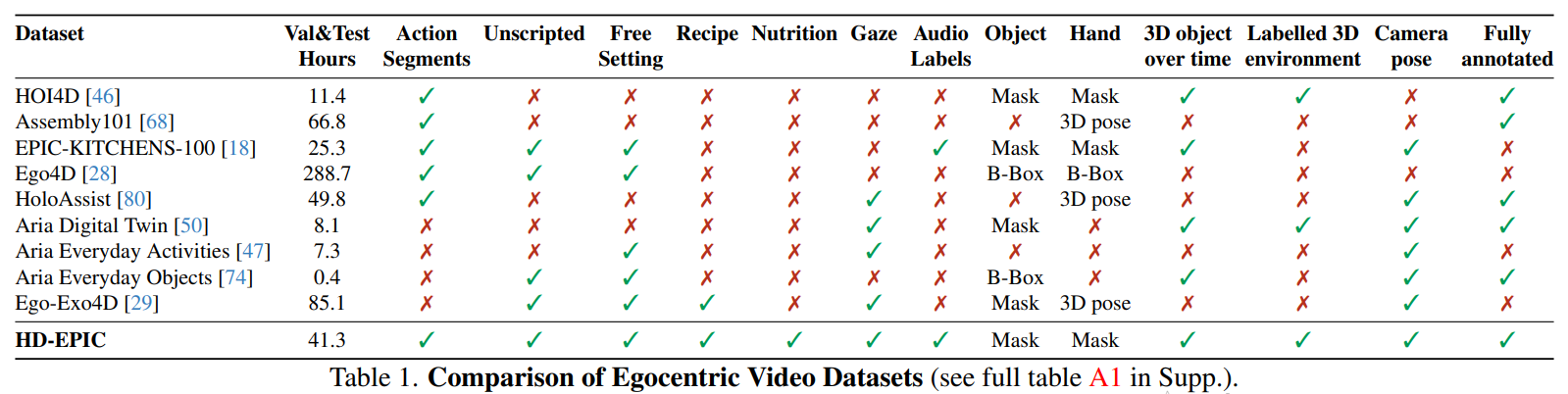
각본 없이 수집되었다는 것이 중요.
레시피, 영양정보, 상세 행동 구간, gaze, 오디오 라벨 다 포함.
표에서 봤을때, gaze랑 action segment 둘 다 있는 것 보면
HD-EPIC, HoloAssist 있음 근데 이건 조금 어려울 수도...
5.1 HD-EPIC VQA Benchmark and Analysis
- 미세행동(Fine-grained action): 행동의 what, how, why에 대한 질문과 그 시간적 위치 지정에 관한 질문
- Gaze: Large landmark에 대한 응시(fixation) 추정하거나 미래 객체 상호작용 예측 질문.
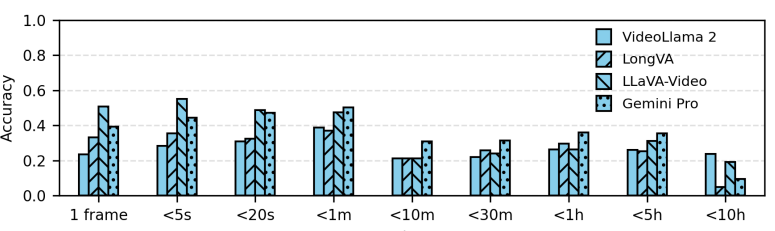
오픈소스 모델들 (Llama 3.2 90B / VideoLlama 2 7B / LongVA / LLaVa-Video / Gemini Pro)들이 다 못함.
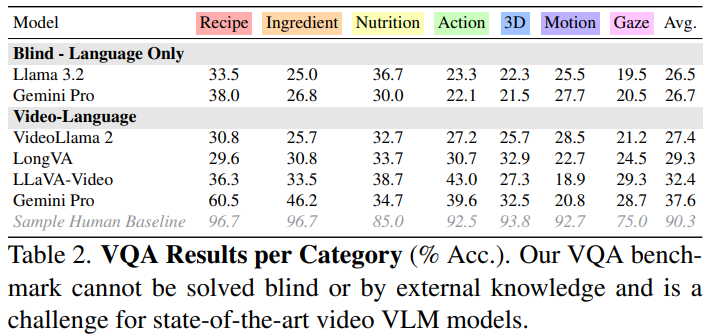
이 테이블에서는 이 논문에서 말하는 VQA Task가 오픈소스 모델들이 성능이 안 좋은것을 보아 도전적이라고 말함 - gemni pro가 가장 성능 좋긴 함
