0.K-Nearest Neighbor Classifier
- 새로운 데이터를 특정 값으로 분류
- 현재 데이터와 가장 가까운 k개의 데이터를 찾아 가장 많은 분류 값으로 새로운 데이터 분류
1. 분석준비 - iris dataset
# 분석 준비
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()2. KNN (1) - 전체 dataset
- 데이터 준비
iris = load_iris()
# iris['feature_names']
# 전체 데이터
X = iris.data[:, :2] # X => 'sepal length (cm)', 'sepal width (cm)',
# label
y = iris.target✅ 차원을 줄이기 위해
iris['feature_names']
->sepal length (cm),sepal width (cm),petal length (cm),petal width (cm)
sepal length (cm), sepal width (cm) column 만 분석에 사용
- 기본준비
kn.n_neighbors = 5
kn.fit(X, y)
y_pred=kn.predict(X)
print(y_pred)
print(kn.score(X,y))
✅ kn.n_neighbors = 5
- knn의 하이퍼파라미터로 테스트 데이터가 가장 가까운 n개의 점들의 분류에 의해 결정
연습을 위해 5개의 점을 탐색하도록 설정
✅ kn.fit(X, y)
- KNN 모델에 X,y로 fitting
✅print(y_pred)
- X 를 넣었을때 예측되는 y의 값
✅ kn.score(X, y)
KNN의 정확도 - y_pred와 y의 값이 일치하는 정도
3. KNN (2) - train / test
1) dataset 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.25)
✅ X_train, X_test, y_train, y_test -> train / test set 나누기
X_train-> train 용 datasety_train-> train 용 labelX_test-> test 용 datasety_test-> test 용 라벨
✅ stratify = y -> 샘플링에 관한 옵션
- stratify값을 target 값으로 지정해주면
- target의 class 비율을 유지 한 채로 데이터 셋을 split
- 층화 추출법
✅ test_size=0.25 -> test dataset의 비율
- 전체 데이터 중 test의 비율
- 반대로
train_size를 지정해도 된다.
2) KNN modeling
kn.n_neighbors = 5
kn.fit(X_train, y_train)
kn.score(X_test, y_test)
3) 모델 성능평가
a. classification_report
y_pred = kn.predict(X_test)
print("Classification Report:")
print(classification_report(y_test, y_pred))
- Classification Report:
--- precision recall f1-score support 0 1.00 1.00 1.00 13 1 0.75 0.75 0.75 12 2 0.77 0.77 0.77 13 ----- ----- ----- ----- ----- accuracy 0.84 38 macro avg 0.84 0.84 0.84 38 weighted avg 0.84 0.84 0.84 38
✅ Precision(정밀도)
✅ Recall(재현율)
✅ F1-score:
- F1 스코어는 정밀도와 재현율의 조화 평균
- 값이 높을수록 모델의 성능이 좋다고 판단할 수 있습니다.
✅ Support(샘플수)
b. Confusion Matrix - 혼동행렬
y_pred = kn.predict(X_test)
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
- Confusion Matrix:
0 1 2 0 13 0 0 1 0 9 3 2 0 3 10
✅ 대각선(13, 9, 10)은 각 클래스별로 모델이 올바르게 분류한 샘플의 개수입니다.
✅ 클래스 0은 모두 올바르게 분류되었고,
✅ 클래스 1은 3개의 샘플이 클래스 2로 잘못 분류
✅ 클래스 2의 3개의 샘플이 클래스 1로 잘못 분류
4. Transfomation - Standard Scailing
1) scaler를 이용한 방법
다양한 scailing 중에서 StandardScaler 사용
✅ from sklearn.preprocessing 에서 제공되는 Scaler
- StandardScaler
- MinMaxScaler
- RobustScaler
- Normalizer
from sklearn.preprocessing import StandardScaler
# 다양한 scailing 중에서 StandardScaler 사용
scaler = StandardScaler()
# X_train을 정규화
X_train_scaled = scaler.fit_transform(X_train)
# X_test를 X_train이 사용한 transform 방식으로 변환해줘
X_test_scaled = scaler.transform(X_test)
✅ 반드시 X_test를 변환할때에는 X_train을 사용한 방식으로 변환하여야 한다.
- 이유?
✅ X_test_scaled의 평균은 0이 나오지 않는다.
print(np.mean(X_train_scaled), np.mean(X_test_scaled))(1.058676955624703e-15, -0.02488735843408932)-> 정규화를 할때 X_train의 mean, std를 이용해서 하였기 때문에
2) pipeline을 이용한 방법
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
kn_zscore = Pipeline([('scaler', StandardScaler()),
('knn', KNeighborsClassifier(n_neighbors = 5))])
https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html
Pipeline allows you to sequentially apply a list of transformers to preprocess the data and, if desired, conclude the sequence with a final predictor for predictive modeling.
-> 전처리부터 모델링까지 한번에 수행
Pipeline([('scaler', StandardScaler()), ('knn', KNeighborsClassifier(n_neighbors = 5))])
✅ ('scaler', StandardScaler()) -> scaling
✅ ('knn', KNeighborsClassifier(n_neighbors = 5)) -> modeling
3) 표준화 이전, 이후 score 비교
# 전체 dataset
kn.fit(X, y)
print(kn.score(X, y))
# 표준화 이전
kn.fit(X_train, y_train)
print(kn.score(X_test, y_test))
# 표준화 이후
kn_zscore.fit(X_train, y_train)
print(kn_zscore.score(X_train, y_train))- 전체(표준화 이전) -> 0.8066666667
- 표준화 이전 -> 0.8421052631578947
- 표준화 이후 -> 0.7857142857142857
5. 최적의 K(n_neighbors) 찾기
1) error_rate, valid_accuracy 그래프 그려보기
k_range = np.arange(1,30)
## error_rate
## score의 반대
error_rate = []
for i in k_range:
kn=KNeighborsClassifier()
kn.n_neighbors = i
kn.fit(X_train, y_train)
y_pred_i = kn.predict(X_test)
error_rate.append(np.mean(y_pred_i != y_test))
## Cross-validated accuracy
valid_acc = []
for k in k_range:
kn=KNeighborsClassifier()
kn.n_neighbors = k
# cv = fold 수 / default = 3
scores= cross_val_score(kn, X, y, cv=5, scoring="accuracy")
valid_acc.append(scores.mean())
### 두 지표의 값이 다르다.
# error_rate는 낮으면 좋음, valid_accuracy는 높으면 좋은
# 크기가 다르기 때문에 평균이동
plt.plot(k_range, error_rate - np.mean(error_rate), color = 'blue',
marker='o', markersize=8, markerfacecolor='blue' )
plt.plot(k_range, valid_acc - np.mean(valid_acc), color = 'brown',
marker='o', linestyle='dashed', markersize=8, markerfacecolor='brown')
plt.legend(['error_rate', 'cross_validatd'], fontsize=12, loc='best')
plt.xlabel('Value of n_neighbor(K) for KNN')
plt.ylabel('A - mean(A)')
plt.show()
code 결과 - KNN Graph1
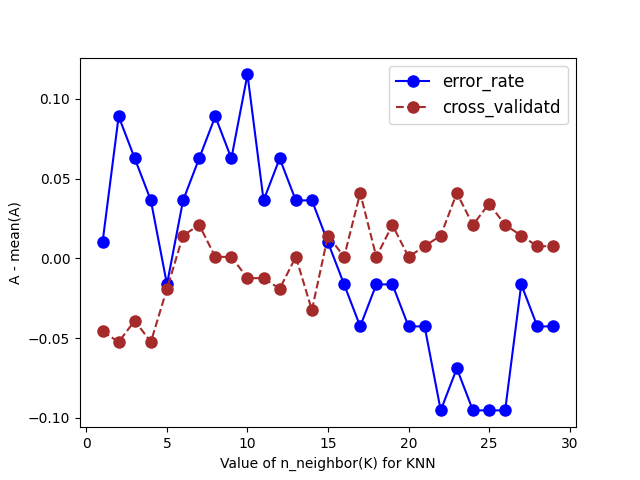
✅ 결과 해석
- 파란선은 낮을수록 / 주황선은 높을수록
- k = 5 or 19 지점 선택
2) GridSearch로 최적값
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
pipeline = Pipeline([('scaler', StandardScaler()),
('knn', KNeighborsClassifier())])
params = {
'knn__n_neighbors':k_range,
'knn__p':[1,2],
'knn__weights' : ['uniform', 'distance'],
}
gs = GridSearchCV(pipeline,
param_grid=params,
scoring='accuracy',
cv=5, # cv = fold 수 / default = 3
n_jobs=-1)
gs.fit(X, y)
print('params', gs.best_params_)
print('score', gs.best_score_)
print('estimator', gs.best_estimator_)
✅ k값을 찾아주는 알고리즘
✅ 원하는 parameter를 param_grid에 넣어서 해당 범위에서 확인 가능
✅ scoring='accuracy' -> 원하는 지표 확인
✅ cv=5 -> cv = fold 수 / default = 3
✅ 결과값 해석
gs.best_params_-> 최적의 parmeter 확인{'knn__n_neighbors': 23, 'knn__p': 1, 'knn__weights': 'uniform'}gs.best_score_-> 최고 점수0.8200000000000001
gs.best_estimator_Pipeline(steps=[('scaler', StandardScaler()), ('knn', KNeighborsClassifier(n_neighbors=23, p=1))])
6. 최적의 K 값을 통해 다시 KNN 모델링
gs_k = gs.best_params_['knn__n_neighbors']
kn.n_neighbors = gs_k
kn.fit(X, y)
print('나누기전 :', round(kn.score(X, y), 4))
kn.n_neighbors = gs_k
kn.fit(X_train, y_train)
print('나누고 :', round(kn.score(X_train, y_train), 4))
kn_zscore = Pipeline([('scaler', StandardScaler()),
('knn', KNeighborsClassifier(n_neighbors = gs_k))])
kn_zscore.fit(X_train, y_train)
print('나누고(z-score) :', round(kn_zscore.score(X_train, y_train), 4))
결과
나누기전 : 0.8067 -> 전체(비표준화) 나누고 : 0.8214 -> train / test (비표준화) 나누고(z-score) : 0.8036 -> train / test (표준화)
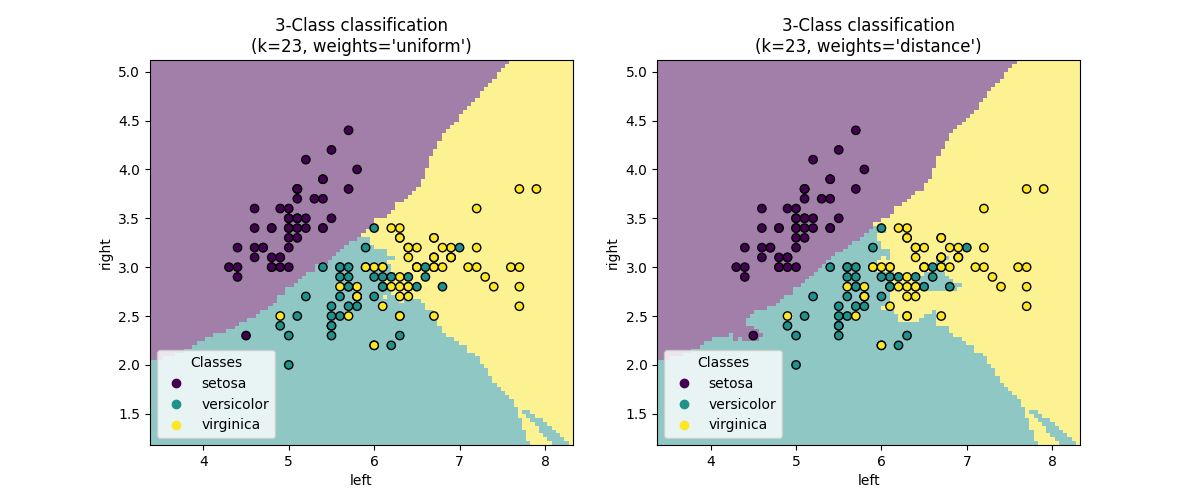
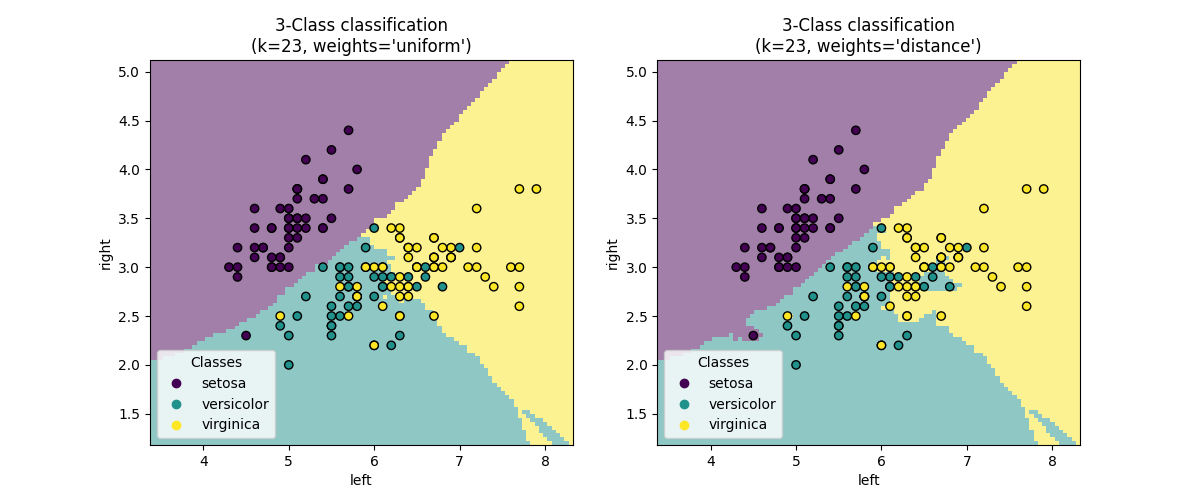
7. 그림으로 표현하기
✅ GridSearch로 구해진 parameter로 그림 그리기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.inspection import DecisionBoundaryDisplay
# 표준화하고, KNN 수행
clf = Pipeline(
steps=[("scaler", StandardScaler()), ("knn", KNeighborsClassifier(n_neighbors=gs_k))]
)
# Create image
_, axs = plt.subplots(ncols=2, figsize=(12, 5))
for ax, weights in zip(axs, ("uniform", "distance")):
clf.set_params(knn__weights=weights).fit(X_train, y_train)
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X_test,
response_method="predict",
plot_method="pcolormesh",
xlabel='left',
ylabel='right',
shading="auto",
alpha=0.5,
ax=ax,
)
scatter = disp.ax_.scatter(X[:, 0], X[:, 1], c=y, edgecolors="k")
disp.ax_.legend(
scatter.legend_elements()[0],
iris['target_names'],
loc="lower left",
title="Classes",
)
_ = disp.ax_.set_title(
f"3-Class classification\n(k={clf[-1].n_neighbors}, weights={weights!r})"
)
plt.show()
A. 참고자료
수업, 자습
[한빛미디어] 혼자공부하는 머신러닝+딥러닝
