classification
- 모든 Convolution layer에서 3x3 kernel 사용
- 16~19 layer에 깊은 hidden layer로 학습가능
- VGG-10: 16 Convolution layers + 3 fully connected layers
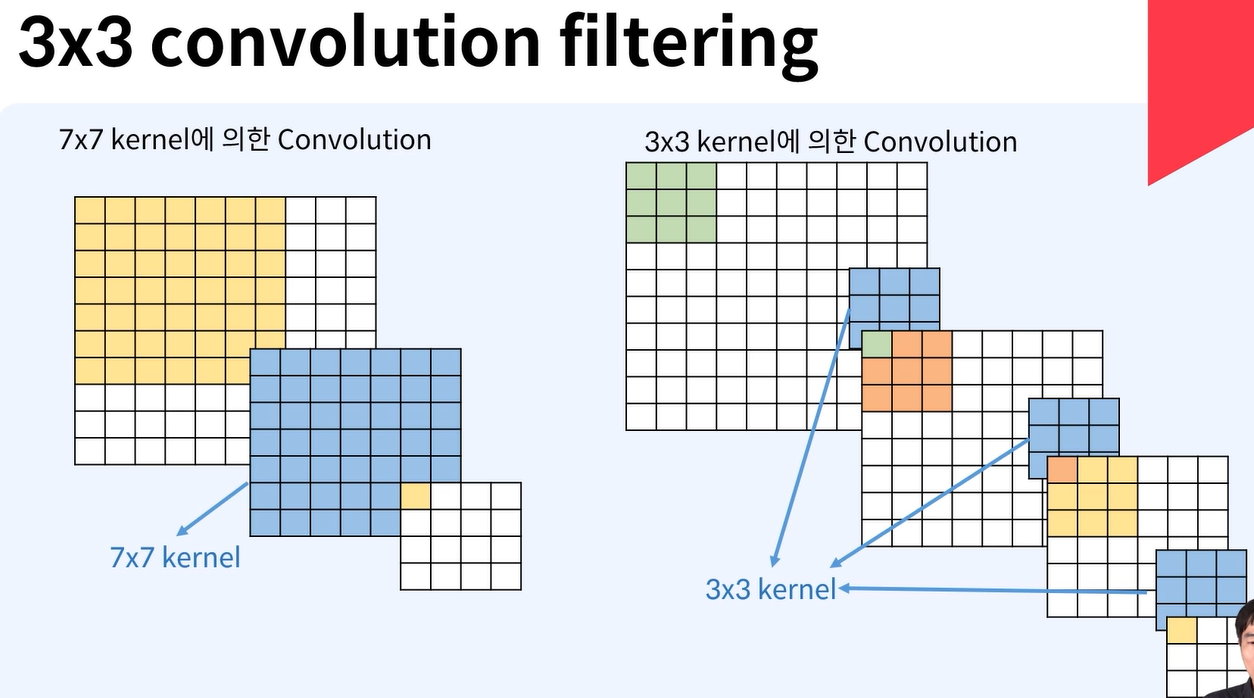
7x7 convolution 함수는 한번에 relu함수가 한번, 반면에 3x3 kernel의 경우는 더 작은 크기로 줄이기 위해 3번이 쓰임
이에 따라 비선형성이 증가하게 되고, VGG 모델의 식별성 증가한다. 하지만 gradient vanishing효과도 생김
각 convolution layer에 대해 Batch Normalization
layer에 들어가는 input이 하나로 쏠리거나 없어지거나 막아주는 효과
- 대용량 처리를 위해 기존에는 Gradient update를 batch 전체에 대해서 함
- batch 단위로 나누게 되면 데이터 분포 차이가 생김
- 이 문제를 해결하기 위해 각 layer의 input의 평균 값과 표준편차 값을 다시 맞추어 입력 값이 하나에 쏠리는 것을 만듬.
- 학습 시 평균과 분산을 조정
- 즉, normalization하는 layer를 둬서 변형된 데이터 분포를 막음
- input의 mini batch B가 m개 있다면
- mini batch의 mean 값과 variance 값을 구한다.
- 각 x data 값에 정규화를 시켜준다.
- 그리고 x값에 학습된 감마를 곱하고 bias인 beta값을 더해줘서 scale과 shift를 해준다.

효과:
- 학습속도 가속화, weight initialization을 할 때 초기에 너무 큰 input을 만드는 것을 피해서 sensitivity를 감소가능
- model regularization
VGG net 구현
import os
import time
import copy
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transformsbatch_size = 64
num_workers = 4
ddir = 'hymenoptera_data'
data_transformers = {
'train': transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.49, 0.449, 0.411], [0.231, 0.221, 0.230])
]),
'val': transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.49, 0.449, 0.411], [0.231, 0.221, 0.230]),
]
),
}
# Image Folder 만들기. train과 val에 대해서.
img_data = {
# A generic data loader where the images are arranged in this way by default:
k: datasets.ImageFolder(os.path.join(ddir, k), data_transformers[k])
for k in ['train', 'val']
}
# train, val data 각각에 batch_size로 묶고 랜덤으로 섞기
dloaders = {
k: torch.utils.data.DataLoader(
img_data[k], batch_size=batch_size, shuffle=True, num_workers=num_workers
) for k in ['train','val']
}
dset_sizes = {x:len(img_data[x]) for x in ['train','val']}
classes = img_data['train'].classes #['ants', 'bees']
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")cfg = {
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
}
class VGG(nn.Module):
def __init__(self, features, num_classes=100):
super().__init__()
self.features = features
self.classifier = nn.Sequential(
# 1. fc layer
nn.Linear(512*7*7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
# 2. fc layer
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
# 3. fc layer
nn.Linear(4096, num_classes)
)
def forward(self, x):
hidden = self.features(x)
hidden = hidden.view(hidden.size()[0],-1)
output = self.classifier(hidden)
return output
def make_layers(cfg):
layers = []
input_channel=3
for l in cfg:
if l == 'M':
# 1/2로 줄이기
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
continue
layers += [nn.Conv2d(input_channel, l, kernel_size=3, padding=1)]
# 주로 미니 배치 내에서 각 채널별로 피쳐 맵의 평균과 분산을 계산하고,
# 이를 사용하여 피쳐 맵의 정규화를 수행
layers += [nn.BatchNorm2d(l)]
layers += [nn.ReLU(inplace=True)]
input_channel = l
return nn.Sequential(*layers)
def vgg16(num=100):
return VGG(make_layers(cfg['vgg16']))
def vgg19(num=100):
return VGG(make_layers(cfg['vgg19']))
model = vgg19(2)
if torch.cuda.is_available():
model = model.cuda()
print(model)VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(25): ReLU(inplace=True)
(26): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(27): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(34): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(35): ReLU(inplace=True)
(36): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(37): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(38): ReLU(inplace=True)
(39): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(44): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(45): ReLU(inplace=True)
(46): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(47): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(48): ReLU(inplace=True)
(49): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(50): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(51): ReLU(inplace=True)
(52): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=100, bias=True)
)
)def train(model, loss_func, optimizer, epochs=10):
start = time.time()
accuracy = 0.0
for epoch in range(epochs):
print(f'Epoch number {epoch}/{epochs-1}')
print('=' * 20)
# dset: train or val
for dset in ['train','val']:
if dset == 'train':
model.train()
else:
model.eval()
loss = 0.0
correct = 0
# dloader에 batch 만큼 각각 extract
for imgs, labels in dloaders[dset]:
# batch수 만큼의 img
imgs = imgs.to(device)
# batch수 만큼의 label
labels = labels.to(device)
# 학습 시 gradient 초기화
optimizer.zero_grad()
# enable or disable grads based on its argument mode.
with torch.set_grad_enabled(dset == 'train'):
# 만든 모델의 img batch파일 넣기
output = model(imgs)
# output에서 최댓값의 index 뽑기 -> preds
_, preds = torch.max(output, 1)
# output class와 labels의 차는 loss_curr
loss_curr = loss_func(output, labels)
# 학습하는 경우
if dset == 'train':
# 역전파
loss_curr.backward()
# update
optimizer.step()
# 64 * loss 값 = 총 loss 값
loss += loss_curr.item() * imgs.size(0)
# prediction과 label수가 같은지 합계
correct += torch.sum(preds == labels.data)
# dset_sizes = {'train': 244, 'val': 153}
loss_epoch = loss / dset_sizes[dset] # epoch마다 loss 값
# 맞은 갯수 / 데이터 크기 -> 정확도
accuracy_epoch = correct.double() / dset_sizes[dset]
# 각각 train과 val에 대해 loss_Epoch와 accuracy_epoch 출력
print(f'{dset} loss in this epoch: {loss_epoch}, accuracy in this epoch: {accuracy_epoch}\n')
# val의 최대 accuarcy를 선정하기 위함
if dset == 'val' and accuracy_epoch > accuracy:
accuracy = accuracy_epoch
time_delta = time.time() - start
print(f'Training finished in {time_delta // 60}mins {time_delta % 60}secs')
print(f'Best validation set accuracy: {accuracy}')
return model
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
pretrained_model = train(model, loss_func, optimizer, epochs=5)Epoch number 0/4
====================
train loss in this epoch: 2.7397684357205376, accuracy in this epoch: 0.4098360655737705
val loss in this epoch: 3.8043701259139318, accuracy in this epoch: 0.5424836601307189
Epoch number 1/4
====================
train loss in this epoch: 1.2334181402550368, accuracy in this epoch: 0.5573770491803278
val loss in this epoch: 2.146533659081054, accuracy in this epoch: 0.45751633986928103
Epoch number 2/4
====================
train loss in this epoch: 0.8574799611920216, accuracy in this epoch: 0.4918032786885246
val loss in this epoch: 0.9654701726109374, accuracy in this epoch: 0.45751633986928103
Epoch number 3/4
====================
train loss in this epoch: 0.8356424091292209, accuracy in this epoch: 0.5245901639344263
val loss in this epoch: 0.8133768552269032, accuracy in this epoch: 0.45751633986928103
Epoch number 4/4
====================
train loss in this epoch: 0.7771363698068212, accuracy in this epoch: 0.4918032786885246
val loss in this epoch: 0.6951859495998208, accuracy in this epoch: 0.5424836601307189
Training finished in 14.0mins 32.71563148498535secs
Best validation set accuracy: 0.5424836601307189def test(model=pretrained_model):
correct_pred = {classname: 0 for classname in classes} #['ants', 'bees']
total_pred = {classname:0 for classname in classes}
with torch.no_grad():
for images, labels in dloaders['val']:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
# [labels], [preds] -> [[labels원소, preds원소]] 로 zip하기
for label, pred in zip(labels, preds):
if label == pred:
correct_pred[classes[label]] +=1
total_pred[classes[label]] += 1
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f}%')
Don't hesitate!