Abstract
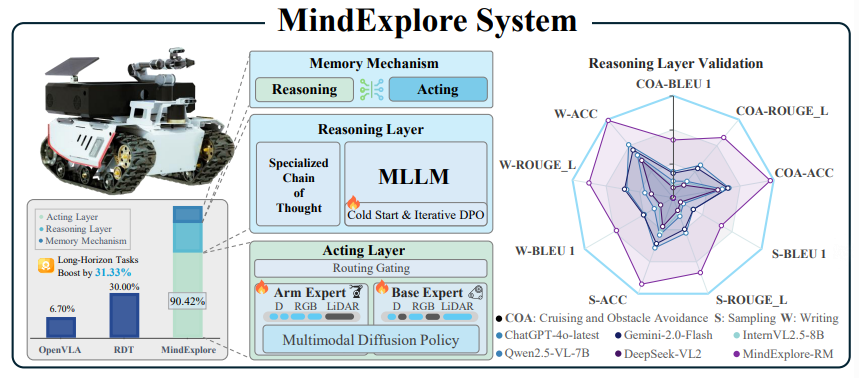
VLA는 단일 task에선 큰 발전 이루었지만 long-horizon 한계로 실제 적용 제한 - hierarchical VLA system MindExplore 제안
핵심은 task planning과 action execution의 지식 영역을 반복적으로 alignment 하는 것. -> 일반화 가능하게 함.
reasoning layer에서는 long-horizon 특화 CoT 설계됨
acting layer에서 closed-loop 생성 위해 MoPE(Mixture of Policy Experts)s 전략 사용. 또한 spatial 자각 향상 위해 MMDP(Multimodal Diffusion Policy) 통합됨
메모리 메커니즘은 추론 계층과 행동 계층 간 피드백 확립 -> adaptive execution & realtime replanning 가능ㅎ하게 함.
30FPS에서 기존 방법 대비 3.01배 높은 SR 기록
1. Introduction
현재 VLA는 짧은 시퀀스 작업에 초점 둠. 하지만 long horizon에서 일반화 실패. 따라서 deep consideration-Reasoning, precise control-Acting, adaptive feedback-Memory 필요. 이를 위해 아래 3가지 필요
- Task-oriented CoT
- High-Precision Multimodal Control
- Adaptive State Tracking
task planning과 action execution 사이의 지식 영역을 반복 정렬(iterative alignment) 하는 MindExplore제안
MindExplore는 CoT로 meta-action 시퀀스 포착.
Acting layer에서는 MoPE(Mixture of Policy Experts) 설계하여 closed-loop 생성
Memory Mechanism으로 추론과 행동 간 피드백 연결 구축
*센서 퓨전을 위한 경량 디퓨전 모델도 있지만 관심 밖이니 일단 패스
Expert 수준 멀티모달 데이터셋과 CoT 데이터셋인 SandGo-1k와 SandThink-21k 구축
Controbution
- MindExplore제안. Reasoning, Acting, Memory를 하나의 통합 아키텍처로 공식화한 최초의 연구
- 복잡한 환경에서의 이동 체화 지능 데이터셋 SandGo-1k 구축. 추가로 멀티모달 CoT 데이터셋 SandThink-21k 추가 구축
- 가파른 경사, 구덩이, 모래 언덕같은 24개 서로 다른 복잡한 작업에 대해 실험 & 성능 실증
2. Related Work
2.2 Embodied System
많은 연구들이 MLLMS이용해서 subtask로 분해하고 이를 경량 VLA가 실행하는 방식 채택하고 있음.(, Manipllm, RoboMatrix, llm-planer)
핵심 도전과제는 아래와 같음
- 지시를 어떻게 장기 시퀀스로 이해하고 결함 없이 실행할 수 있는가
- 복잡하고 동적인 지형에서의 이동과 조작을 어떻게 효과적으로 실행할 것인가
- 고도로 동적 장면 시뮬하기 어려우므로 데이터 결손 어떻게 해결할 것인가
3. The System Dataset
3.1 Embodied Dataset: SandGo-1k
불균일한 모래 지형에서 데이터 수집
아래 5가지 meta-action으로 작업 분해하고 재구성
- 목표 위치로 이동
- 장애물 통과
- 지정된 객체 집기
- 객체를 지정된 컨테이너에 놓기
- 쓰기
센서정보, 로봇 state, command, 텍스트 지시 가 포함됨
3.2 CoT Dataset: SandThink-21k
효과적 작업 수행을 위해 목표 이해, 서브골 분해, 정확한 행동 시퀀싱 필요. 그러나 기존 방법들은 long-horizon 작업 결정 위해 구조화된 추론 메커니즘 부족한 경우 많음. -> 행동 생성 이전 deep reasoning (내 논문에서는 이 부분에 gaze를 넣어보는게 어떨까..) 가능하게 하는 CoT 추론 데이터셋 도입. 아래 4개 구조 따름
- 목표 설정
- 서브골 분해
- 행동 시퀀스 생성
- 행동 시퀀스 모델링
이런 단계를 명시적으로 구조화 해서 단편적인 계획 완화. 전용 태그 부여 "goal explanation" 같은거
4. The MindExplore System
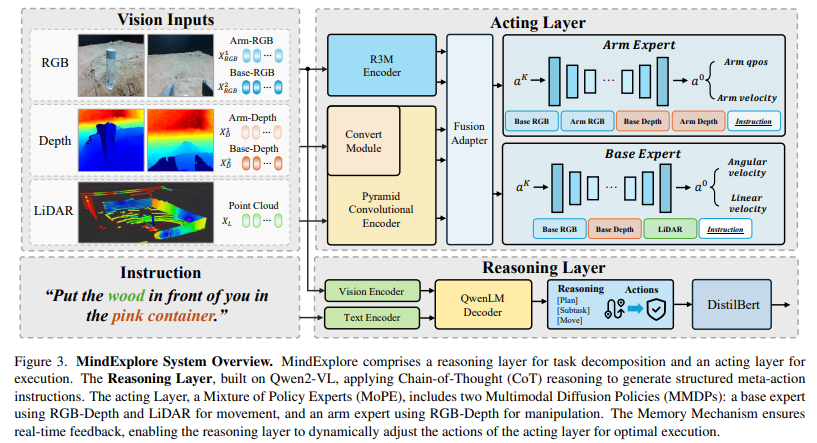
4.1 Reasoning Layer
long-horizon 작업 추론 능력 향상 위해서 cold start 이후 iterative direct preference optimization(DPO: 모델이 두 가지 답을 내놓으면 그중 더 좋은 답을 선택하도록 유도해서 모델의 preference 맞추는 기법)으로 구성된 2단계 학습 전략 사용함.
4.1.1 Cold Start with Curriculum Learning
SigLIP 사용해서 이미지와 텍스트 지시를 feature space에서 매칭함. 이 과정에서 로봇이 이동하면서 진동으로 인한 흐린 이미지 데이터를 필터링 한 후 Qwen2-VL-7B-Instrucct 모델의 모든 linear layer를 LoRA 사용해 cold start 방식으로 학습.
이 단계는 이미지와 instruction이 주어졌을 때 추론 결과 생성확률 최대화 하는 단계 이미지 입력이 , instruction 입력이 로 나타낼 때 목적함수는 아래와 같음
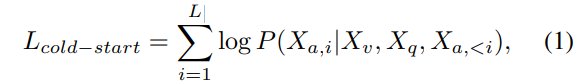
은 추론 출력을 나타내며 L은 길이 의미.
-> 정답 행동이 아니라 추론 과정을 생성하는 데 초점을 둠
학습은 Curriculum learning 사용해서 데이터를 쉬운 것(구조화된 복잡 표면 데이터) -> 어려운 것(실제 모래 환경) 순으로 확장하며 순서 배열
추론 능력 습득 후 더 복잡한 작업으로 전이하도록 보장함.
4.1.2 Enhancing Reasoning with RL
Cold start로 구조화된 추론 확힙 이후 강화학습은 모델 추론 품질 정제하는 데 사용됨. Iterative DPO 사용하여 결정 능력 최적화 시킴. 이미지 I와 작업 지시 Q가 주어지면 모델은 하나의 추론 체인 R생성함. DPO는 Bradley-Terry(BT) 모델에 기반
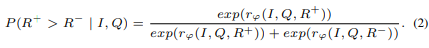
는 파라미터화된 보상 모델, , 는 각각 선호 비선호 추론 시퀀스 의미.
policy 모델 는 선호된 정렬 추론을 최대화 하도록 학습되며 reference model 는 학습 과정 안정화 위해 사용됨. 초기 목적함수는 아래와 같음 - (이걸로는 학습 안 시킴)
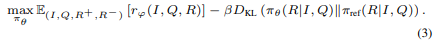
수식 의미는 추론 점수 - x KL다이버전스(기존 모델에서 벗어난 정도)
학습 안정화를 위해 supervised fine-tuning 손실 또한 함께 포함. 는 모델의 학습 가능 파라메터 의미, 는 선호된 추론 시퀀스의 길이 의미. - (이 수식으로 policy 학습시키는데, 여기서 를 바꿔가면서 학습)
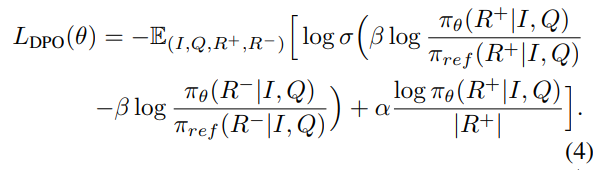
와 의 상대적 확률 격차 키우는 방식
고품질 preference data 구축 위해 3개의 반복학습 통해 선택 과정 정제. 각 task반복 단계에서 8개의 추론 출력 샘플링하고, GPT-4o 사용하여 0부터 100사이의 점수로 순위 매김.
DPO에서 선호도 평가 할 때 GPT 사용 하지만 GPT의 경우 reasoning 저하 될 수 있어서 아래와 같은 iteration 사용
Iteration 1: 가장 높은 점수를 , 가장 낮은 점수를 로 선택
Iteration 2: 점수가 60 미만인 응답 중에서 가장 높은 순위를 로 선택하여 작업 난이도 증가
Iteration 3: 점수가 60 이상인 응답 중에서 가장 낮은 순위를 가진 응답을 로 선택하여 모델이 fine-grained reasoning distinctions을 학습하도록 함. -> 이러한 접근법이 모델이 구조화된 멀티모달 추론과 long-horizon planning에서 뛰어난 성능 발휘하게 함.
4.2 Acting Layer
Acting layer는 manipulation 파라메터 집합 생성 - diffusion model 사용. 이미지에 비해 훨씬 작기 떄문에 빠른 생성 속도, 동적 변화 대해 실시간 피드백 제공 가능
4.2.1 Multimoldal Diffusion Policy
대부분 VLA는 단일 모달 데이터만 사용하여 복잡한 조작에 한계 있음.
큐브, 모래 지형 사이 색상 유사성 같이 RGB 이미지는 노이즈 있음.
depth나 포인트 클라우드 데이터 기반은 장면 세부 정보 인식 능력(semantic & alignment) 부족 -> 멀티 모달 MMDP 제안.
R3M(로봇 manipulation 시각 인코더 - Ego4D 즉, 인간 데모 비디오로 pretrain된 인코더). RGB랑 depth 이미지를 concatenation 하는 대신 포인트 클라우드 데이터로 변환.
iDP3에서 사용된 피라미드 합성곱 인코더 사용해서 포인트 클라우드 인코딩, 텍스트는 DistilBERT 사용하여 인코딩.
이 센서와 텍스트 모두 2 linear layer 구성된 fusion adaptor 사용하여 같은 feature space로 묶기.
MMDP의 mainpulator 파라메터는 conditional denoising diffusion model에 기반함.
무작위 가우시안 노이즈 샘플링 뒤, RGB 데이터 r, depth d, LiDAR p, 명령 데이터 i, 로봇 상태 q를 디노이징 입력으로 두고, 네트워크 로 파라메터 복원
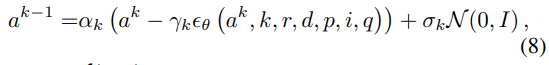
는 의 함수 - 노이즈 스케줄러에 의해 결정됨. Loss func은 아래와 같음
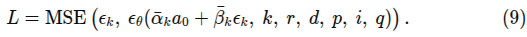
4.2.2 Mixture of Policy Experts
Acting Layer은 환경 변화 피드백 제공 필요있음.
통합된 단일 조작 모델과 raw sensor input이 간섭 일으킬 수 있다고 주장 -> base와 arm 조작 분리(decouple)하는 Mixture of Policy Expert Model 제안
Base expert는 base의 linear, angular velocity 출력. 입력은 RGB, depth 1.5m 이하인 base point cloud, 수평 반경 1.2m 이내의 LiDAR point cloud
Arm expert는 pose 및 속도 파라메터 출력. 입력은 base camera, arm camera 양쪽 RGB 이미지, 0.8m 이하의 base point cloud 데이터, depth 0.5m 이하인 arm point cloud (wrist camera)
4.3 Memory Mechanism
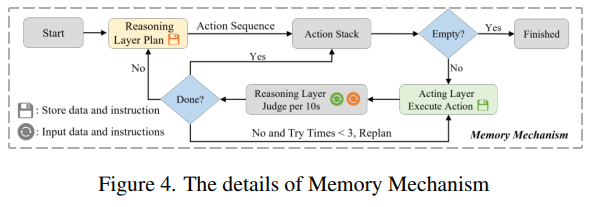
Reasoning Layer와 Acting Layer 간 coordination 강화, global control 달성 위해 real-time feedback, gated routing 갖춘 Memory Mechanism 제안.
Fig 4에 나온것처럼 instruction 들어오면 전처리 후 - reasoning layer로 전달 된 후 meta-action 시퀀스 생성. 이후 gated routing 네트워크는 각 meta-action을 순차적으로 해당하는 VLA action expert에게 할당. 멀티모달 센서 데이터도 동시에 action expert에게 전달되어 제어 파라메터 생성.
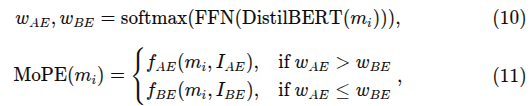
는 단일 meta-action 의미. , 는 각각 arm, base expert가 요구하는 멀티모달 센서 입력 의미.
이때 메모리 메커니즘은 Reasoning Layer가 최초로 수한 다중 시점 RGB 이미지 저장하고 제어 파라메터 생성 동안 robot state를 acting layer에 되돌려 제공 - 실식간 조정 가능. 과거랑 현재 RGB 이미지를 Reasoning Layer에 제공하여 meta-action 완료 팓단하도록 multi-temporal 환경인식을 부여.
meta action이 성공하면 다음 action을 acting layer로 전달. 실행 중 오류 -> Reasoning Layer가 전체 작업을 replan하도록 트리거하여 새로운 meta action sequence 생성함.
6. Conclusion
Reasoning, Acting, Memory Mechanism으로 구성된 long-horizen 작업 위해 섫계된 시스템 제안. planning과 action 정렬함 - 동적 환경에서 일반화 성능
