0. 들어가며
- 성별과 같은 정보는 'man', 'woman'으로 나뉜다.
- 이러한 정보들은 string형태로 나눠지고, 이는 행렬계산에 부적합
- 행렬계산에 적합한 숫자 형태로 변환하는 연습을 해보고자 한다.
1. labeling
Titanicdataset의embark_townfeature는 탑승지에 관한 정보를 담고 있으며,
클래스의 유형을Southampton,Cherbourg,Queenstown와 같은 형태로 저장하고 있다.- 행렬계산이 용이하도록 숫자형태로 변환하여 정보를 저장
- 하나의 feature에 모든 정보를 저장하는 방법
예시
Southampton-> 0
Cherbourg-> 1
Queenstown-> 2
✅ labeling의 시작은 0 부터 부여
1) 예시
df = sns.load_dataset('titanic')
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df.sex = le.fit_transform(df.sex)
df.embark_town = le.fit_transform(df.embark_town)
df.sex 는 원래
male,female로 구성
-> 이를 1, 0 형태로 변환
df.embark_town 는 원래
Southampton,Cherbourg,Queenstown로 구성
-> 이를 0, 1, 2 형태로 변환
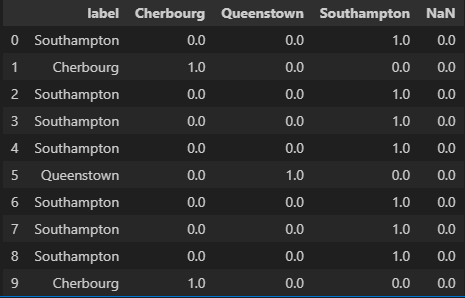
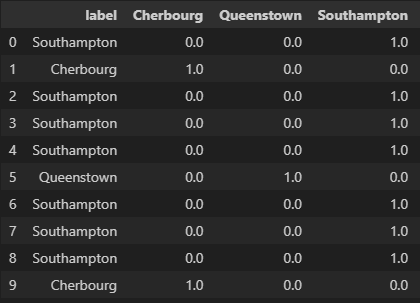
2. one-hot encoding
✅ 더미 형태로 변환하여 새로운 column를 생성하고, 그 column에 해당하는 경우 1의 값을 부여하고, 아닌 경우 0의 값을 부여하는 방식
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse_output=False)
ohe.fit(df.embark_town.values.reshape((-1, 1)))
one_hot_encoded = ohe.transform(df.embark_town.values.reshape((-1,1)))
columns = np.concatenate([np.array(['label']) , ohe.categories_[0]])
#넘파이 어레이형태로 넣어야 되는데 사이킷 런에서는 표현이 통일이 안되 있는 경우가 있어 판다스 벨류로 읽은다음 리쉐입으로 수정하는 것이 필요함
#-1은 남은차원은 알아서 채워라
result = pd.DataFrame(data = np.concatenate([df.embark_town.values.reshape((-1,1)), one_hot_encoded.reshape((-1, 3))], axis=1),
columns=columns)
result.head(10)

새로운 길