Abstract
로봇 action label 없는 인터넷 규모 비디오 데이터로부터 학습할 수 있는 방법 제안
VQ-VAE 기반 이미지 프레임 사이의 discrete latent action 학습하는 action quantization model -> observation, task description부터 latent space 에측하는 VLA 사전학습 -> 소규모 로봇 manipulation 데이터로 VLA 파인튜닝 latent space -> real robot action 매핑 학습
인간 조작 비디오만을 사용한 학습에서도 긍정적인 전이 효과가 관찰되었으며, 이는 웹 규모 데이터가 로보틱스 파운데이션 모델에 활용될 가능성을 열여줌.
1. Introduction
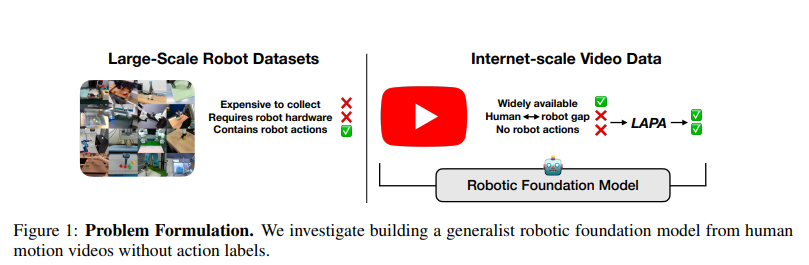
로봇 데이터셋 파인튜닝 필요 -> scale up 어려움, 인간 시연은 action label없고 로봇 시스템과 다름
Latent Action Pretraining 제안 - robot action label 없이 FM 학습시키기 위한 unsupervised learnning
1. VQ-VAE 기반 목적함수 사용 - 이미지 프레임 사이의 quantized latent space 학습. - EE 같은 action priors 학습 안하고 atomic actions 토큰화 하는법 학습
2. 1에서 학습한 latent space 예측하게 Vision-Language 모델 pre-training - BC 방식으로 수행.
3. 소규모 로봇 manipulation 데이터셋으로 학습
-> LAPA
action label없이 학습한 기존 방식들보다 좋고 다양한 데이터 셋으로 학습된 OPENVLA보다 좋음 -> 다양한 embodiment에 대해 unified quantized latent action representation을 학습하는 것이 효과적임을 보여줌
LAPA가 객체 및 카메라 움직임을 포함한 environment-centric action을 효과적으로 포착 - 네비게이션 포함한 것에도 효과적일수도
아래는 주요 contribution
- 웹 규모 비디오 데이터로부터 로봇 기술 인코딩하기 위한 로봇 파운데이션 모델을 사전학습하는 unsupervised 접근법인 Latent Action Pretraining 제안
- 시뮬 및 실제 로봇 과제에서 실험에서 기존 라벨 없이 학습하는것 + 라벨 있이 학습된 VLA보다 6.22% 더 높은 성능 -> 30배 이상의 사전학습 효율 달성]
- LAPA를 action 예측 모델로 사용하고, latent action quantization 모델의 decoder를 world model로 사용하여 현재 관측과 LAPA가 예측한 latent space에 조건화된 미래 프레임 예측 -> 신경망 추론으로만 closed-loop 평가 수행 가능 신경 시뮬 구축
2. Related Works
기존 방법들은 전부 로봇 action label이 있었음.
-> 정답 action이 아니라 observation으로부터 직접 latent action 도출
3 LAPA: Latent action pretraining for general action models
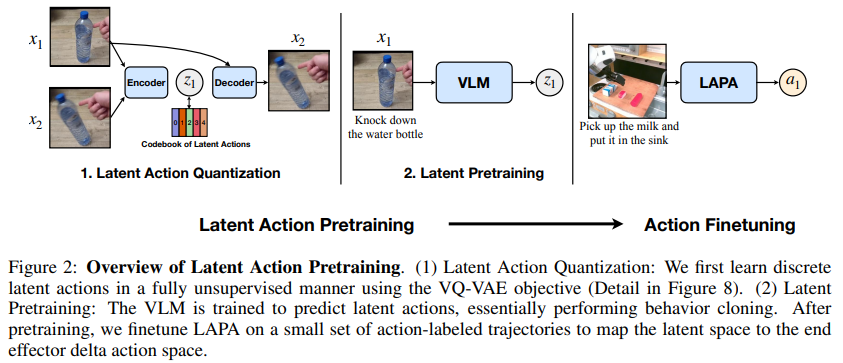
Latent Action Pretraining은 순차적으로 학습되는 두 개의 모델로 구성
Latent Action Quantization과, Latent Pretraining. 둘 다 동일한 pretraining dataset 사용
3.1 Latent Action Quantization
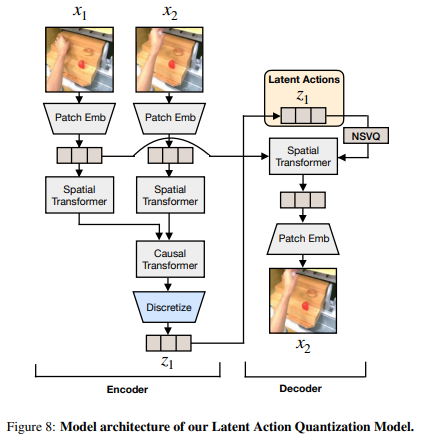
latent action quantization model은 인코더-디코더 구조로 이루어져있음. 는 고정
인코더: 비디오에서 현재 프레임 와 미래 프레임 를 받아 latent action 출력.
디코더: 와 를 입력으로 받아 재구성하도록 학습
기존 방식과 다르게 를 기준으로 에 cross attention 사용 - 의미 있는 latent action 포착 도움됨.
quantization 모델은 C-ViViT tokenizer의 변형으로 인코더는 spatial 트랜스포머와 temporal 트랜스포머 모두 포함, 디코더는 spatial만 포함. 입력이 두 개의 이미지 프레임만 사용하기 때문
latent action quantization training 모델은 VQ-VAE objective 기반. 각 임베딩은 codebook에 대응 -> VLM이 예측 쉽게 함
latent space는 크기의 vocabulary space에서 길이 갖는 시퀀스로 표현. 는 VQ 직전 사용되는 CNN 네트워크의 커널, 스트라이드, 패딩에 의해 결정됨.
-> 그럼 VAE구조는 생각보다 CNN 구조일거 같긴 함. 이게 일반화 될까?
VQ-VAE에서 자주 발생하는 gradient collapse 방지 위해 NSVQ 사용. representation collapse 피하기 위해 디코딩 과정에서 의 패치 임베딩에 stop-gradient 적용. 초기 학습 단계에서는 codebook 활용 극대화 하기 위해 NSVQ의 codebook replacement 적용.
모델과 학습 세부는 Appendix A에 제시
latent aciton quantization 모델에서 encoder를 IDM(inverse dynamics model)로 사용, decoder를 neural-based closed-loop rollouts을 생성하는 데 사용
-> 디코더에서 closed-loop rollbout의미는 한번만 예측하는 것이 아니라 예측한 결과를 다시 입력으로 넣어서 계속 미래생성하는 것
3.2 Latent Pretraining
인코더를 IDM으로 사용함. 이 주어졌을 때 모든 프레임 가 주어졌을 때 latent action 를 레이블로 부여함. 그 후 사전학습된 VLM사용하여 비디오 클립의 laungauge instruction과 현재 이미지 가 주어졌을 때 예측하도록 action pretraining 함.
VLM의 language model head 사용하는 대신 Vocab size가 인 별도의 latent action head(단일 MLP) 추가. 학습 중 비전 인코더만 freeze하고 언어 모델은 unfreeze 하도록 설정
latent pretraining은 GT에 의존하지 않기 때문에 어떤 형태의 raw video 사용 가능성 염. + 로봇에 사용하는 action granularity(행동 단위 - EE pose, joint state 등등) 없음
-> 비디오 데이터셋에서 연속된 관측들 사이의 delta(변화)를 포착하도록 최적화 하는 과정 E2E 학습 -> LAPA
3.3 Action Finetuning
pretraining VLA는 로봇에서 실행 못시킴. -> 소량 데이터셋사용하여 파인튜닝
로봇의 각 action space에 대해 discretize함. 이때 각 bin에 해당하는 데이터 포인트의 수가 동일하도록 설정
latent action head(단일 MLP)를 제거하고 이를 정답 action을 생성하기 위한 새로운 action head로 대체. 위와 마찬가지로 비전 인코더 freeze, 언어모델은 unfreeze
Experiments
Latent Action Pretraining 효과 입증
1. 사전학습과 파인튜닝 사이에 cross-taskm cross-environment, cross-embodiment 격차가 존재할 때 LAPA가 어떤 성능을 보이는지
2. multi-embodiment 설정에서 GT actions 사용하는 방식과 비교했을 때 더 우수한 지식 학습하는지
3. 인간 데모만을 사용하여 더 성능 좋은 LAPA 생성 가능한지
4.1 벤치마크, 환경
2개 시뮬 +3개 리얼월드
9개 과제 카테고리에서 LAPA 성능 평가
- Language Table(시뮬): 2 Dof 로봇이 미는 작업. 5개 하위 과제. seen, unseen 모두 평가
- SIMPLER(시뮬): 7 Dof Windowx, 4개 평가. BridgeV2 기반 VLA롤아웃으로 100개 궤적 수집
- RealWorld: 7 Dof Franka Panda 3개 환경. 사전학습 데이터 - BridgeV2, Open-X, Something-Something v2. 물체 집어 싱크대 넣기, 수건 덮기, 물체 넘어뜨리기 3개 task. 각 과제 15개 객체 x 150개 궤적. 부분 SR로 평가
4.2 Baselines
공통 백본 - 7B LWM-Chat-1M VLM 사용
- SCRATCH: 사전학습 없이 다운스트림 태스크로만 파인튜닝 - 사전학습 효과 비교용 베이스라인
- UNIPI: 사전학습 시 비디오 diffusion으로 롤아웃 생성 (행동 label 불필요), 파인튜닝 시 IDM으로 실제 action 추출. diffusion 모델도 다운스트림에 맞춰 추가 파인튜닝
- VPT: action label 데이터로 IDM 학습. IDM으로 원시 비디오에 pseudo action 생성. 이 pseudo action으로 VLM 사전학습
- ACTIONVLA: 실제 로봇 정답 사용하여 사전학습 - upper band 역할
- OPENVLA: SOTA 로봇 데모 학습 모델. 7B, 로봇 실험에서 파인튜닝 후 비교
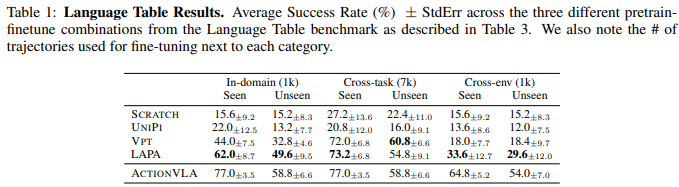
4.3 Language Table Results
-
In-Domain Performance
적은 행동 label만 사용. UNIPI는 긴 task 실패. VPT는 LAPA보다 안좋음
-> latent action 자체가 action 없는 사전학습에서 매우 강력한 supervision 역할 -
Cross-Task Performance (한 task로 파인튜닝 -> 다른 task 유지?)
LAPA는 파인튜닝 안한 task들에서도 성능 유지 -
Cross-Environmnet Performance(real -> sim)
LAPA가 다른것들보다 환경에 강인함
4.4 Real-Word Results
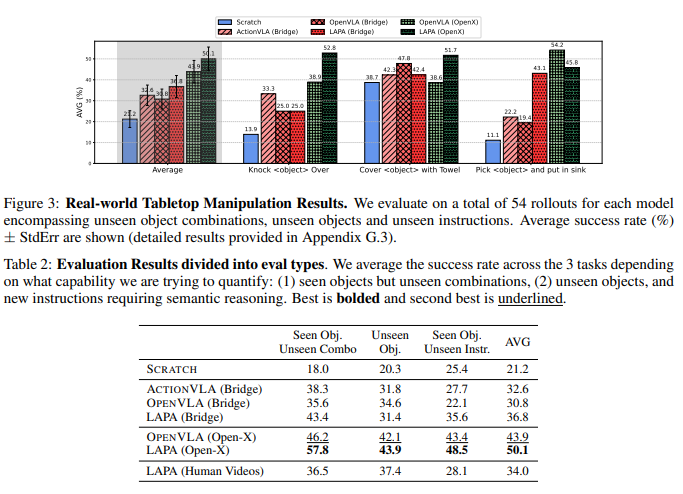
4.5 Learning From Human Manipulation Videos
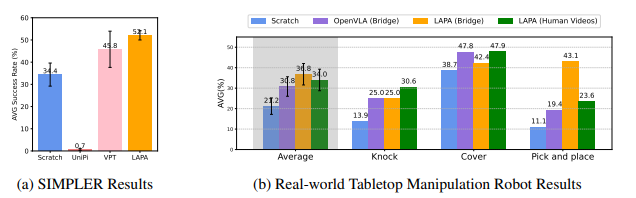
5. Ablation and Analysis
5.1 Scaling Model, Data, And Latent Actions Size
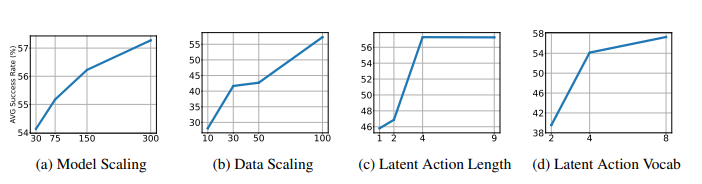
5.2 Latent Action Analysis


6. Limitations and Conclusions
정답 행동 label 사용 안하고 VLA 구축 제안
grasping 같은 미세한 동작 요구 과제에서는 떨어짐 latent action space 확장으로 개선 가능할 듯
real-time 문제 -> 더 작은 헤드가 높은 주파수 행동 예측하는 계층적 아키텍쳐 도입
