들어가기 전에 인덱싱과 슬라이싱 복습
df의 열 가져오기=df["열이름"]
df.loc 사용하여 행, 열, 슬라이싱하기=df.loc["행이름","열이름"] >>문자열로 가져오기
df.iloc 사용하여 행, 열, 슬라이싱하기=df.iloc[행,열]>> 숫자로 가져오기
drop 함수 사용하기=df.drop
boolean indexing
- true or false로 이루어진 bool 자료형으로 변환하여 새로운 표를 만들수 있음
- 결국 true of false를 반환하는 성질을 이용하여 true 값을 가져와서 새로운 표를 만든다는 것

- 인덱스중에 true인 B,D만 새로운 표로 만들어졌음

- 컬럼중에 TURE인 영어와 과학만 새로운 표로 만들어줌

*특정 컬럼인 수학 values 중에 90 이상인 것들만 인덱싱 하여 가져올 수도 있음
오늘의 목표
- 시리즈를 true or false로 바꿔본다
- boolean indexing으로 해당 조건을 만족하는 데이터만 추출해본다
- 여러개의 조건문을 결합하여 2를 해본다
- isnull , isin 함수를 이해한다
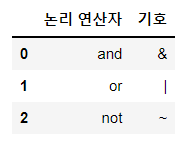
판다스 연산자
and &
or |(shift+달러표시)
not ~
1. 판다스,넘파이 가져오고 데이터 살펴보기

2. 특정 열에 조건을 주어 true or false로 바꿔본다
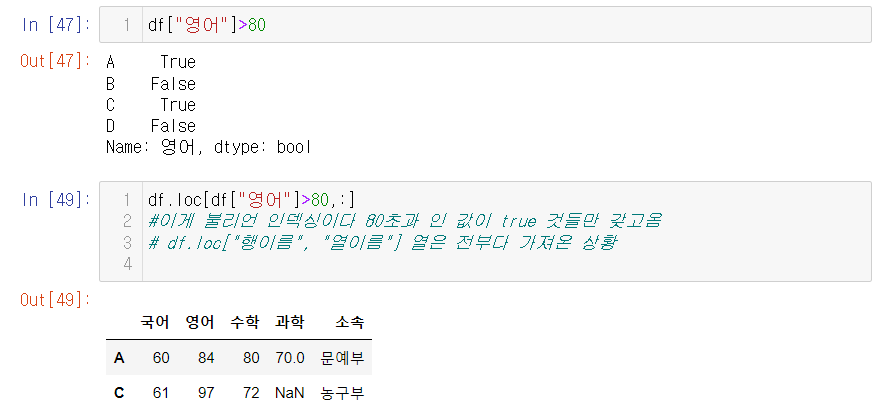

- df.loc 함수 사용해서 열도 슬라이싱 해보기
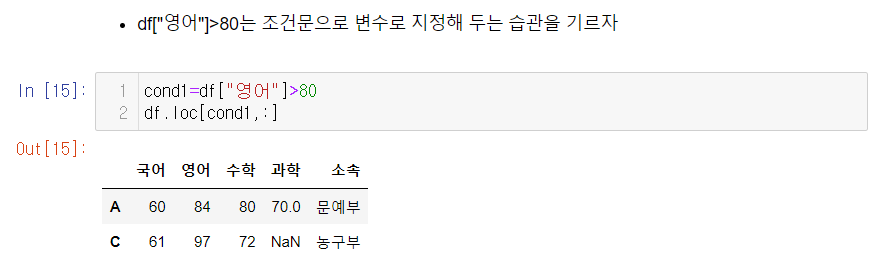
+) 조건문을 변수에 지정하는 습관을 기르자
3. 조건이 여러개일때 불리언 인덱싱 하기
- 국어 성적>60 and 수학 성적>75 조건 2개를 만족하는 사람의 데이터를 갖고 오고 싶을때
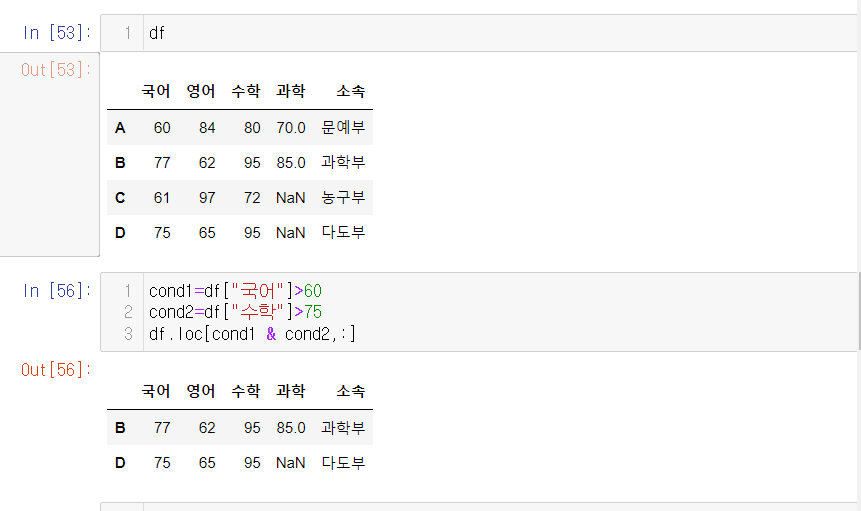
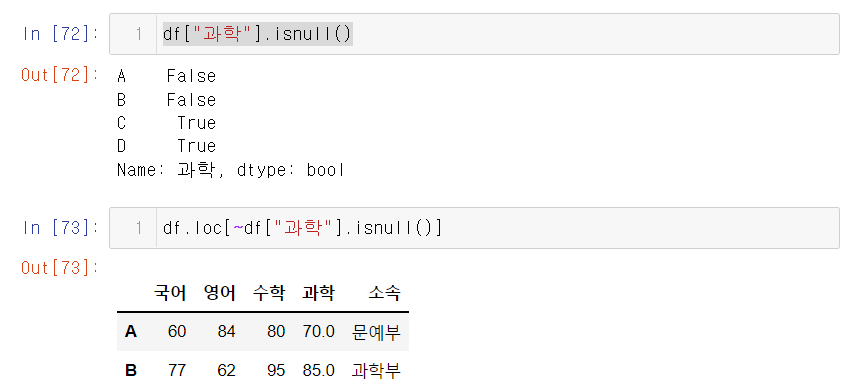
4. isnull 함수 사용하기

-
C,D의 과학 점수가 NAN 이므로 TRUE라고 뜬다. 이점을 이용해서 NAN이 아닌 부분만 가져오게 할 수 있다
-
~은 not의 기호이다
-
과학 점수가 nan이 아니거나 수학점수가 90 이상인 데이터를 추출하라
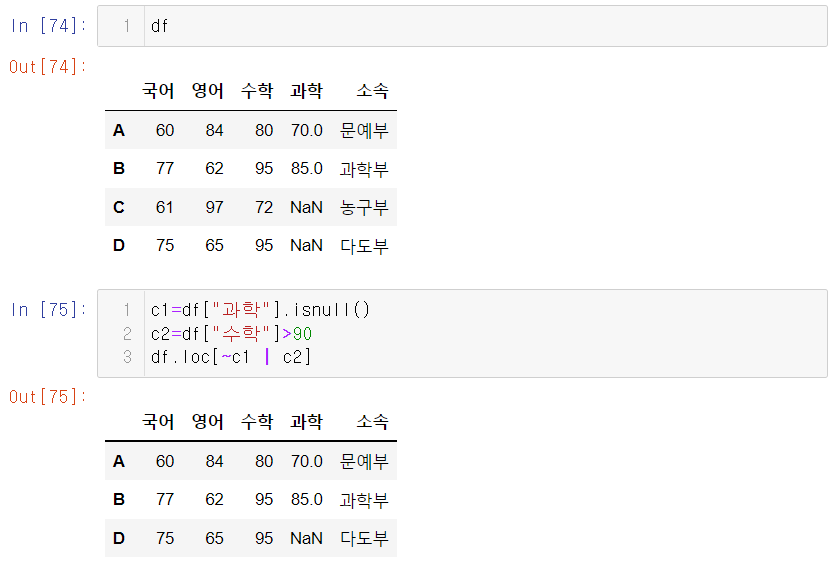
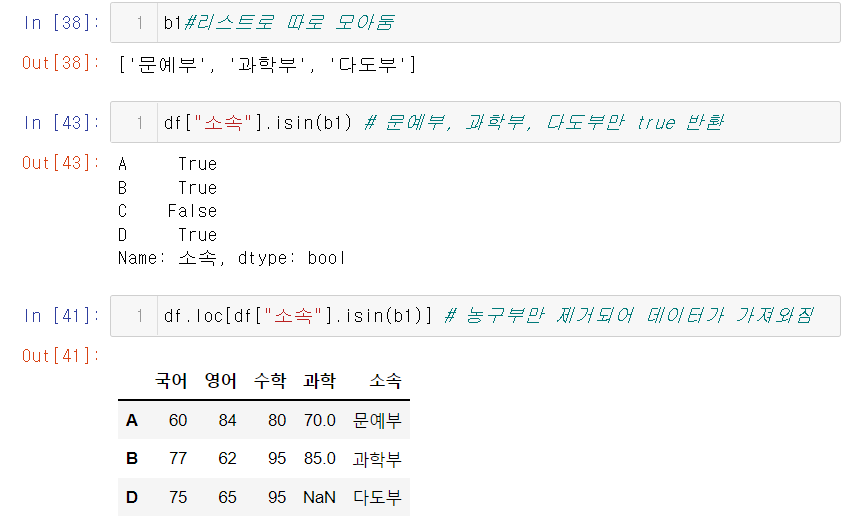
5. isin 함수 사용하기
-
isin()= () 안에 들은 변수 안에 포함되면 true 반환 아니면 false반환
-
isin 함수를 사용핳여 문예부, 다도부, 과학부의 데이터만 추출해라
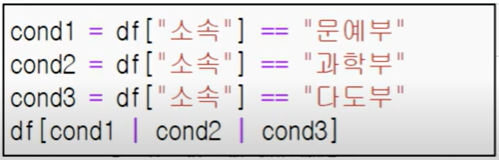
현재 표에서는 총 4개의 부만 있지만 100개 이상이 될때 하나하나 변수 만들어주기에는 너무 힘들다. 그래서 따로 true를 반환할 리스트를 만들어 둔다

질문 없는 성장은 없다. 3년차 데이터 분석가