Abstract
long horizon, multi-step 문제. 작업과 관련된 상호작용 단서 식별하거나 subtask 내에서의 진행 상황 추적하는 내부 추론 메커니즘이 부족.
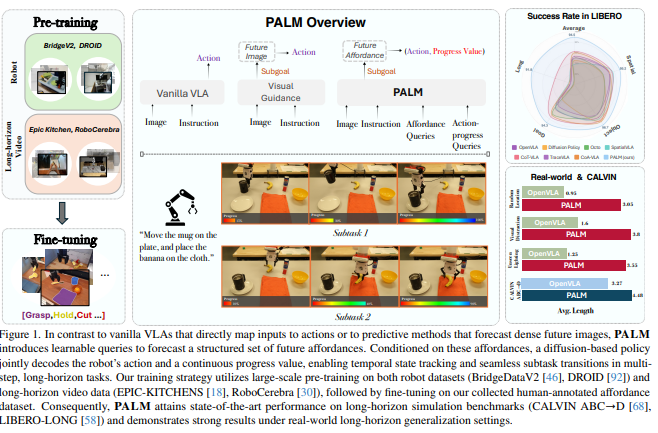
interaction-centric의 afforance 추론과 subtask 진행 신호를 중심으로 policy 학습 구조화한 VLA인 PALM 제안
객체 관련성, contact geometry, spatial placement, motion dynamics를 포착하는 상로 보완적이인 affordance distill. 시각-운동 제어를 위한 작업 관련 anchor로 작용
subtask 내부에서 진행 정도 예측하여 작업간 매끄러운 전환 가능하게 함.
1. Introduction
기존 VLA의 long horizon task의 실패 원인은 structured affordance cues, explicit state tracking의 부재에 있음.
기존 모델들은 최종 목표를 추론하고 중간 행동을 생성할 수 있지만
다음 단계에서 어떤 객체를 목표로 삼아야 하는지, 상호작용에 있어 어떤 부위나 영역이 중요한지, 물체를 어디에 배치하거나 이동시켜야 하는지, 다음 단계에 어떤 동작이 적절한지를 구분해 줄 수 있는 내부 표현이 없음
-> 이 부분은 내 논문 reference로 쓰면 좋을듯
기존 모델들은 substask 내부에서 진행 상황을 지속적으로 추정하는 메커니즘 부재. - 온라인으로 유지되는 명확한 진행 개념이 없음
temporal grounding의 부재 -> long horizon에서 실패 원인
-> PALM 제안
perception, action, progress를 closed loop 내에서 통합
1. affordance를 latent queries 형태로 예측
-> 4가지 형태. object relevance, contact -level geometry, candidate placement regions, plausible motion trajectories
2. 하위 작업 진행도 추정
action은 diffustion transformer사용. 행동 시퀀스와 진행 시퀀스 공동 예측.
먼저 로봇 데이터셋과 장기 비디오 데이터 사용하여 사전학습. -> 로봇 궤적 데이터로 파인튜닝
주요 contributions
- Introduce PALM - intergrating structured affordance reasoning and progress-aware policy generation -> long-horizon tasks
- Two complementary modules. 1) affordance 예측기, 2) a progress-aware inverse-dynamics module(IDM)
- 시뮬, 실제 성능 향상
2. Related Works
그닥 살펴볼 내용 없음
3. Method
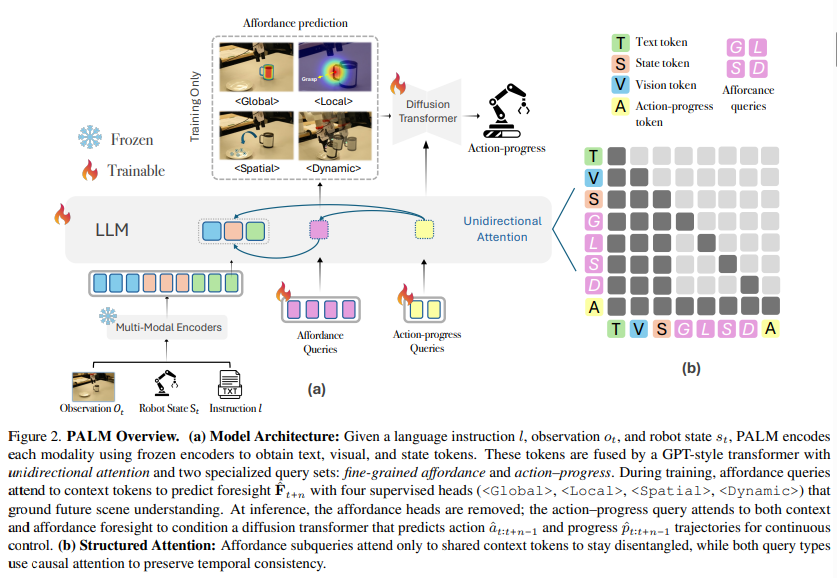
3.1 Problem Formulation
여러 누적된 노이즈로 인해 관측 공간을 변화시킴. sub-policy들이 각각 학습된다면 하나의 종료 상태가 다음 단계의 기대 시작에서 자주 벗어남. -> 기존의 BC는 를 직접 fit하게 하여 다른 단계들을 붕괴시켜 rollout중 반복되거나 누락되는 subtask 발생시킴
따라서 PALM에서는
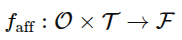
1. 에서의 affordance 예측 모델
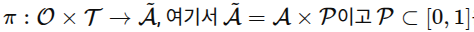
2. 는 progress로 action이 (행동, 진행도)의 형태로 출력. -> subtask의 단계 모호성을 완화하는 시간적 정규화 역할 수행
3.2 PALM Architecture
Multi-Modal Encoders
언어명령 , 이미지 관측 , 로봇 상태 입력
instruction은 CLIP 텍스트 인코더 사용하여 임베딩.
observation은 Masked Autoencoder로 인코딩된 후 Perceiver Resampler를 통해 다운샘플링 되어 task와 관련된 시각 토큰 유지.
robot state는 MLP를 통해 투영.
시간 인덱스 와 함께 하나의 시퀀스로 연결되어 트랜스포머 백본에 전달됨
Backbone and Learnable Queries
백본은 GPT-2스타일 트랜스포머 - causal and cross-modal attention
이 백본 위에 PALM은 learnable query set을 도입. affordacen & progress-aware policy
Fine-grained affordance queries
< Global >, < Local >, < Spatial >, < Dynamic > 의 하위 쿼리로 구성. 위 멀티모달 token 전반에 attention하여 작업 관련 표현 추출, affordance 중심 latent 생성
Action-progress queries
제어와 관련된 컨텍스트 풀링, 에 조건화되어 inverse-dynamics 디코딩 지원. - 이 쿼리들은 현재 관측과 예측된 affordance latent 표현을 집계하여 예측된 상호작용 상태와 정렬된 행동 시퀀스 추론
Decoders
디코더는 디노이징 diffusion trasnformer로 구성. 길이 n의 궤적 생성
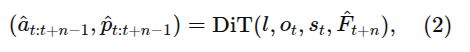
3.3 Fine-Grained Affordance Prediction
Global Prediction
global affordance는 장면 내에서 어떤 객체가 instruction이랑 관련이 있는지, 그리고 그 객체가 어디에 위치하는지를 식별하는 고수준 semantic prior를 제공. 명령이 주어지면 시점에서 object-centric 정보를 예측. 이 정보는 이후 모든 affordance 단서를 anchor함.
이 부분에서 차이점 있을 듯. 여기서는 Grounding DINO + SAM 사용 == 부가적인 모듈 필요
Grounding DINO와 SAM 사용하여 mask얻음. 해당영역에 이미지 인코더 더해 masked pooling 수행하여 객체 추출. 아래는 학습 loss func
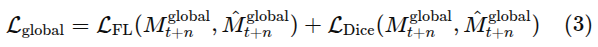
-> 그냥 시점에서 예측된 mask와 이미지 위의 마스크 비교해서 픽셀단위 loss, soft Dice loss 한 것.
Local Prediction
contact reasoning에 필요한 local affordance 단서 포착
contact-likelihood 분포 예측 - GLOVER++ 따라서 가우시안 히트맵 변환

사진과 같은 방법인듯
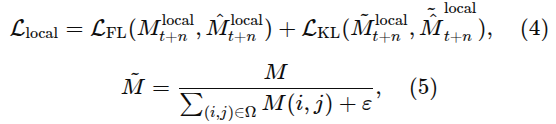
Spatial Prediction
시점에서 객체를 놓을 수 있는 그럴듯한 영역 나타내는 후보 배치 지점 예측. 정답 타겟은 SpatialVLM 사용하여 sptial semantics로 변환 후 RoboPoint 이용해 2차원 좌표 샘플링
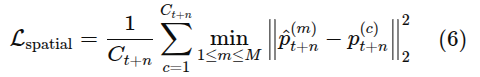
Dynamic Prediction
로봇 그리퍼와 이동 가능한 객체에 해당하는 픽셀 식별 + 시간에 따라 어떻게 변할까 예측. grid-based traking 적용
CoTracker 사용하여 포인트 추적
에서 에서 그리퍼나 이동 물체에 속할 가능성이 높은 픽셀들을 강조하는 미래 동적 확률 맵 예측
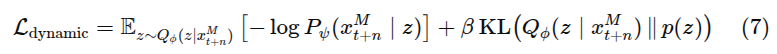
Progress-aware Policy via Inverse Dynamics
진행도 예측 과제 도입. action과 동시에 예측 - 장기 제어에서 모호성 줄임
에 조건화되어
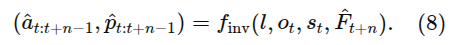
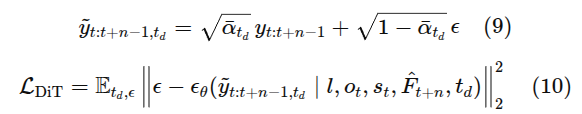
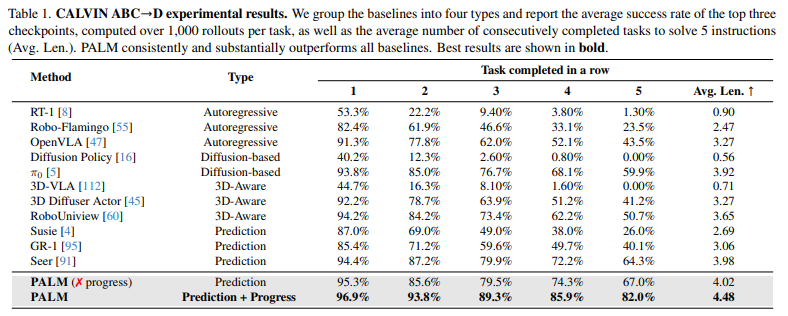
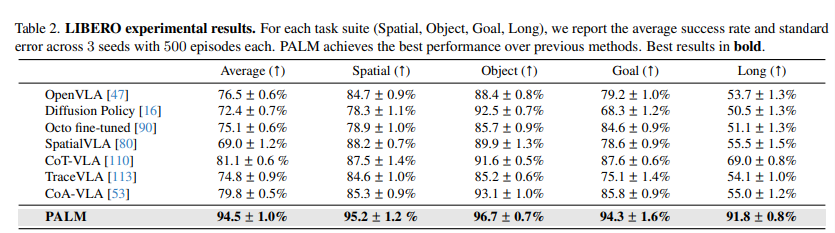
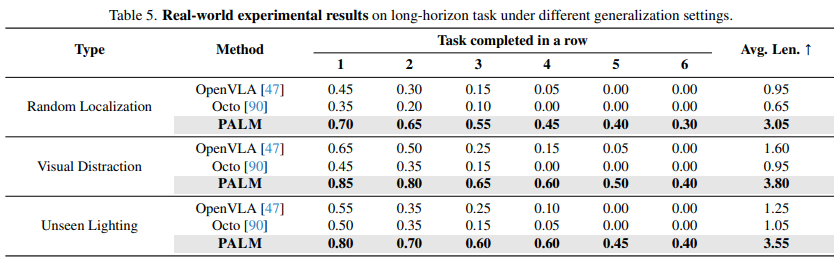
4. Experiments
pre-training + fine-tunning 두가지로 구성
pre-training에서는 DROID, BridgeData V2 데이터셋 혼합 - 실제 환경 로봇 팔 시연 데이터
EPIC-KITCHENS와 RoboCerebra - 장기, 접촉많은 시나리오 추정 학습