merge 함수
merge 함수는 뜻 그대로 합치다 라는 뜻인데, concat 함수와는 차이가 있다. concat 함수는 행과 열, 즉 index 기준으로 합치는것이고, merge는 엑셀의 vlookup처럼 같은 값는 열을 기준으로 열로 붙게 된다. 여기서 편한점은 엑셀의 vlookup은 순서가 중요하지만, merge는 동일한 열만 있으면 해당 열에 맞게 값이 붙게되므로 더 편리하다.
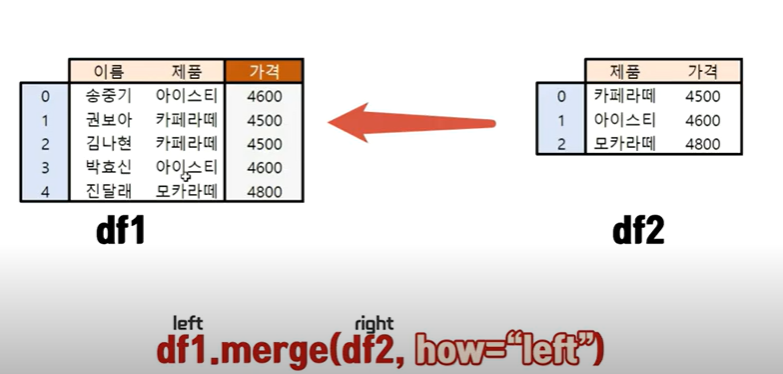
-
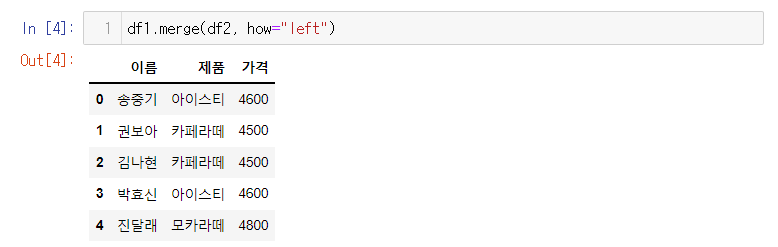
df1.merge(df2, how = "left")
(df1 = left / df2 =right , 즉 왼쪽 표에 왼쪽으로 붙으라는 뜻) -
가격 정보를 담고 있는 df2는 제품값에 맞춰서 df1의 열로 붙게된다
다중조건일때 merge 함수 쓰기
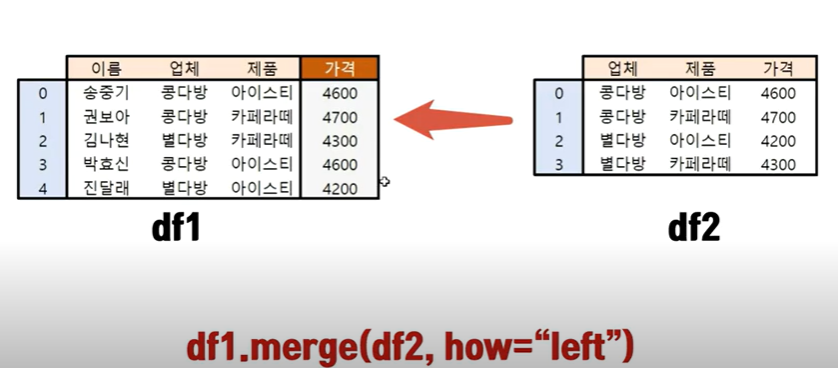
- df1.merge(on=["제품","업체"] , df2, how = "left")
df2를 자세히 보면 업체마다 제품 가격이 다르다. 즉, 제품 하나만 가지고 merge를 쓸수 없는 상황. 하지만 merge는 다중요건도 단일요건과 똑같은 코드로 작동한다. 두 데이터에 공통으로 들어가는 제품과 업체를 on=["업체","제품"] 조건으로 넣으면 되지만 알아서 해주기 떄문에 굳이 적을필요는 없다.
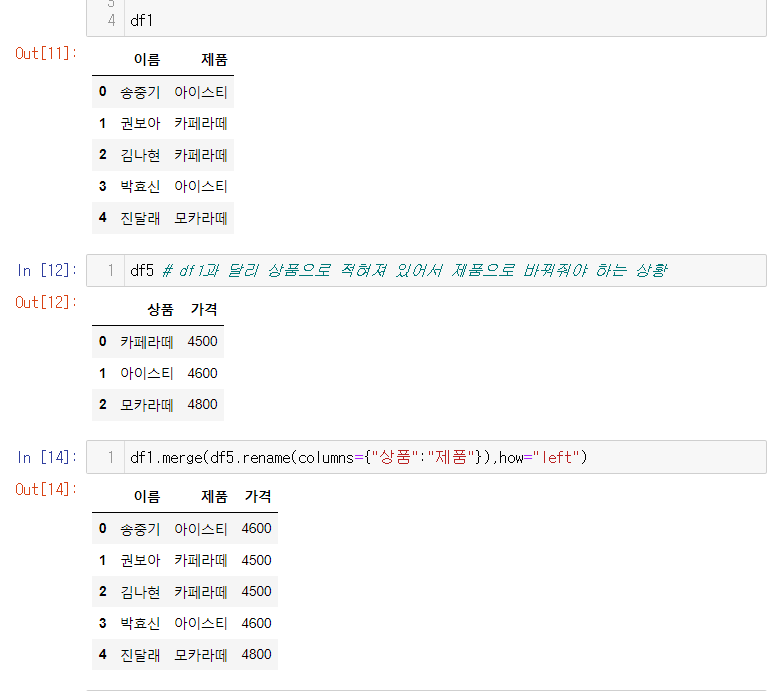
df1과 df2의 이름이 다른데 merge를 쓰고 싶은 경우
- 붙이려는 데이터의 컬럼이름을 바꿔준다. df2.rename(columns=) or df2.columns=[ ]

붙이려는 데이터가 중복값이 있을경우
- 중복값을 제거 한 후 붙여줘야 중복이 안생긴다. df2.drop_duplicate()
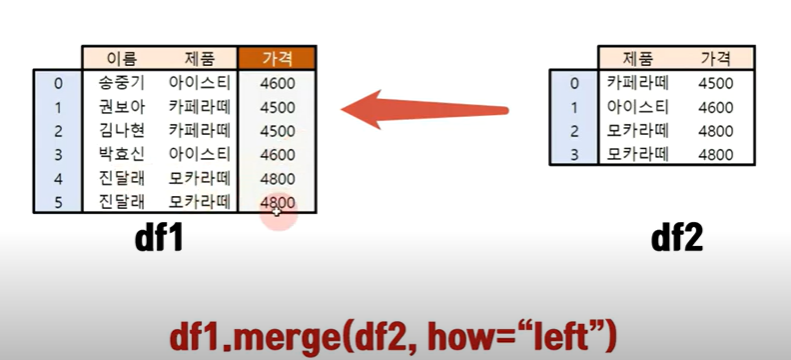

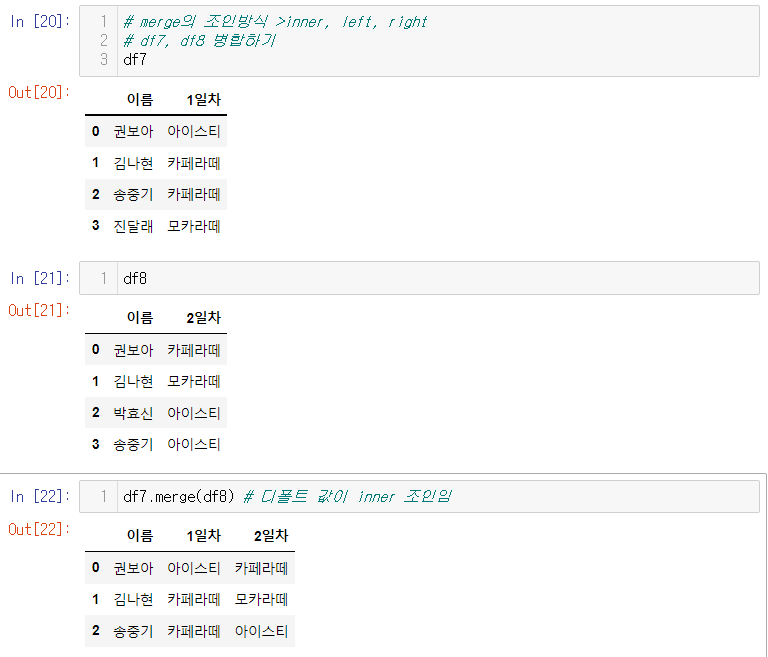
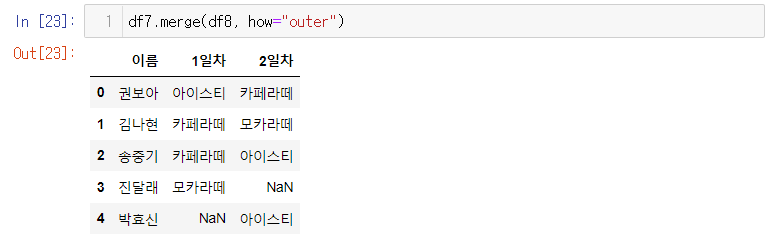
merge함수 역시 join 기능이 있다 (inner, outer)
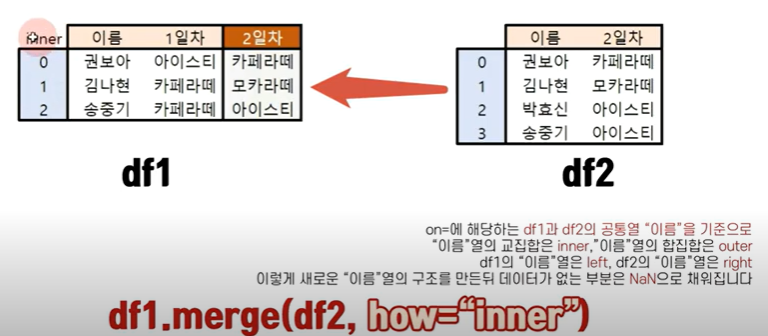
- df1.merge(df2, how = "inner") << 파라미터가 조인이 아니라 how로 유지함을 주의하자
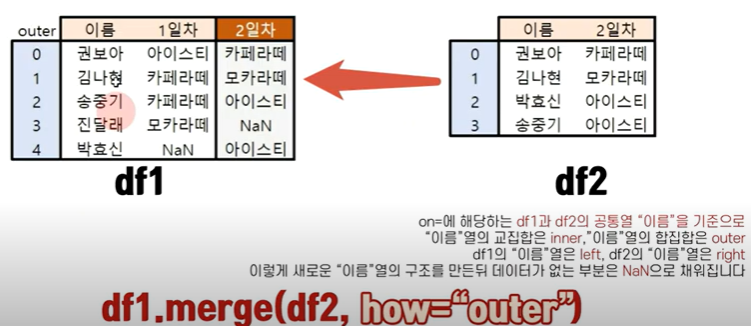
-df1.merge(df2, how = "outer")
오늘의 목표
- 엑셀의 vlookup처럼 데이터를 병합해보자
- 다중조건 병합
- 두 데이터프레임의 열이름이 다를때 병합
- 중복 행이 있을때 병합
- merge의 조인방식
- column이 아닐때 병합
1. 판다스 임포트 하기
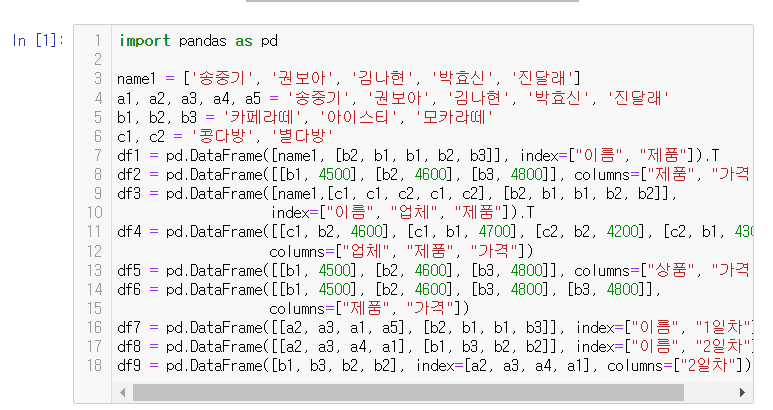
name1 = ['송중기', '권보아', '김나현', '박효신', '진달래']
a1, a2, a3, a4, a5 = '송중기', '권보아', '김나현', '박효신', '진달래'
b1, b2, b3 = '카페라떼', '아이스티', '모카라떼'
c1, c2 = '콩다방', '별다방'
df1 = pd.DataFrame([name1, [b2, b1, b1, b2, b3]], index=["이름", "제품"]).T
df2 = pd.DataFrame([[b1, 4500], [b2, 4600], [b3, 4800]], columns=["제품", "가격"])
df3 = pd.DataFrame([name1,[c1, c1, c2, c1, c2], [b2, b1, b1, b2, b2]],
index=["이름", "업체", "제품"]).T
df4 = pd.DataFrame([[c1, b2, 4600], [c1, b1, 4700], [c2, b2, 4200], [c2, b1, 4300]],
columns=["업체", "제품", "가격"])
df5 = pd.DataFrame([[b1, 4500], [b2, 4600], [b3, 4800]], columns=["상품", "가격"])
df6 = pd.DataFrame([[b1, 4500], [b2, 4600], [b3, 4800], [b3, 4800]],
columns=["제품", "가격"])
df7 = pd.DataFrame([[a2, a3, a1, a5], [b2, b1, b1, b3]], index=["이름", "1일차"]).T
df8 = pd.DataFrame([[a2, a3, a4, a1], [b1, b3, b2, b2]], index=["이름", "2일차"]).T
df9 = pd.DataFrame([b1, b3, b2, b2], index=[a2, a3, a4, a1], columns=["2일차"])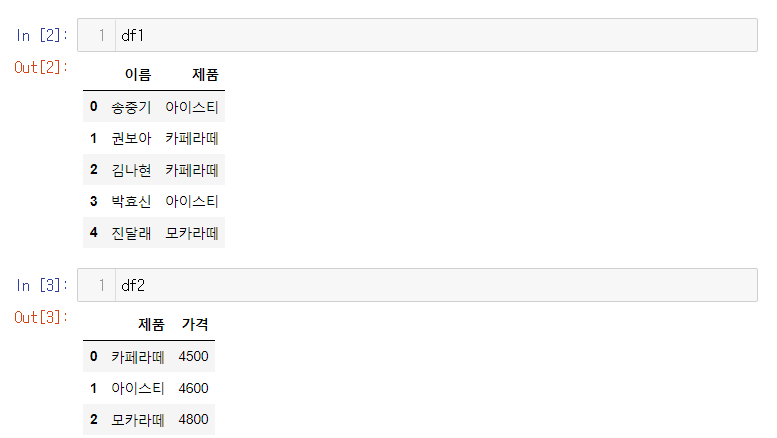
df1 과 df2 병합하기
2. 다중조건 병합하기
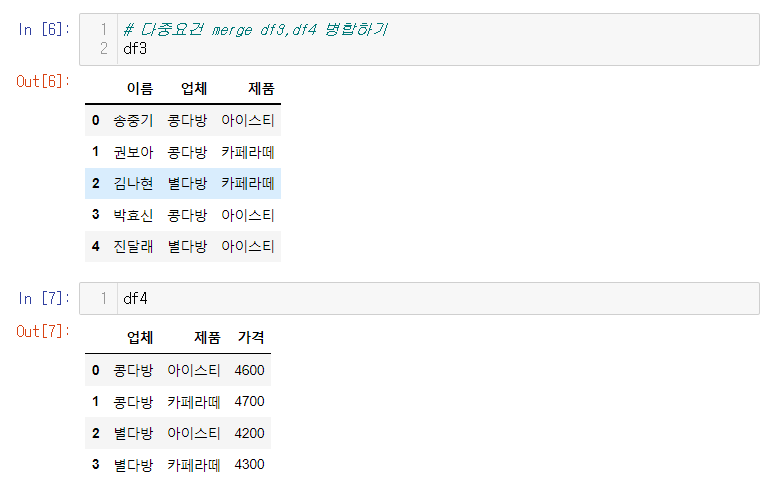
-
제품이름으로 병합할 수 없는 상황(업체마다 제품의 가격이 다르므로)

-
on부분은 생략가능하다
3. 겹치는 컬럼이 이름이 다를떄

- df.rename(columns/index = {" " :" " } ) << 딕셔너리 구조로 써야함을 주의!
4. 중복값이 있는경우
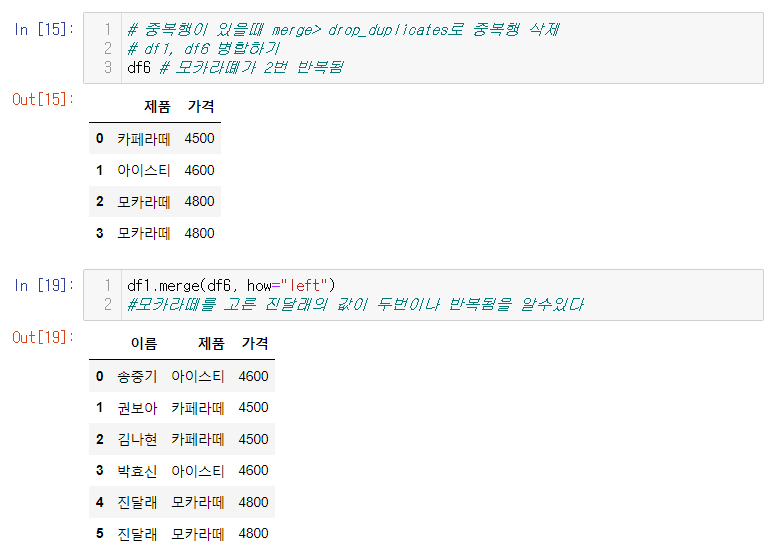
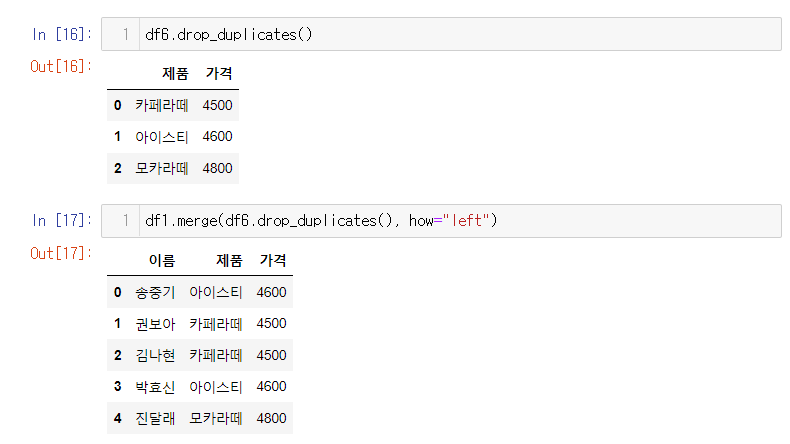
- df.drop_duplicate() 하여 중복값을 제거한 값을 merge함수에 넣어준다
5. merge의 조인
+) 기준이 열이 아닐떄
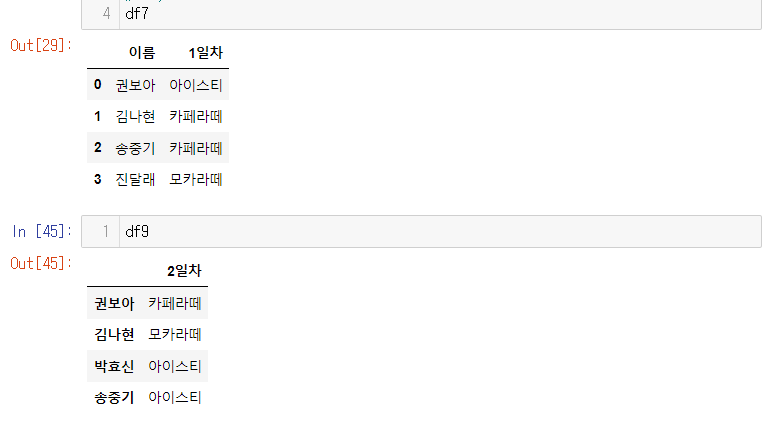
- df9는 인덱스가 없다.
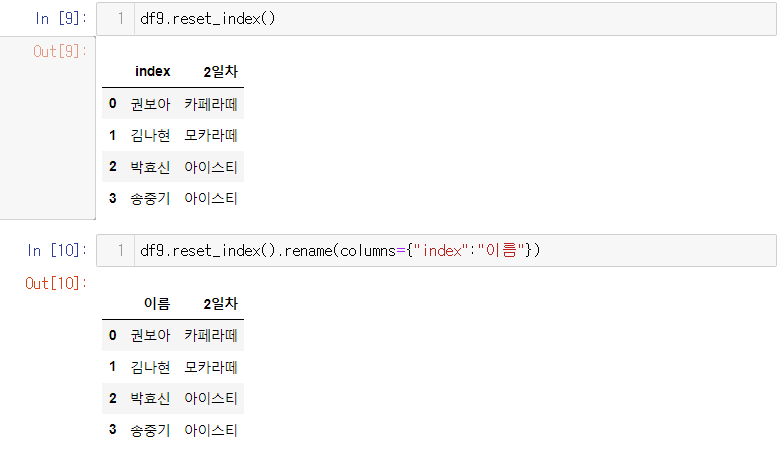
- reset_index로 이름을 대신하여 숫자가 인덱스가 되었지만 새로 생긴 열에 대한 이름이 index로 되어있기 떄문에 이름을 바꿔줘야 한다. rename을 사용한다
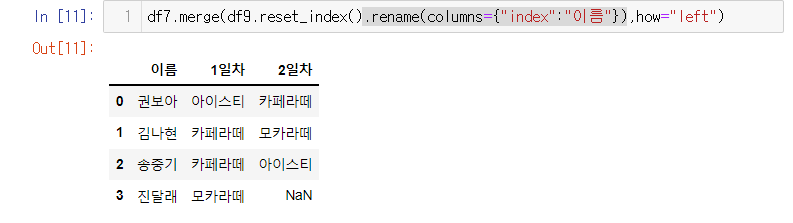
- 이제 merge로 바꿔줄수 있는 조건이 다 끝났다

질문 없는 성장은 없다. 3년차 데이터 분석가