0. DecisionTree
https://scikit-learn.org/stable/modules/tree.html#decision-trees
-
Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression.
-
의사결정나무는 비모수적 지도학습(분류, 회귀)
1. 준비
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler1) dataset
# dataset - uci wine quality
# https://archive.ics.uci.edu/dataset/186/wine+quality
red = pd.read_csv('./data/wine_quality/winequality-red.csv', sep=';')
white = pd.read_csv('./data/wine_quality/winequality-white.csv', sep=';')
white['target'] = 1
wine = pd.concat([red, white])
wine.reset_index(drop=True, inplace=True)
wine.columns
# ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar',
# 'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density',
# 'pH', 'sulphates', 'alcohol', 'quality', 'target']
# 일부 column 선택
X = wine[['fixed acidity', 'residual sugar', 'density', 'pH', 'alcohol', 'quality']]
y = wine['target']2) train / test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.25, random_state= 11)
# DecisionTree는 데이터 정규화의 영향은 적게 받지만, 진행
scaler = StandardScaler()
scaler.fit(X_train)
X_scaled_train = scaler.transform(X_train)
X_scaled_test = scaler.transform(X_test)
2. analysis
from sklearn.tree import DecisionTreeClassifier, export_text
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(X_scaled_train, y_train)
print('Train', dt.score(X_scaled_train, y_train))
print('test', dt.score(X_scaled_test, y_test))
Train : 0.8772577996715928
test : 0.8572307692307692
plt.figure(figsize=(20, 12))
# max_depth= 3 -> 가지수
# filled=True -> 색칠해라
# feature_names=X.columns -> feature_name
plot_tree(dt, max_depth= 3, filled=True, feature_names=X.columns)
plt.show()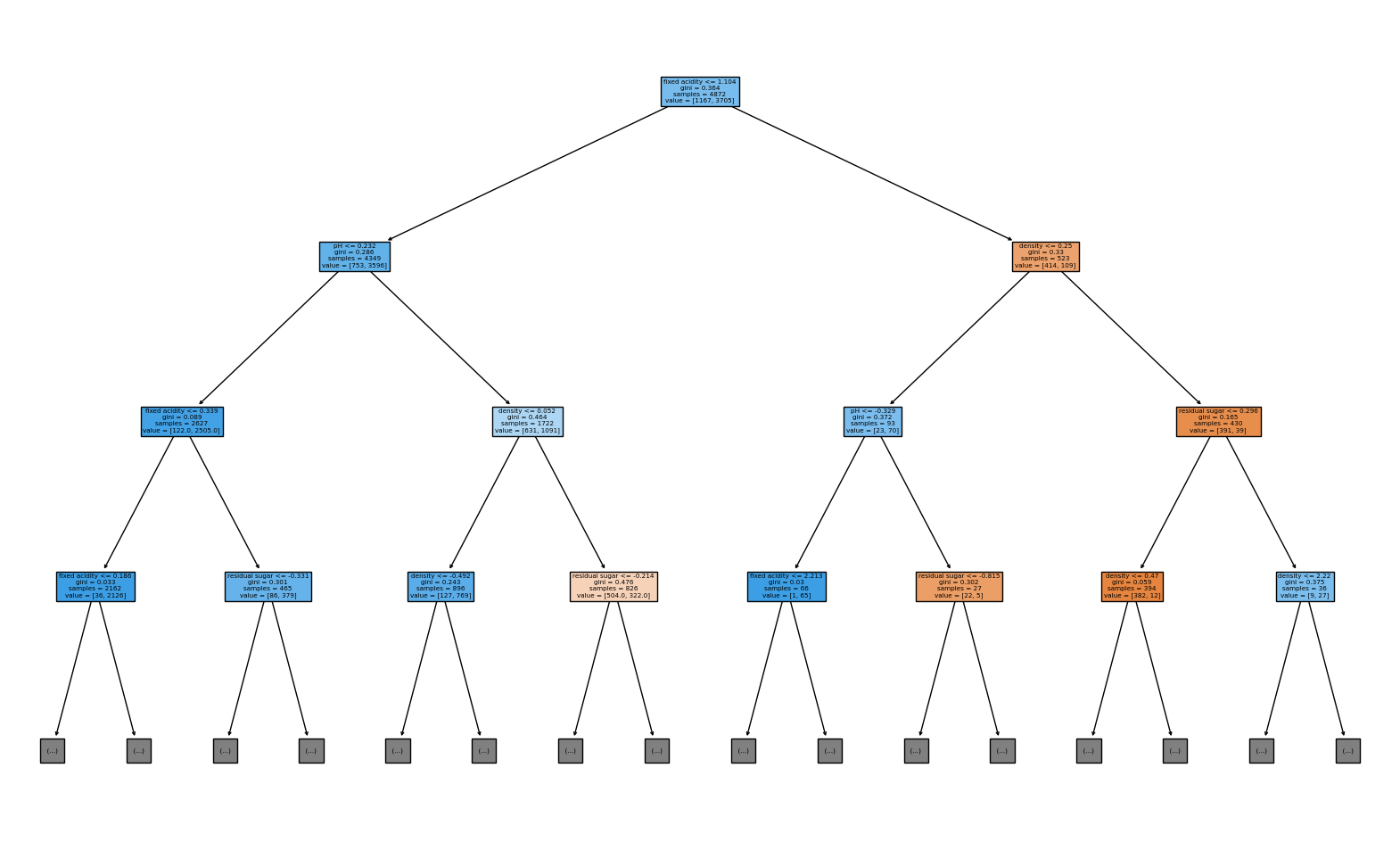
- 불순도(impurity) 하이퍼파라미터
criterion{“gini”, “entropy”, “log_loss”}, default=”gini”
-> gini, entropy, log_loss 3가지로 선택가능
pd.DataFrame(dt.feature_importances_.reshape(1, -1), columns= X.columns)| fixed acidity | residual sugar | density | pH | alcohol | quality |
|---|---|---|---|---|---|
| 0 | 0.41805 | 0.037696 | 0.282118 | 0.262136 | 0.0 |
- 가장 영향력이 큰 feature는
residual sugar,alcohol등의 순이다.
3. GridSearchCV
1) 최적의 parameter 탐색
from sklearn.model_selection import GridSearchCV
dt = DecisionTreeClassifier()
params = {'max_depth': range(1, 10), 'min_samples_split':range(2,50, 10)}
grid_dt = GridSearchCV(dt, param_grid=params, cv=5)
grid_dt.fit(X_train, y_train)
print('params', grid_dt.best_params_)
print('score', grid_dt.best_score_)scores_df = pd.DataFrame(grid_dt.cv_results_)
scores_df[['params', 'mean_test_score', 'std_test_score', 'rank_test_score']].sort_values('rank_test_score').head(5)| params | mean_test_score | std_test_score | rank_test_score | |
|---|---|---|---|---|
| 35 | {'max_depth': 8, 'min_samples_split': 2} | 0.965928 | 0.004271 | 1 |
| 36 | {'max_depth': 8, 'min_samples_split': 12} | 0.965313 | 0.006844 | 2 |
| 41 | {'max_depth': 9, 'min_samples_split': 12} | 0.962029 | 0.005345 | 3 |
| 40 | {'max_depth': 9, 'min_samples_split': 2} | 0.962027 | 0.005156 | 4 |
| 37 | {'max_depth': 8, 'min_samples_split': 22} | 0.961823 | 0.004268 | 5 |
params {'max_depth': 8, 'min_samples_split': 2}
score 0.9659282893697678
2) 하이퍼 파라티머 조정
final_dt = DecisionTreeClassifier(max_depth=grid_dt.best_params_['max_depth'], min_samples_split=grid_dt.best_params_['min_samples_split'])
final_dt.fit(X_train, y_train)
print('Train', final_dt.score(X_train, y_train))
print('test', final_dt.score(X_test, y_test))Train 0.9909688013136289
test 0.9747692307692307
a. feature_importances
pd.DataFrame(final_dt.feature_importances_.reshape(1, -1), columns= X.columns)| fixed acidity | residual sugar | density | pH | alcohol | quality |
|---|---|---|---|---|---|
| 0 | 0.23031 | 0.248965 | 0.280521 | 0.15443 | 0.08289 |
✅ hyper parameter를 최적화하였더니, feature의 영향력이 변화
pH, density, residual sugar순으로
b. 결과 - text 형태
print(export_text(final_dt)) |--- feature_0 <= 8.65
| |--- feature_3 <= 3.25
| | |--- feature_0 <= 7.65
| | | |--- feature_0 <= 7.45
| | | | |--- feature_2 <= 0.99
| | | | | |--- feature_3 <= 3.25
| | | | | | |--- feature_1 <= 1.75
| | | | | | | |--- feature_1 <= 1.65
| | | | | | | | |--- class: 1
| | | | | | | |--- feature_1 > 1.65
| | | | | | | | |--- class: 1
| | | | | | |--- feature_1 > 1.75
| | | | | | | |--- class: 1
| | | | | |--- feature_3 > 3.25
| | | | | | |--- feature_1 <= 1.45
| | | | | | | |--- feature_4 <= 11.85
| | | | | | | | |--- class: 1
| | | | | | | |--- feature_4 > 11.85
| | | | | | | | |--- class: 0
| | | | | | |--- feature_1 > 1.45
| | | | | | | |--- class: 1
| | | | |--- feature_2 > 0.99
| | | | | |--- feature_1 <= 4.05
| | | | | | |--- feature_2 <= 0.99
| | | | | | | |--- feature_5 <= 6.50
...
| | | | | | |--- class: 0
| | | |--- feature_2 > 1.00
| | | | |--- class: 0c. 결과 - 이미지
from sklearn.tree import export_graphviz
import graphviz
dot_data = export_graphviz(final_dt, # 의사결정나무 모형 대입
out_file = None, # file로 변환할 것인가
feature_names = X.columns, # feature 이름
filled = True, # 그림에 색상을 넣을것인가
rounded = True, # 반올림을 진행할 것인가
special_characters = True) # 특수문자를 사용하나
graph = graphviz.Source(dot_data)
graph

새로운 길