
1. 확률 분포
1. R에서 제공하는 확률 분포 , 관련된 함수 목록
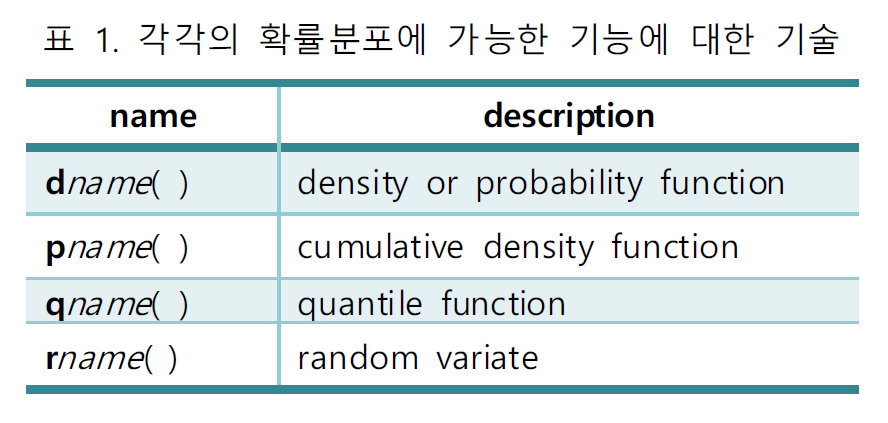
-
표1의 name에 표2의 R name에 해당하는 함수를 조합
-
d: 확률분포
-
p: 누적확률분포
-
q: 분위함수
-
r: 랜덤 생성
# z까지의 누적 확률
pnorm(z)
# cp에 해당하는 표준정규계수 값
qnorm(cp)
# 정규분포에서 n개의 sample 생성
rnorm(n)
# 0과 1사이의 균일분포에서 n개의 sample 생성
rnorm(n, 0, 1)# z까지의 누적 확률
a <- c(round(runif(30)*100))
a1 <- sort(a)
b <- c(round(runif(30)*100))
b1 <- sort(b)
plot(a1, type="l")
lines(b1, lty="dashed", col="orange")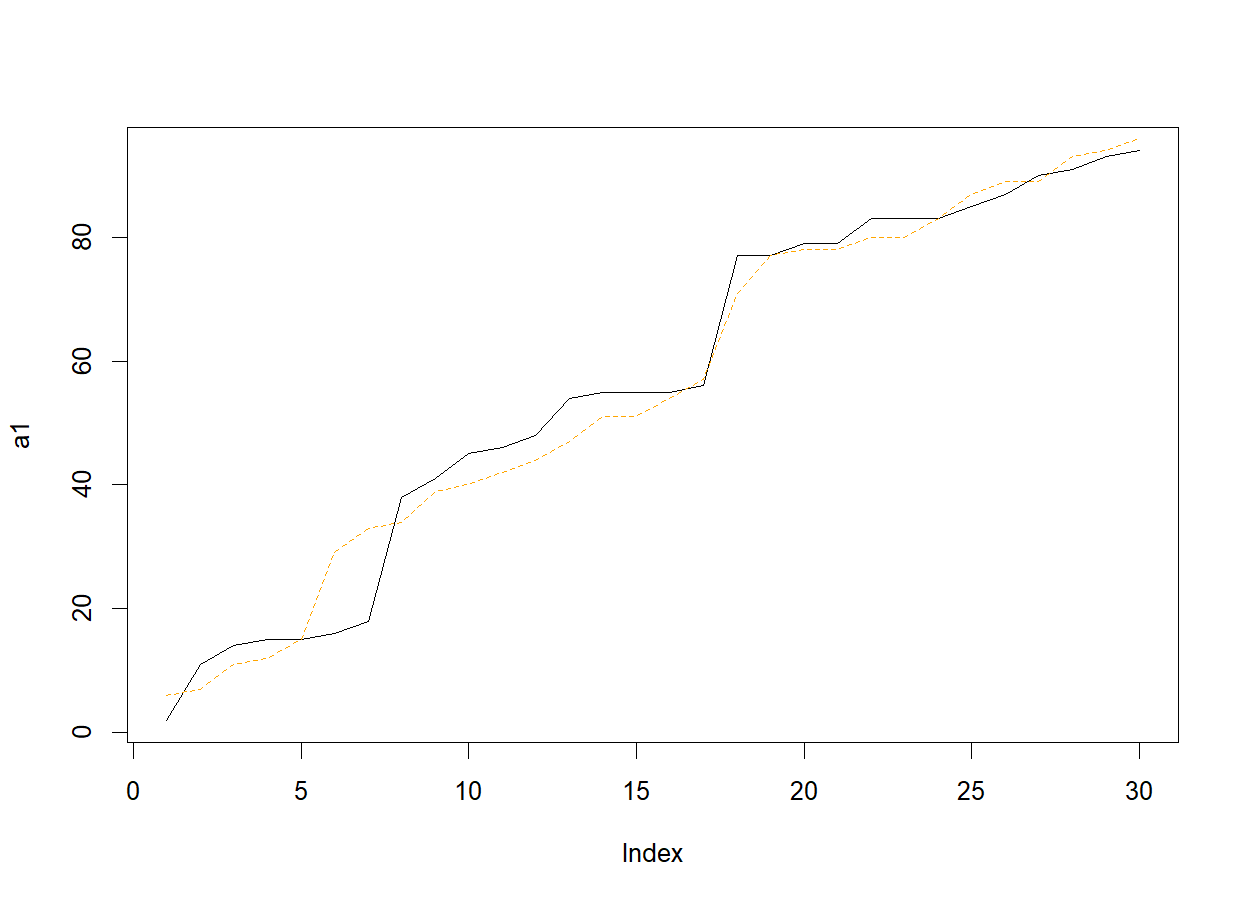
2. 이산확률분포
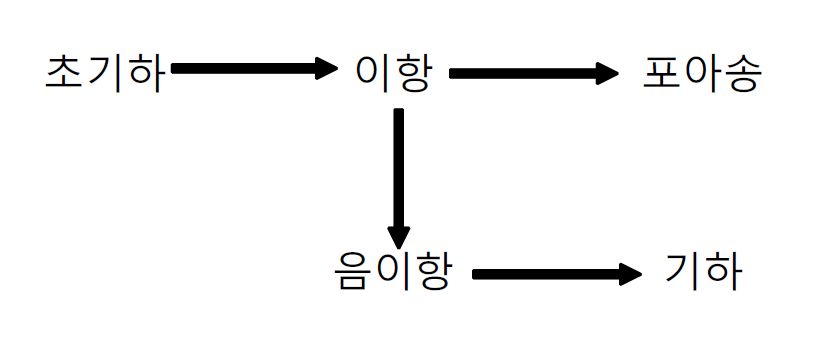
2.1 초기하분포
초기하 분포 : hyper (x,m,n,size)
- x: sample에서 추출된 관심대상의 수
- m: 모집단에 있는 관심 대상의 수
- n: 모집단에 있는 괌심 대상이 아닌 수
- size: 모집단에서 추출한 sample의 크기
예> 200개의 생산 제품 중에 50개의 부적합품이 있을때, 그중에서 10개의 sample을 추출했을때 2개의 부적합품이 나올 확률은
# density 혹은 probability function을 이용
hyper(2, 50, 150, 10)
# cumulative density function을 이용
phyper(2, 50, 150, 10) – phyper(1, 50, 150, 10)# density 혹은 probability function을 이용할 경우
# dhyper( )의 첫번째 인자 2:0은 2부터 0까지의 의미
pp <- dhyper(2:0, 50, 150,10)
names(pp) <- c(‘x=2’, ‘x=1’, ‘x=0’)
pp# cumulative density function을 이용할 경우
p2 <- phyper(2,50,150,10)
p1 <- phyper(1,50,150,10)
p0 <- phyper(0,50,150,10)
pp2= p2-p1
pp1= p1-p0
pp0= p0
resultpp <- c(pp2,pp1,pp0)
names(resultpp) <- c('x=2','x=1','x=0')
resultpp
# P(4 ≤X≤7)=F(7)-F(3)
# sum(dhyper(4:7, 30, 30, 10))
= phyper(7, 30, 30, 10) - phyper(3, 30, 30, 10)2.2 이항분포
이항분포 : binom(x,size,prob)
- x: 통계적 실험에서 관심 대상이 나온 수
- size: 통계적 실험의 시행 횟수
- prob: 통계적 실험의 매 시행에서 관심 대상이 나올 확률
예. 어느 공장에서 생산되는 제품은 5000개 로트 단위로 생산되며 한 로트당 50개의 제품을 무작위로 추출하여 3개 이하의 부적합품이 나오면 합격시키고, 4개이상의 부적합 품이 나오면 불합격 시킨다. 이 공장의 공정 부적합품률은 5%로 알려져있다. 그러면 임의로 한 로트를 검사했을 때 로트가 합격될 확률을 구하라.
# density or probability function을 이용할 경우
p3 <- dbinom(3:0, 50, 0.5)
names(p3) <- c(‘x=3’, ‘x=2’, ‘x=1’, ‘x=0’)
p3
# cumulative density function을 이용할 경우
p3 <- pbinom(3, 50, 0.05)
p3 2.3 포아송분포
포아송 분포 : pois(x,lambda)
- x: 단위시간 당 (또는 길이, 면적당)관심 대상의 발생 횟수
- lambda : 단위시간 당 (또는 길이, 면적당) 관심 대상의 평균 발생 횟수
예. 유리 제조 공정에서 1m^2 당 평균 2개의 기포가 있는 것으로 알려져 있다.
임의의 공정이 끝난 유리 1m^2 에 1개의 기포가 있을 확률을 구하여라
# density or probability function을 이용할 경우
dpois(1, 2)
# cumulative density function을 이용할 경우
ppois(1, 2) – ppois(0, 2)예. 단위당 평균 결점 수가 1.5개인 제품을 생산하는 공정 .
# 10개의 단위 제품에서 20개의 결점이 발견될 확률
dpois(20, 15)
# 하나의 단위 제품에서 2개의 결점이 발견될 확률
dpois(2, 1.5)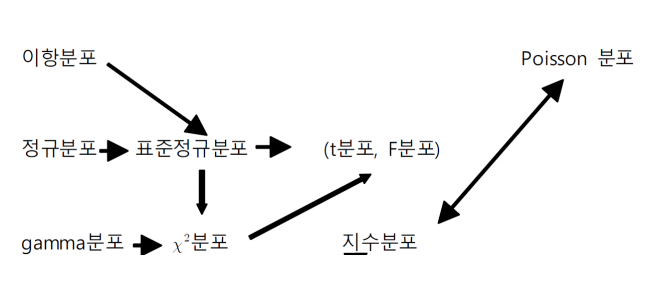
3. 연속확률분포
3.1 정규분포
정규분포
pnorm(z,mean,sd)
pnorm(1.96,0,1) : 표준 정규분포에서 1.96까지의 누적 확률
qnorm(cp,mean,sd)
qnorm(0.975,0,1) : 표준 정규분포에서 누적확률 97.5%에 해당되는 x축의 값
예. 엔진의 수명이 평균3년, 표준편차가 0.5년인 정규분포를 따른다고 알려져있다. 이 엔진의 생산회사에서 현재 엔진의 무상보증기간을 2년으로하고 있다면, 이 엔진 구입 후 무상보증기간 내에 고장이 발생할 확률으 구하라 .
z=(2-3)/0.5 # 표준화 시킨 값 이용, 표준정규분포를 이용할 경우
pnorm(z)
pnorm(2,mean=3, sd=0.5pnorm(-3:3)
print(pnorm(-3:3),ditits=3) #첫번째 값을 3자리 까지 표시하면 전체 5자리
round(pnorm(-3:3),3) # 소수점이하 3자리가지 학생들의 지능지수를 측정해 보니 평균이 100이고, 표준편차가 10인 정규분포를 따랐다. 이때 지능지수가 100에서 110사이인 학생들의 비율을 구하여라
z1<-pnorm(100,mean=100,sd=10)
z2<-pnorm(110,mean=100,sd=10)
# 지능지수가 100과 110인 사이인 비율
z2-z1장학생 선발을 위한 시험에서 정수의 평균이 60점, 표준 편차가 15점인 정규분포를 따르는 결과가 나왔다. 응시한 학생 중 상위 10%학생에게 장학금을 주려고 한다. 그러면 장학금을 수령할 수 있는 점수의 하한선을 구하라 .
p<-1-0.1
qnorm(p,mean=60,sd=15)
qnorm(p,60,15)
- 자료의 정규성을 알아보는 방법 : qq-plot
- 자료의 quantile 값과 표준정규분포의 quantile 값을 각각 비교하여 자료가 정규성을 갖는지 체크
- 대부분의 통게적 분석은 정규분포를 가정하므로 정규성 체크가 필요
#자료의 정규성 체크
x<-rnomr(50) #표준정규분포에서 50개의 값 생성
qqnorm(x)
qqline(x,col=2)
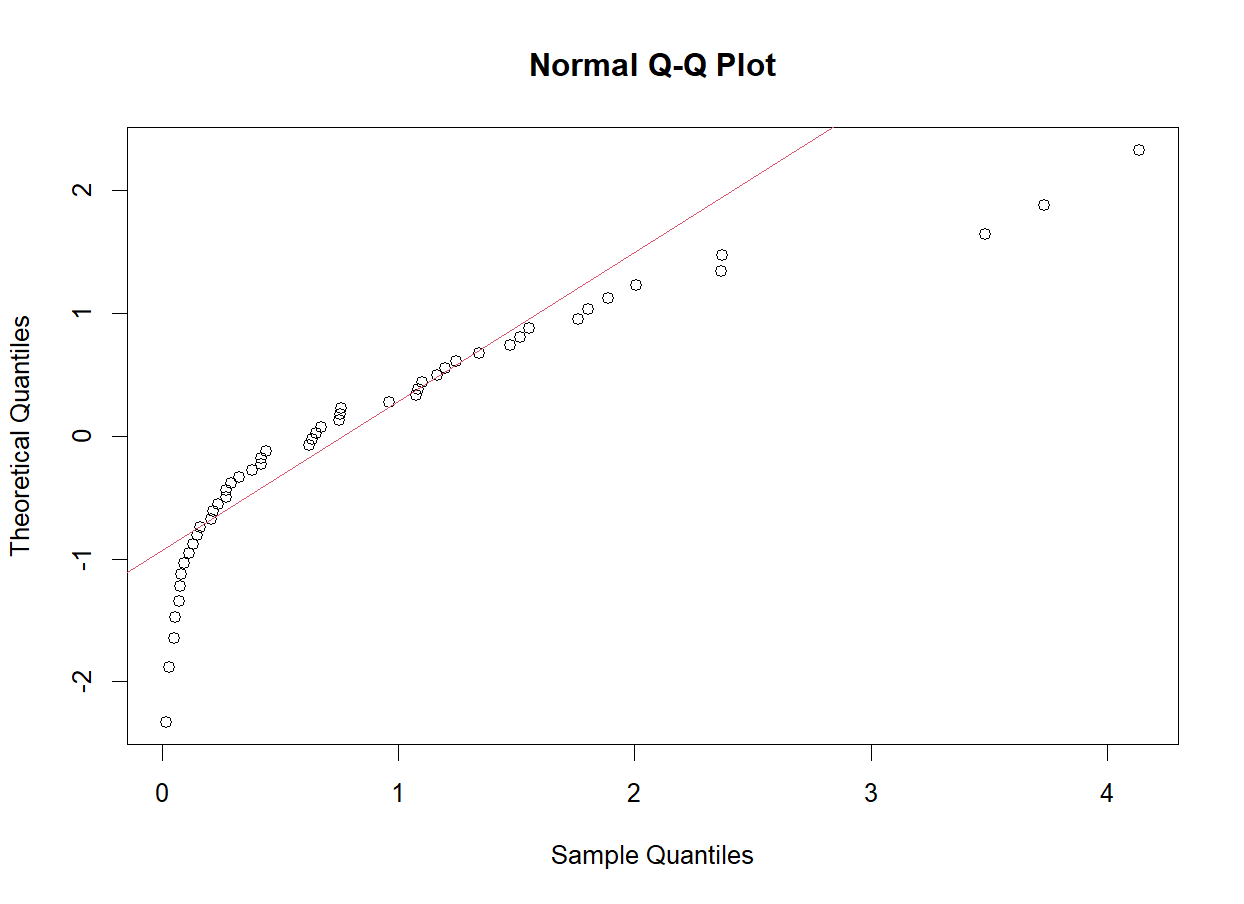
y<-rexp(50) #지수분포에서 50개의 값 생성
qqnorm(y,datax=T)
qqline(y,datax=T,col=2)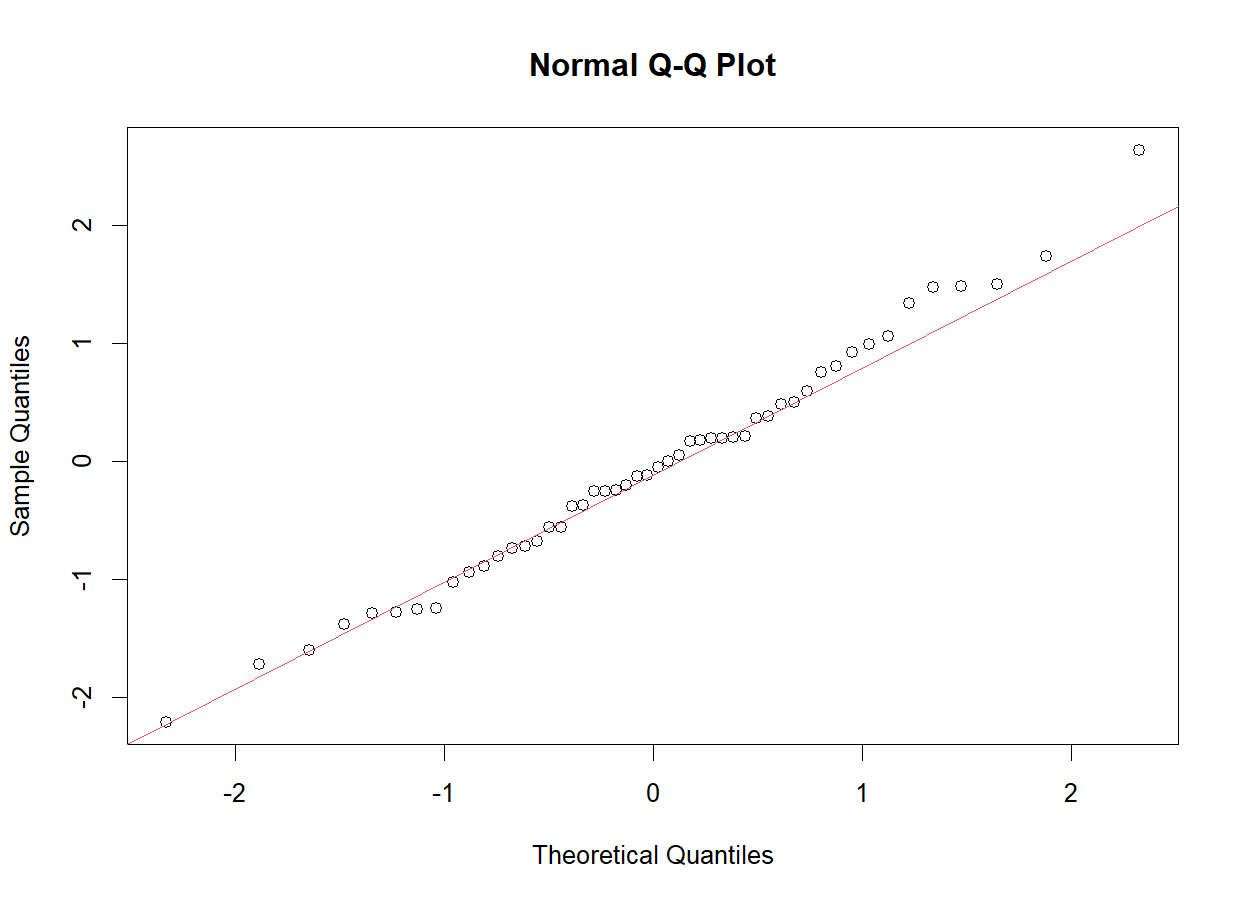
3-2. 이항분포의 정규근사
- 이항분포에서 p가 0.5이면 좌우 대칭이 되므로, sample의 크기가 충분히 크다면 정규 근사를 할 수있다.
- 또한 p가 0또는 1에 가깝다 하더라도 n이 커지면 정규근사를 이용할 수 있다. np>5 , n(1-p)>5
5개의 보기중 한개를 선택하는 100문제의 수능 문제를 아무런 지식 없이 임의의 답을 했을 때, 맞힌 정답의 수가 25개이상 30개 이하일 확률을 구하여라
#이항분포의 평균 및 분산 구하기
p<-1/5
n<-100
mu<-n*p
var<-n*p*(1-p)
#정규근사로 25개이상 30개 이하의 문제르 맞혔을 누적확률
p1<-pnorm(24.5,mean=mu,sd=var^0.5)
p2<-pnorm(30,mu,var^0.5)
p2-p1 # 확률3-3 t분포
- t분포는 모수(모분산)를 알지 못하는 상황에서 정규분포를 이루는 모집단에서 추출한 표본의 크기가 작을 대의 추정과 검정에 사용
- t분포는 자유도(degree of freedom : df=n-1)에 따라 서로 다른 분포를 가짐.
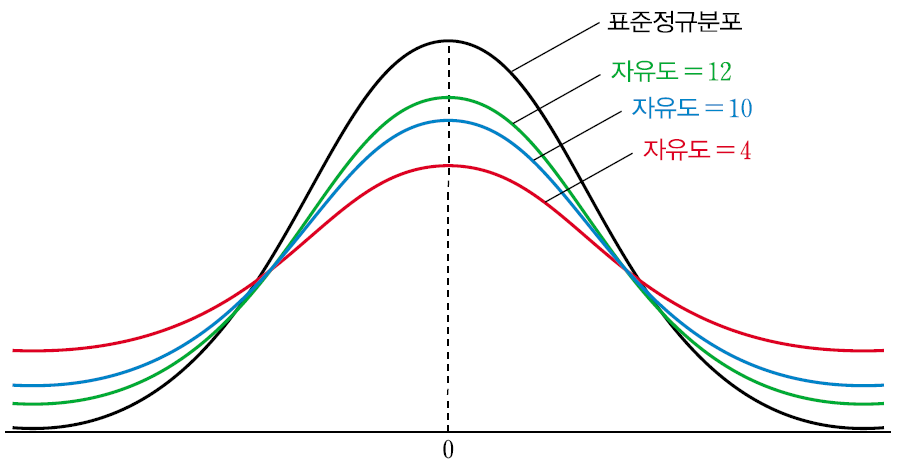
# t분포(df=n-1)
pt(t,df) #자유도가 df일 때, t분포의 t까지의 누적 확률
qt(cp,df) #자유도가 df일 때, 누적확률 cp에 해당되는 t 값
#예. 자유도가 12인 t분포에서 P(-1.356<T<2.179)를 구하여라.
t1<-pt(-1.356,12)
t2<-pt(2.179,12)
t2-t130명을 대상으로 한 시험에서 성적의 평균이 60점이고, 표준편차가 10점이라고 하자. 이때 상위 20%에 해당되는 원 점수를 구하여라.
#모집단을 따르는 정규분포, 하지만 모수에 대한 정보가 없음
#Z대신 t분포 사용
#원 점수는 역 표준화
t1<-qt(0.8,29)
t1*10+603-4 카이제곱분포
카이제곱분포
pchisq(c,df) #자유도가 df일때, 카이제곱 분포의 c까지의 누적확률
qchisq(cp,df) #자유도가 df일대, 누적확률cp에 해당되는 카이제곱 값
자유도가 10인 카이제곱분포를 따르는 변수X가 5부터 15사이에 있을 확률 p(5<X<15)를 계산하여라
ch1<-pchisq(5,10)
ch2<-pchisq(15,10)
ch2-ch13-5 F분포
F분포
pf(f,df1,df2) #자유도가 df1,df2일 대 , F분포의 f까지의 누적확률
qf(cp,df1,df2) #자유도가 df1,df2일 대, 누적확률 cp에 해당되는 F값
자유도가 10과20인 F분포에서 p(5<F<15)를 구하여라
f1<-pf(5,10,20)
f2<-pf(15,10,20)
f2-f1.3-6 지수분포
- 단위 시간 당(길이,면적 당) 관심 대상의 평균적으로 발생할 확률
지수분포
exp(t,lambda)
1. t: 관심 대상 발생의 관찰 시간(길이,면적)
2. lambda : 단위 시간 당 (길이, 면적 당) 관심대상의 평균 발생 비율
어떤 은행에 도착하는 고객의 수는 시간당 평균 20명으로 알려져 있다.
이 은행에 5분동안 한명의 고객도 도착하지 않을 확률은 얼마인가.
P(T>=t)=1-P(T<t)
P(T<t)=pexp(t,lambda): 누적확률
p<- pexp(5,1/3)
1-p4. 추정
4-1 추정
- 집단으로부터 선정한 표본으로부터 얻은 정보를 이용하여 미지의 모수를 추측하는 과정
- 모수의 추론 과정
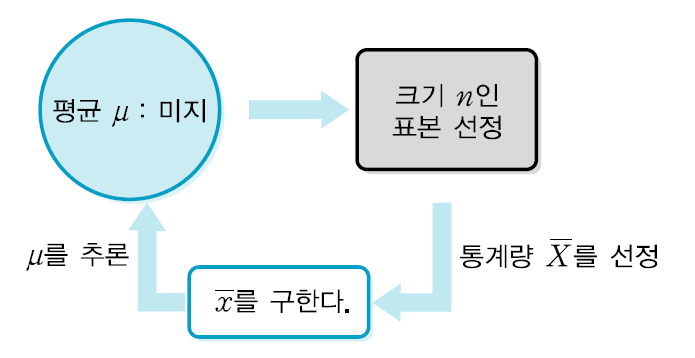
점추정
- 점추정은 모수를 특정한 수치로 표현하는 것
- ex, 통학 시간에 대해 점추정은 30분, 40분과 같이 특정한 수치로 표현
구간추정
- 구간추정은 모수를 최소값과 최대값의 범위로 조정하는 것
- ex, 통학 시간에 대해 구간추정은 30분~40분과 같이 범위로 표현
4-2 점추정
- 모수의 참값에 대하여 최적의 추정값을 구하는 과정

4-3 구간추정
- 모수의 참값이 포함될 것으로 믿어지는 구간을 추정

4-4 모평균의 구간추정
#data 입력
x <-c(75,63,49,86,53,80,70,72,81,80,69,76,85,95,66,77,77,63,58,74,68,90,82,59,60)
#95% 신뢰구간
t.test(x,conf.level=0.95)
#99% 신뢰구간
t.test(x,conf.level=0.99)#. 95% 신뢰구간
t.test(x, conf.level = 0.95 )
One Sample t-test
data: x
t = 31.1724, df = 24, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
67.53176 77.10824
sample estimates:
mean of x

#. 99% 신뢰구간
t.test(x, conf.level = 0.99 )
One Sample t-test
data: x
t = 31.1724, df = 24, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
99 percent confidence interval:
65.8311 78.8089
sample estimates:
mean of x
72.32
4-5 두 모평균 차의 구간 추정
한반에 6명인 학생들의 학업성취도 평가를 위해, 방과 후 수업을 실시 하기 전과 실시한 후의 성적 변화를 알아보고자 한다. ( 대응표본으로 등분산을 가정하고, 90%의 신뢰구간 추정과 양쪽검정 실시)
#data 입력.
before <-c(77,80,90,52,63,76)
after <-c(80,81,95,54,62,70)
#option을 활용한 구간 추정
t.test(before,after,paired = T, var.equal = T, alternative= "two.sided",conf,level=0.9)t.test(before, after, paired = T, var.equal =T, alternative="two.sided", conf.l
evel =0.9 )
Paired t-test
data: before and after
t = -0.4264, df = 5, p-value = 0.6875
alternative hypothesis: true difference in means is not equal to 0
90 percent confidence interval:
-3.817138 2.483805
sample estimates:
mean of the differences
-0.6666667
