들어가기 전에 index의 의미 재파악 하기
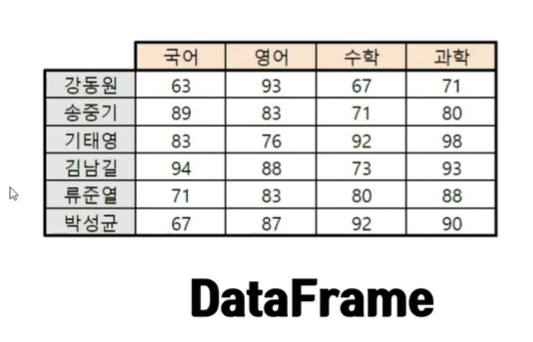
이때까지 행의 이름을 index, 열의 이름을 columns라고 배웠는데 엄밀히 말하면
행의 index는 index, 열의 index를 columns이라고 부르는 것. 즉 둘다 데이터 프레임은 인덱스로 이루어진 표이다. 다만 헷갈리기 쉬워서 네이밍을 인덱스, 컬럼으로 나누어 표현했다.
오늘의 목표
- df.index, df.columns를 확인한다
- index를 설정한다 set_index
- index를 리셋한다 reset_index
- index의 순서를 바꿔본다 reindex
- index의 이름을 바꾼다. 직접 입력 or rename
- index를 정렬한다 sort_index
1. 판다스 가져오고 데이터 살펴보기
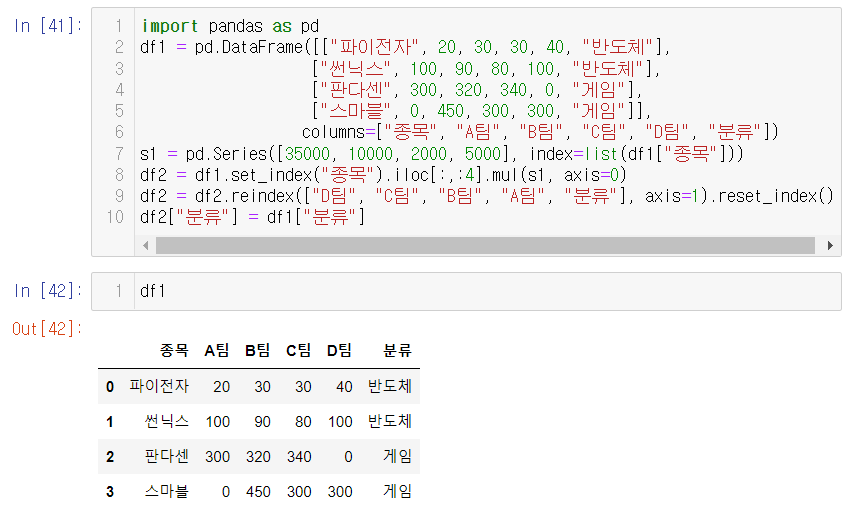
2. df.index, df.columns를 확인하기

- df.index 는 rangeindex로 나와서 가독성이 안좋을수 있는데 이는 list 변경하면 좀더 쉽게 파악할 수 있단다
3. set_index() 함수를 통해 인덱스 새로 지정하기
- DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
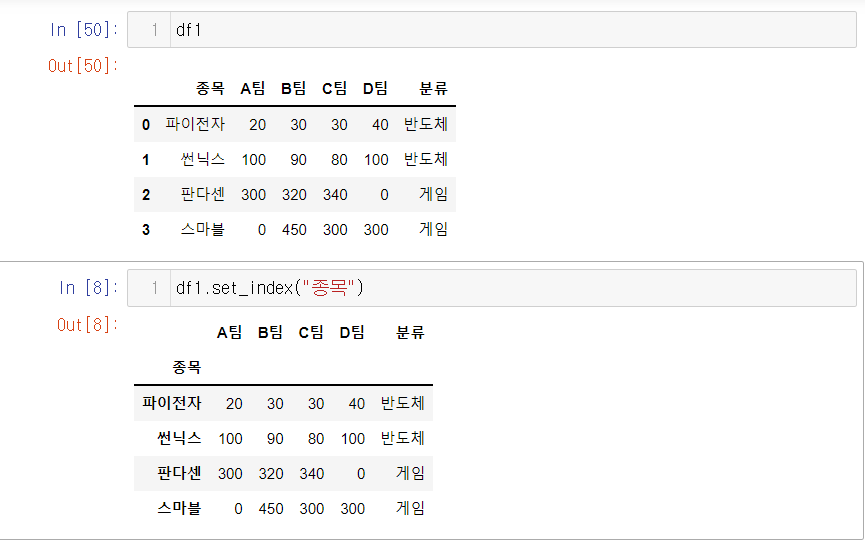
- 0,1,2,3 이었던 인덱스가 종목으로 바뀌면서 사라졌다
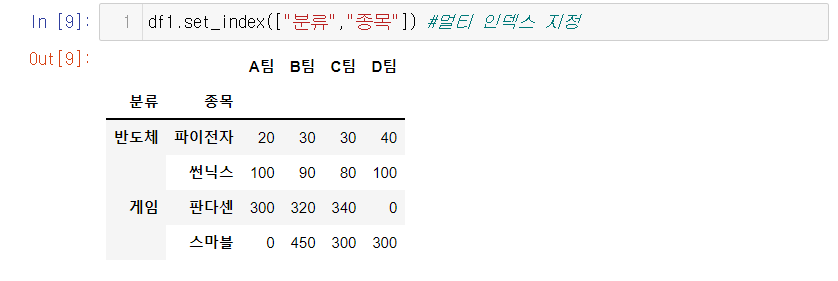
- 멀티 인덱스를 지정하는 방법은 ()안에 리스트로 묶어 인덱스가 될 열을 적어준다
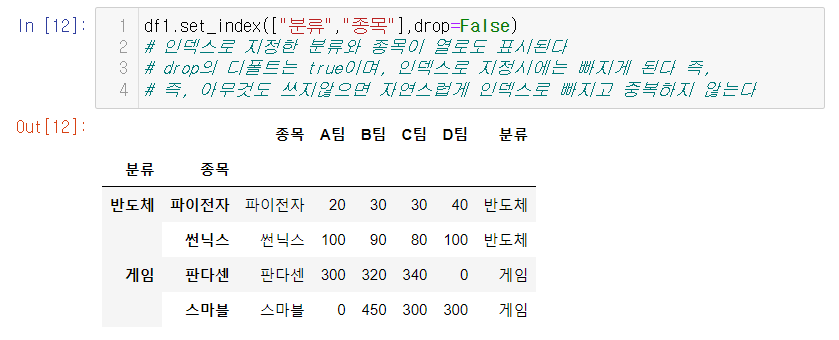
- drop=False로 하면 인덱스로 지정되어도, 인덱스안에 지정된 열들이 여전히 열 안에 잔존한다.
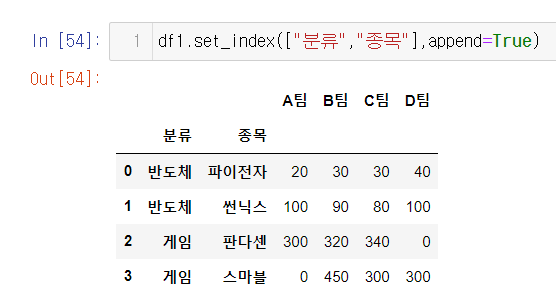
- append=True라고 하면 기존 idx인 0,1,2,3 살아있게 되고 false 지정시에는 사라지게 됨
- drop과 append는 필요한 상황에서 쓰면 됨
4. index를 리셋한다 reset_index
- 종목이 판다센을 제외한 데이터만 추출하기
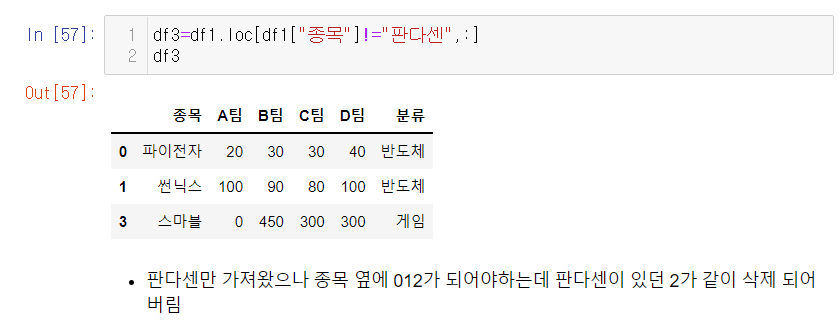
**판다센이 아닌것만 가져온것!
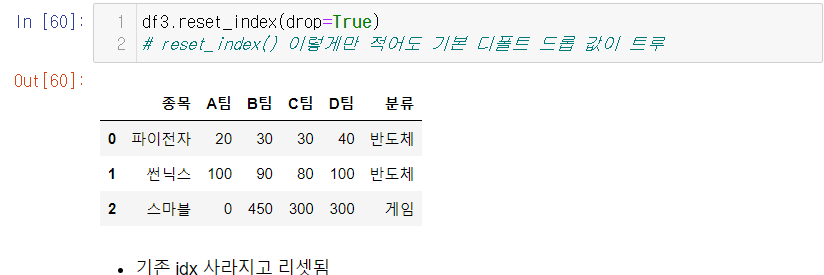
- 인덱스 번호를 유지하고 싶으면 drop=true 라고 하면 기존에 있던 idx 값이 리셋됨
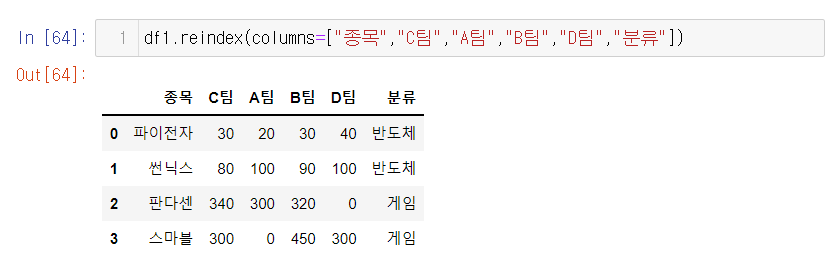
5. index의 순서를 바꿔본다 reindex , 기존의 인덱스 "순서"를 갈아 엎는것
-
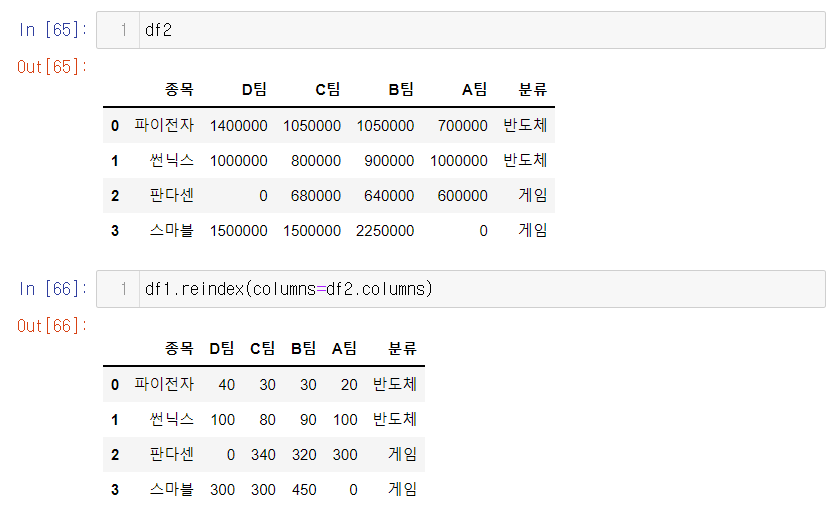
df2기준으로 df1의 자료 순서를 df2 순서로 바꾸기
-
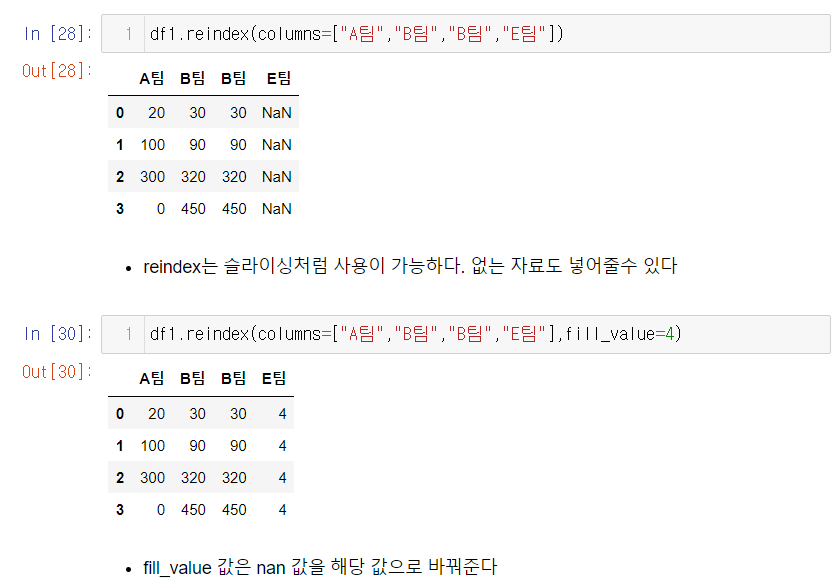
특정 배열을 기준으로 순서를 바꿀수 있다는 점이 편리하다
-
슬라이싱처럼 원하는 자료만 가져올수도 있다. 하지만 슬라이싱과 차이점은 없는 인덱스를 불러올때 nan 값으로 할당된다는 것이며, 그 값을 fill_value 를 통해 특정 값을 넣어줄수 있다는 점이다.
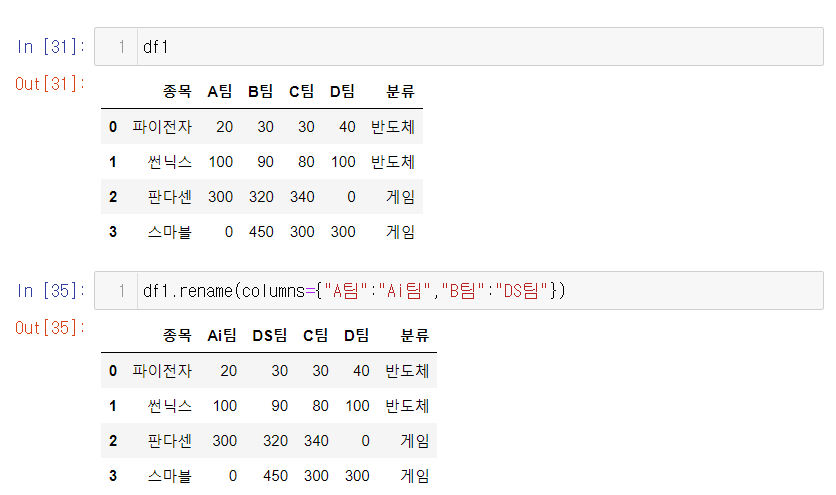
6. index의 이름을 바꾼다= 직접 입력 or rename
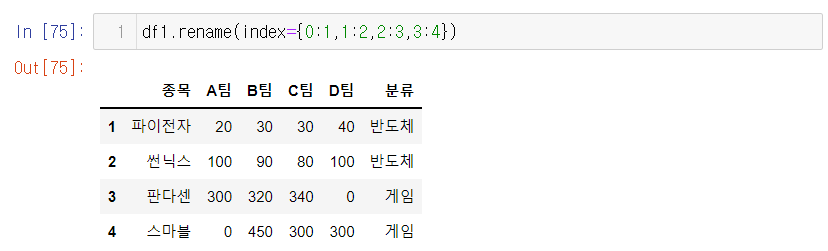
-
df.rename(컬럼or idx={딕셔너리 구조!})
-
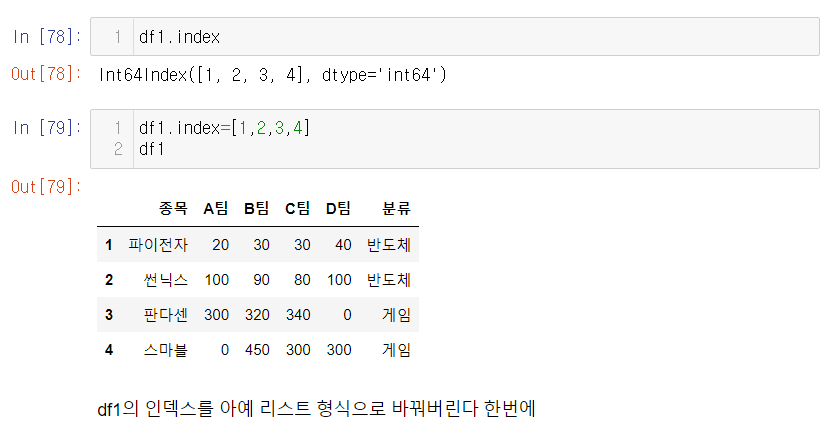
QUIZ 행 인덱스 0,1,2,3을 1,2,3,4로 바꾸려면 어떻게 해야할까?
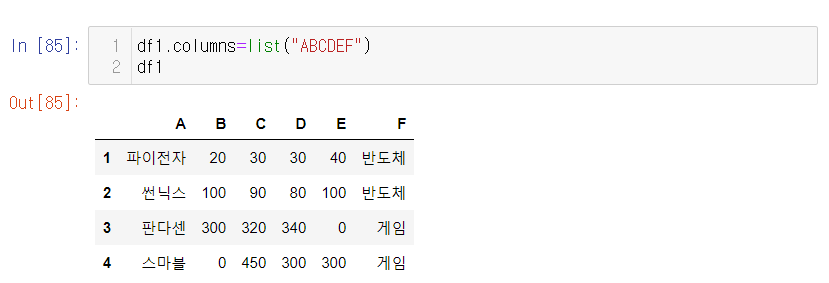
열도 문자열이 리스트로 바뀌면 한개씩 쪼개진다는 성질을 사용해 동일하게 바꿔줄수 있음
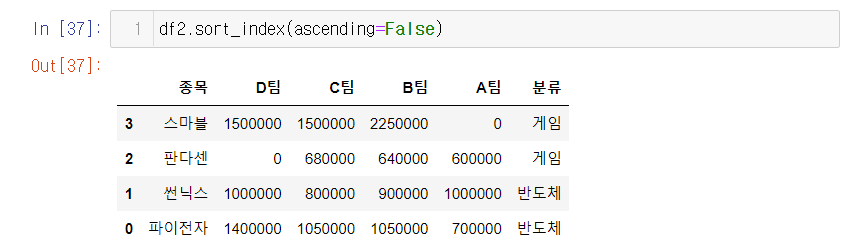
7. index를 정렬한다 sort_index
df2의 열이름을 오름차순으로 변경하도록 만들었다
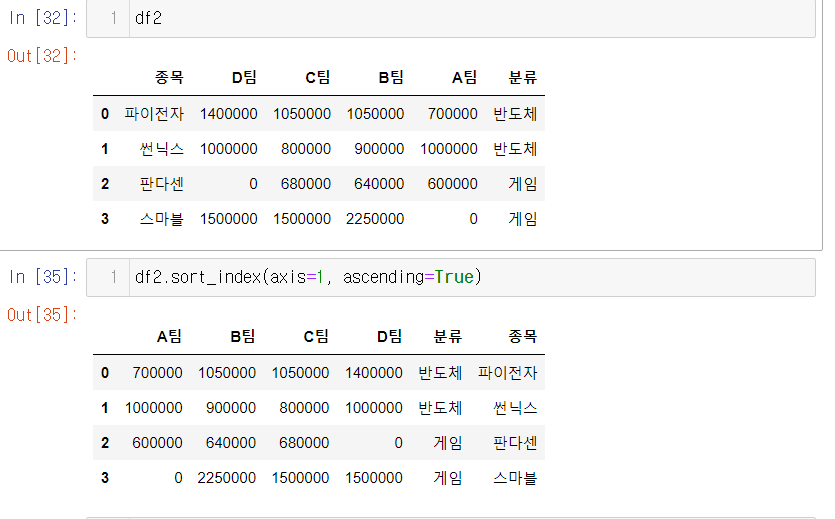
물론 행 중심으로 내림차순도 가능하다. index는 열, 행 모두 해당하기 떄문이다. axis를 활용해서 행, 열 오름차순으로 원하는대로 바꾸고 싶을떄는 sort_index(axis= 0 or 1 , ascending = t or f)
8. index를 제거한다 df.drop()
- 행 지우기 = 인덱스 번호로 적어주면 되고 2개 이상일떄는 [0,1] 이런식으로 묶어주면 된다

- 열지우기 = "" 열이름을 콤마로 묶어주고 역시, 2개 이상일때도 리스트로 묶어주고 주의 해야할점은 무조건 axis = 1 을 추가해 줘야함


질문 없는 성장은 없다. 3년차 데이터 분석가