중복값 유무 확인하기

df.dulplicate() 함수를 써서 중복값이 있는지(True) 없는지(False) 확인하며, 처음 나온 값을 중복값이라고 여기지 않고 2번째 나오는 값들부터 중복값이라고 여긴다. 그리고 삭제할때도 첫번쨰 값은 두고 두번째 이상부터 삭제한다(복수여도 상관없음. 첫번쨰 값만 냅두고 두번째 이상부터 중복값들은 다 삭제)
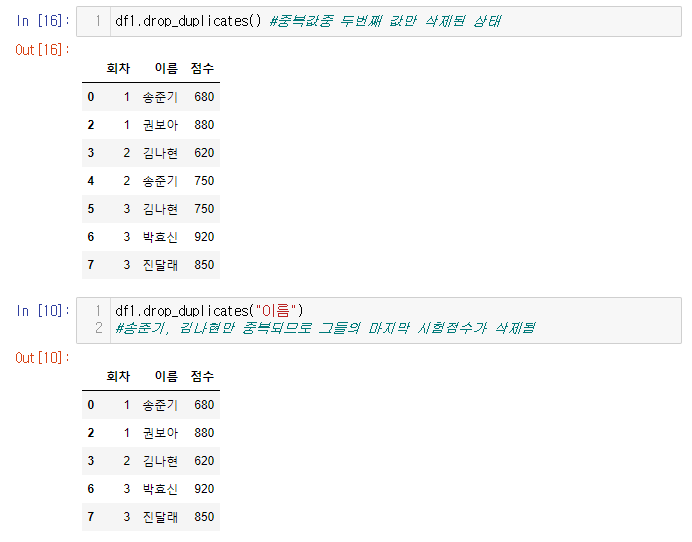
중복값 제거하기
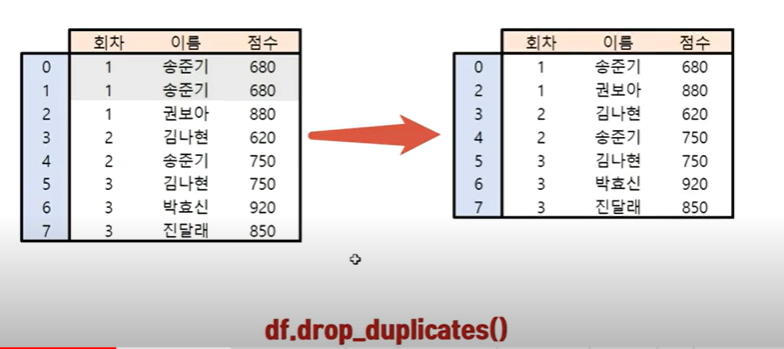
df.drop_duplicates() 함수를 사용하여 중복값 간편하게 제거
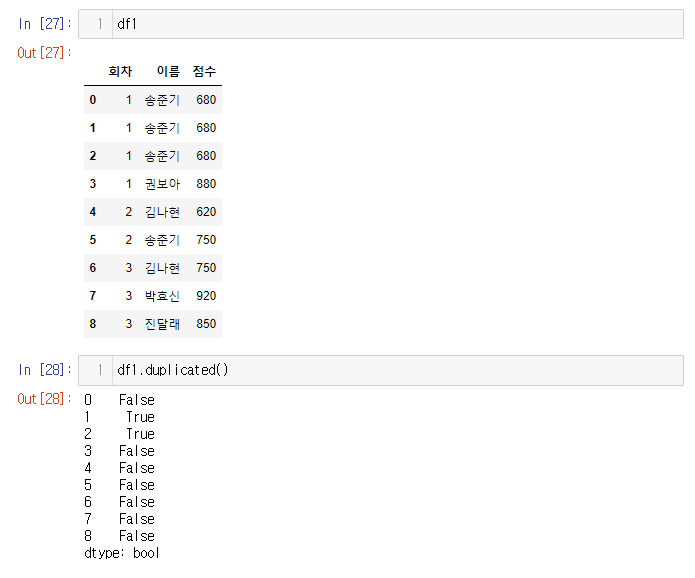
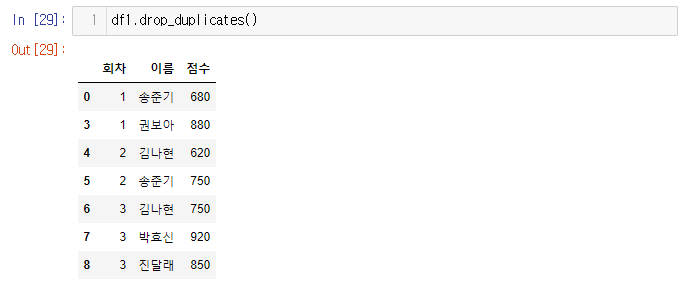
- 첫번째 송준기만 제외하고 2번째 3번쨰 중복값들은 사라짐
특정열의 중복 제거 하기
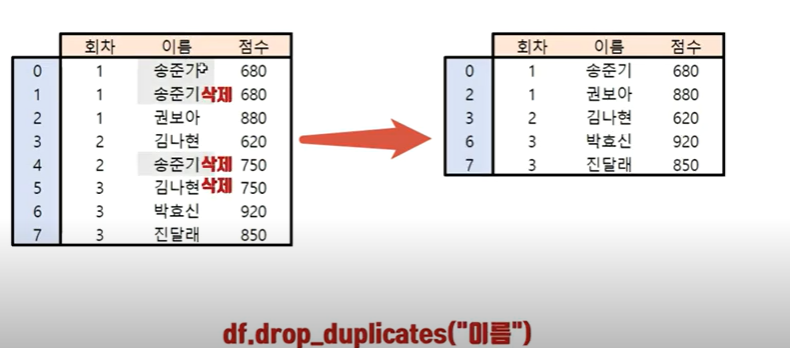
df.drop_duplicate("이름")
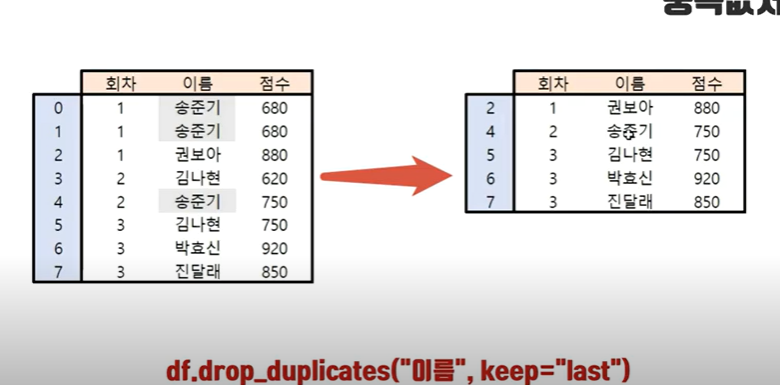
keep 파라미터를 사용하여 마지막 점수만 제외하고 중복값으로 인식하여 제거 할수도 있다
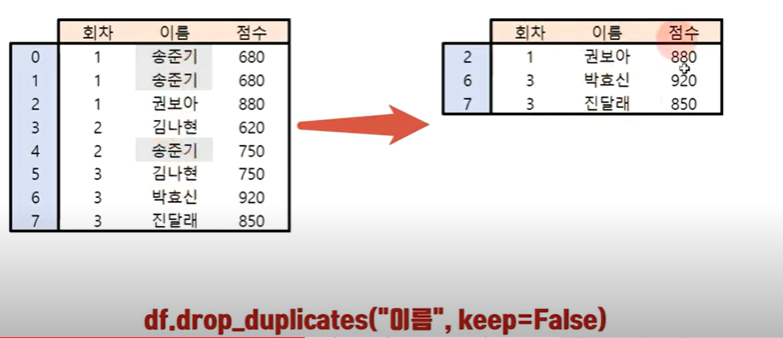
keep을 false로 설정하면 중복값이 있는 요소는 다 날라가게 할수도 있다. 즉 이값은 시험을 한번만 본 사람을 나타내는 표로 해석된다.
오늘의 목표
- 중복값 존재 여부 체크 duplicate >t,f
- 중복값을 처음값만 두고 삭제한다 drop_duplicate
- 중복값을 마지막 값만 두고 삭제한다 keep="last"
- 중복값을 모두 삭제한다 keep=false
1. 판다스와 데이터 프레임 살펴보기
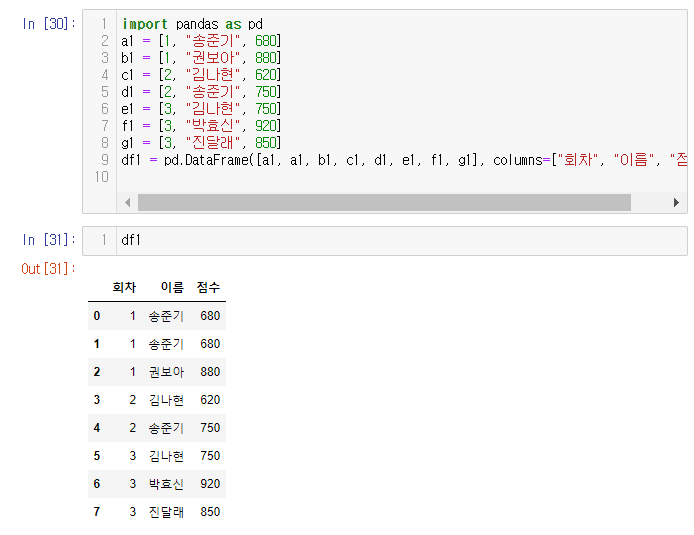
2. 중복값 유무 확인하기

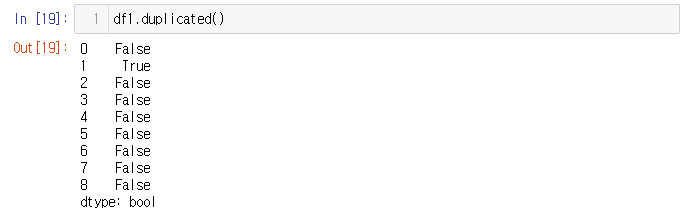
true of false로 결과 반환
3. 중복값 제거하기
- 파라미터 지정x =두번째로 나온 중복값만 삭제
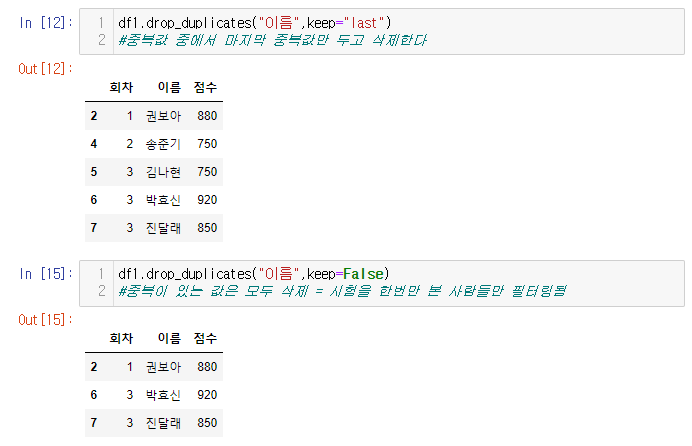
- keep 파라미터 사용시, last는 따옴표로 묶어주는것 잊지 말것

질문 없는 성장은 없다. 3년차 데이터 분석가