0. K-means
- 머신러닝 비지도학습의 한 종류
- 주어진 데이터를 K개의 cluster로 묶는 알고리즘
- 각 군집과 각 데이터의 거리 차이의 분산을 최소화 하는 방식으로 clustering
1. 분석 준비
❓ 이번 연습에서는 손글씨가 0,1,2로 정해져 있기 때문에 k-means의 비지도학습의 취지에 맞지는 않지만, 연습을 위해서 적용
import numpy as np
import pandas as pd
from sklearn.datasets import load_digits
from sklearn.cluster import k_means
import matplotlib.pyplot as plt
digits = load_digits()
print(digits['DESCR'])
- scikit-learn 의 손글씨 dataset 이용
- 연습을 수월하게 하기 위해 분석의 용이성을 위해 3개 집단만 활용
# 0-9까지의 손글씨 중에서 0,1,2만 선택
target_index = np.logical_or.reduce([digits.target == 0, digits.target == 1, digits.target == 2])
selected_digits = digits.data[target_index]
selected_targets = digits.target[target_index]
✅ np.logical_or.reduce
np.array에서(digits == 0) | (digits == 1) | (digits == 2)의 방식은 사용 불가numpy에 맞는 방식으로 사용
✅ index에 해당하는 값만 선택
- 손글씨 0,1,2 만 선택
✅ selected_digits.shape -> (537,64)
537(537cases) 64(88 배열을 열벡터로 변환한 형태)
✅ np.unique(selected_targets, return_counts=True)
- 0 -> 178개
- 1 -> 182개
- 2 -> 177개
2. K-Means Clustering
1) model fitting
from sklearn.cluster import KMeans
kmean = KMeans(n_clusters=3, random_state=22)
kmean.fit(selected_digits)
2) image를 통해서 clustering 결과 확인
import matplotlib.pyplot as plt
# 한빛미디어 - 혼자 공부하는 머신러닝 + 딥러닝 참조
def draw_digits(arr, ratio=1):
n = len(arr) # n은 샘플 개수입니다
# 한 줄에 10개씩 이미지를 그립니다. 샘플 개수를 10으로 나누어 전체 행 개수를 계산합니다.
rows = int(np.ceil(n/10))
# 행이 1개 이면 열 개수는 샘플 개수입니다. 그렇지 않으면 10개입니다.
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols,
figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i*10 + j < n: # n 개까지만 그립니다.
axs[i, j].imshow(arr[i*10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
draw_digits(kmean.cluster_centers_.reshape(-1, 8, 8), ratio=3)print(np.unique(kmean.labels_, return_counts=True))
(array([0, 1, 2]), array([183, 192, 162], dtype=int64))✅ 그림을 통해 확인한 결과
- cluster 0 -> 0 손글씨 : 183개
- cluster 1 -> 2 손글씨 : 192개
- cluster 2 -> 1 손글씨 : 162개
✅ 분석의 용이성을 위해 target을 cluster numbering에 맞춘다.
# 조건문 활용
selected_targets2 = np.zeros_like(selected_targets)
for i in range(len(selected_targets)):
if selected_targets[i] == 1:
selected_targets2[i] = 2
elif selected_targets[i] == 2:
selected_targets2[i] = 1
else :
selected_targets2[i] = 0# numpy 활용
conditions = [selected_targets == 0, selected_targets == 1, selected_targets == 2]
choices = [0, 2, 1]
selected_targets2 = np.select(conditions, choices, default=0)✅ 정답률 확인
mismatch_count = np.sum(selected_targets2 != kmean.labels_)
print(f'{len(selected_targets2)} 중에서 {mismatch_count}를 못 맞춤')
print(f'못 맞춘 경우는 {np.round(mismatch_count / len(selected_targets2) * 100, 2)} %')
537 중에서 41를 못 맞춤
못 맞춘 경우는 7.64 %
3. 최적의 K값 찾기 - inertia
✅ inertia
- centriod와 sample 사이의 거리의 총합
- 클러스터의 중심점과 클러스터에 속한 데이터 사이의 거리의 합
- 작을수록 clustering이 잘 된 결과로 볼 수 있다.
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, n_init='auto', random_state=42)
km.fit(selected_digits)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()✅ K(군집수)의 변화에 따라 inertia의 변화 확인 가능
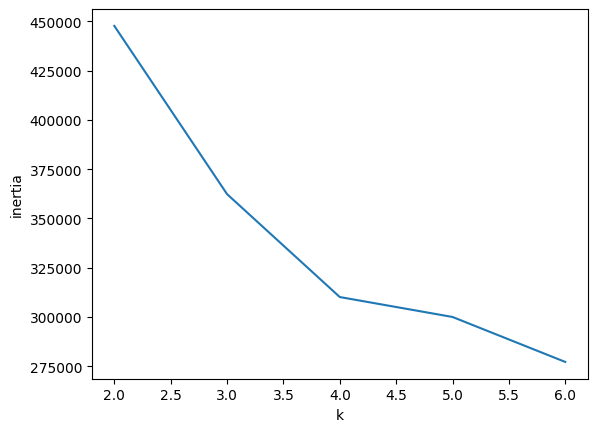
- inertia의 기울기가 변화하는 elbow지점을 선택
- 엘보우 지점보다 더 큰 K를 선택시 군집효과 감소
- 이 그래프에서는 명확하지 않다.
(참조) 한빛 미디어 - 혼자하는 머신러닝 + 딥러닝
https://hongong.hanbit.co.kr/%ED%98%BC%EC%9E%90-%EA%B3%B5%EB%B6%80%ED%95%98%EB%8A%94-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EB%94%A5%EB%9F%AC%EB%8B%9D/

새로운 길