ML
1.ML) KNN - K-Nearest Neighbor Classifier
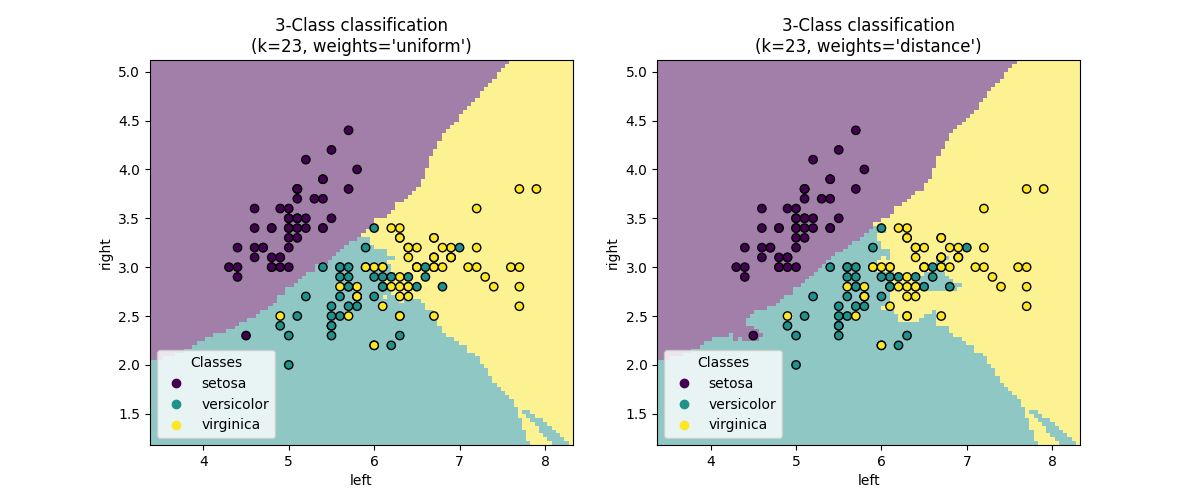
0.K-Nearest Neighbor Classifier 새로운 데이터를 특정 값으로 분류 현재 데이터와 가장 가까운 k개의 데이터를 찾아 가장 많은 분류 값으로 새로운 데이터 분류 1. 분석준비 - iris dataset 2. KNN (1) - 전체 datase
2.ML) KNN - K-Nearest Neighbor Regression

주변의 가장 가까운 K개의 샘플을 통해 값을 예측하는 방식이다. 가장 간단한 방식으로는 K개 샘플의 평균을 통해 예측knn과의 차이\-> KNN은 클래스로 분류 / K-NN Regression(K-최근접 이웃 회귀)은 '숫자'를 가지고 예측1\.
3.ML) Logistic Regression / 로지스틱 회귀
0. Logistic Regression - 어떤 사건이 발생할 확률 - 어떤 클래스로 분류된 확률
4.ML) DecisionTree / 의사결정나무
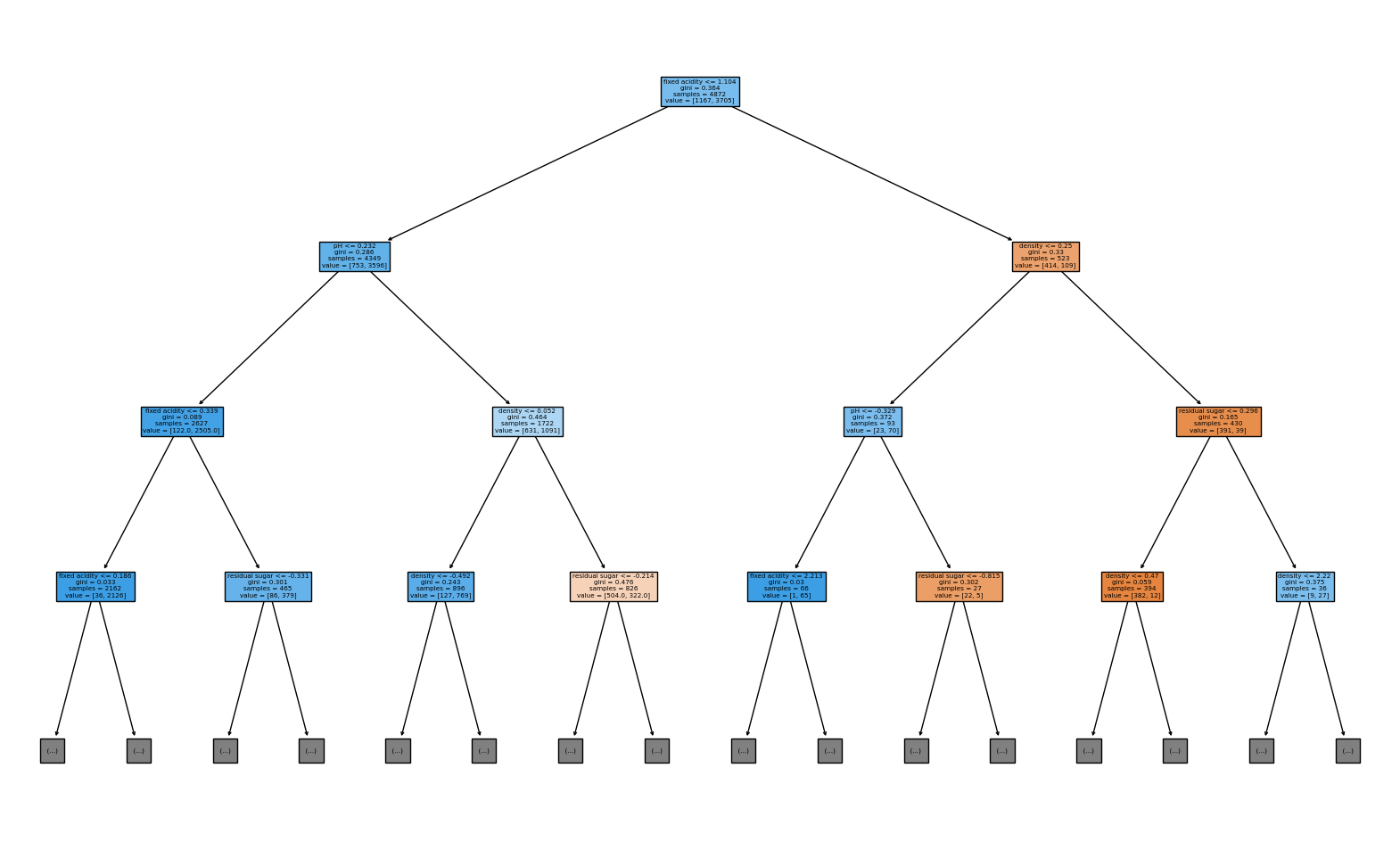
의사결정나무 - 비모수적 지도학습(분류, 회귀)
5.ML) K-Means Clustering / K-평균 알고리즘
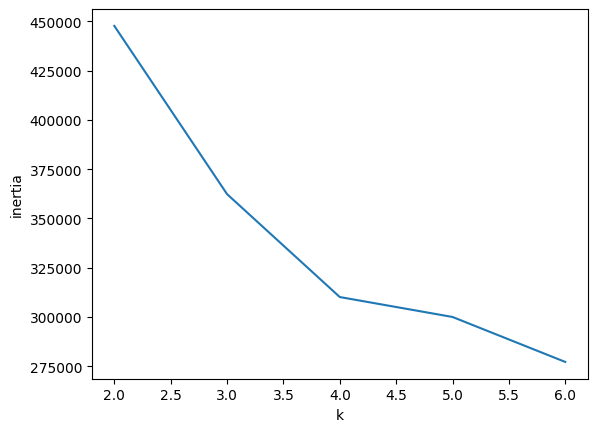
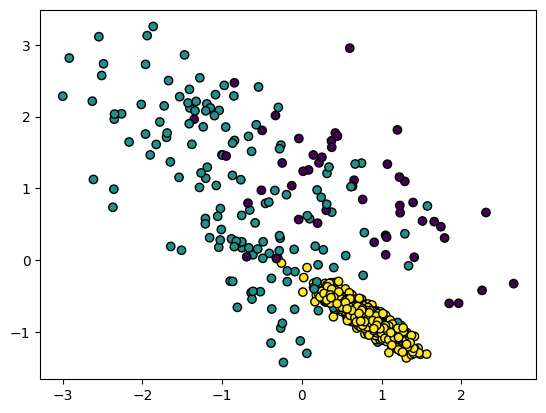
머신러닝 비지도학습의 한 종류주어진 데이터를 K개의 cluster로 묶는 알고리즘각 군집과 각 데이터의 거리 차이의 분산을 최소화 하는 방식으로 clustering❓ 이번 연습에서는 손글씨가 0,1,2로 정해져 있기 때문에 k-means의 비지도학습의 취지에 맞지는 않
6.ML) imbalanced data의 문제를 해결하기 위한 resampling
데이터의 각각의 class들의 비율이 균일하지 않게 분포하는 경우모델 성능의 왜곡이 발생높은 정확도를 보이는 것 처럼 보이지만, 비율이 적은 class는 제대로 분류하지 못하는 문제가 발생 이를 해결하기 위해서 resampling을 통해 데이터의 불균형을 해결
7.ML) categorical variable to numeric - labeling, one-hot encoding
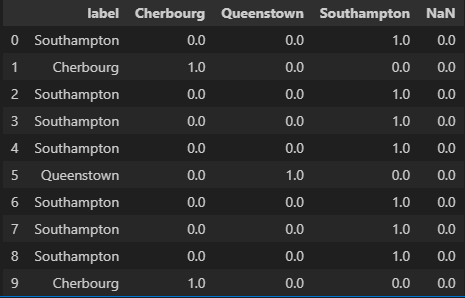
성별과 같은 정보는 'man', 'woman'으로 나뉜다.이러한 정보들은 string형태로 나눠지고, 이는 행렬계산에 부적합행렬계산에 적합한 숫자 형태로 변환하는 연습을 해보고자 한다.
8.ML) PCA(주성분분석) - 차원축소
고차원의 데이터 집합이 주어졌을때, 발생하는 문제점들을 해결하기 위해 차원 축소 활용
9.ML) 모델 평가 - confusion matrix / 혼동행렬
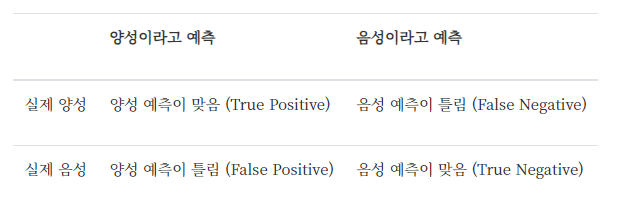
지도학습 중 분류모델의 성능을 표현하는 표예측 성능을 확인하는데 예측 값과 실제 값의 비교쉽게 이야기 해서 분류모델에서 클래스를 판단하는데, 얼마나 잘 평가하는지를 확인 할 수 있다.출처 (데이터 사이언스 스쿨 : https://datascienceschool