프로그래머스 - Level 2
1.N개의 최소공배수
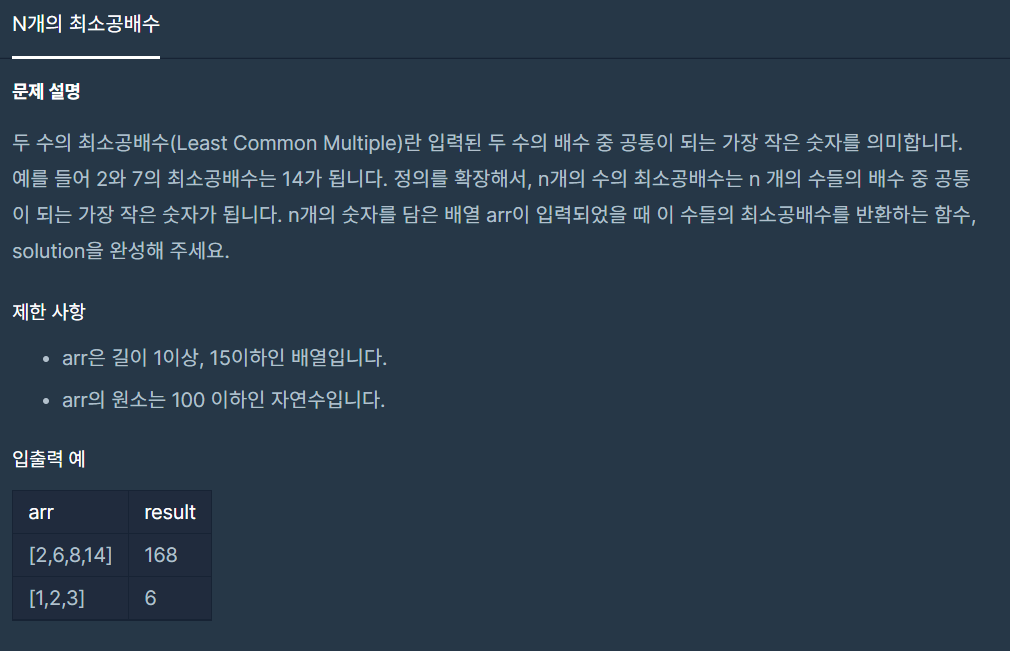
유클리드 호제법을 활용하여 GCD(최대 공약수)을 구하고 GCD를 활용하여 LCM(최소 공배수)을 구하는 문제다....유클리드 호제법 https://namu.wiki/w/%EC%9C%A0%ED%81%B4%EB%A6%AC%EB%93%9C%20%ED%98%B8%E
2.JadenCase 문자열 만들기
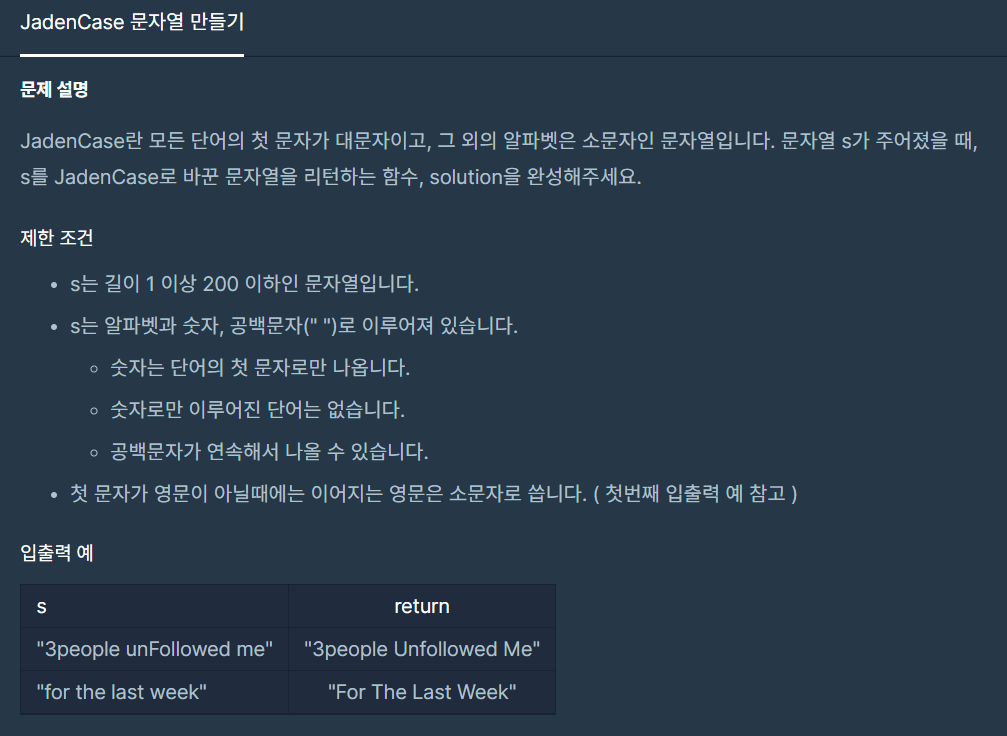
첫 문자는 대문자 나머지 문자는 소문자로 바꾸어야 하는 문제이다.(첫 문자가 숫자이면 상관x) 자바는 파이썬과 다르게 첫 문자만 바꾸는 메소드가 존재하지 않으므로 1\. 첫 문자와 나머지 문자들을 분리2\. 첫 문자는 대문자 나머지 문자는 소문자3\. 합치는 작업을 직
3.행렬의 곱셈

수학에서 배운 그 행렬의 곱셈이 맞다. 각 테이블의 행과 열 곱의 합을 계산하는 문제이다.https://ko.wikipedia.org/wiki/%ED%96%89%EB%A0%AC\_%EA%B3%B1%EC%85%88의외로 많은 시간이 소비되었던 부분이다. 2차원배
4.피보나치 수
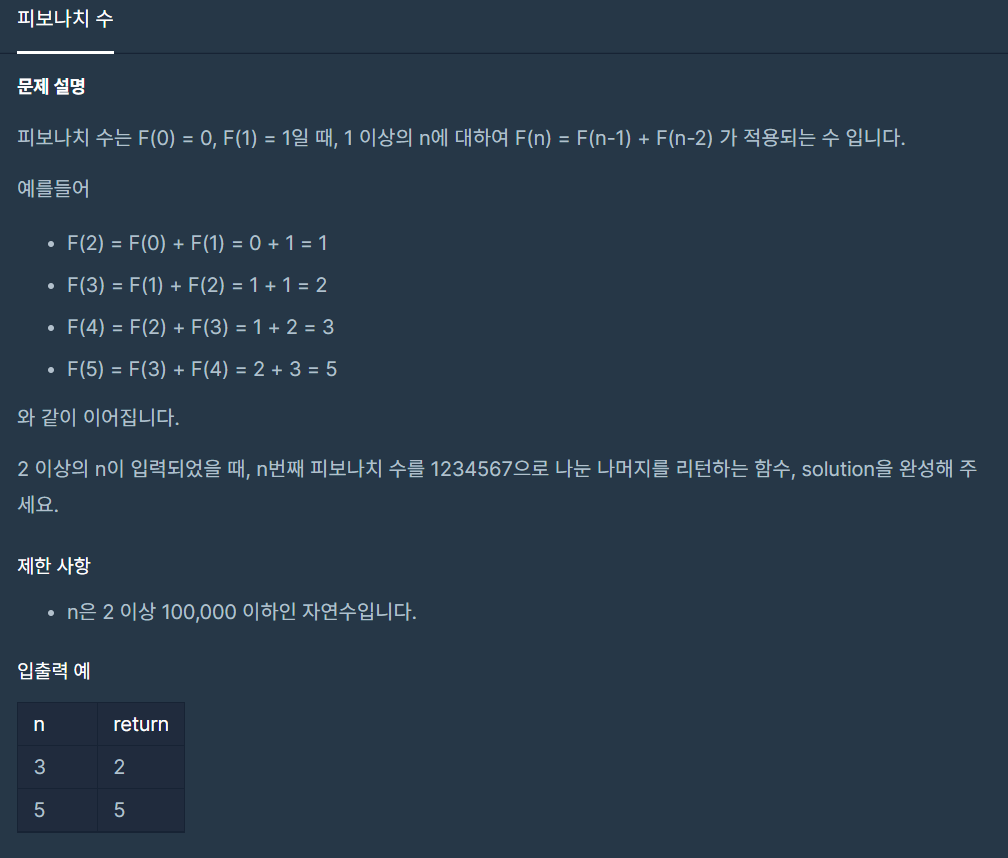
반복문을 이용하여 피보나치 수열을 구해야 하는 문제이다. 피보나치 수열은 0,1,1,2,3,5,8,13,....등 현재 값과 이전값을 더하여 다음값을 구하는 반복 수열 문제이다.반복문을 이용하여 피보나치 수열을 구해야 하므로 로 변수를 선언하고for문으로 다음 값을 구
5.최솟값 만들기
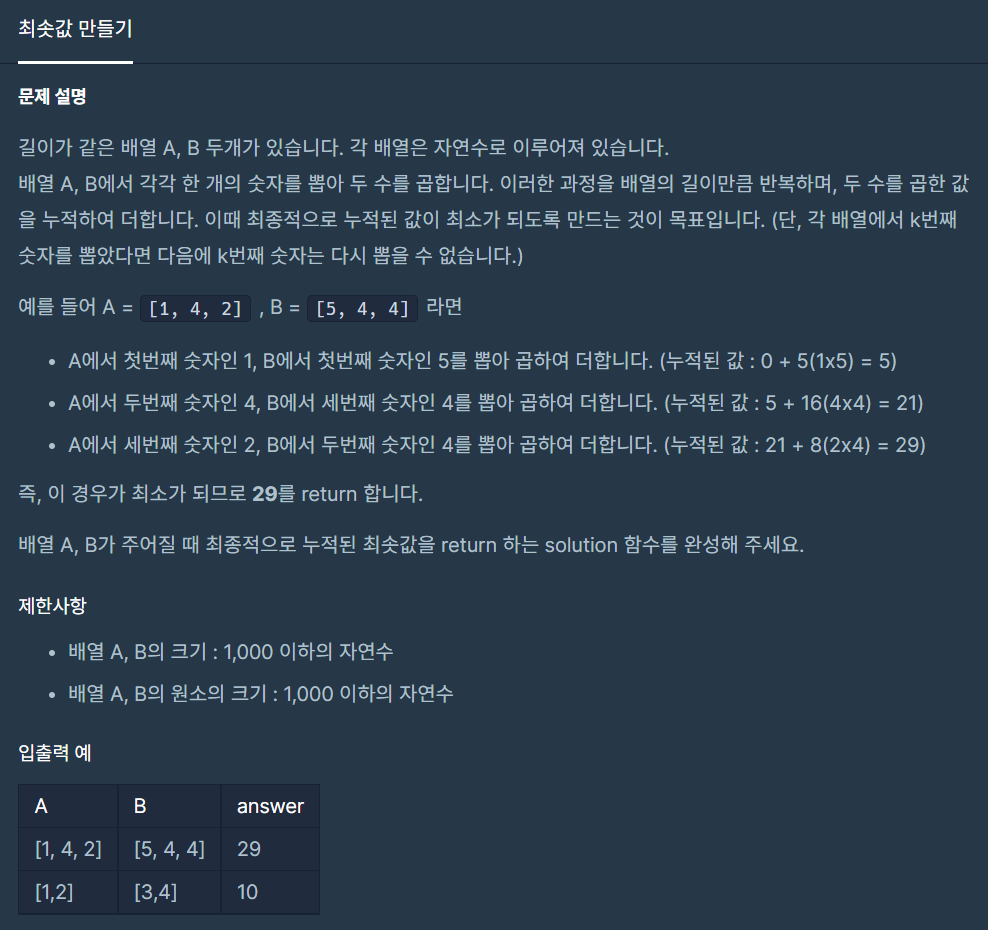
두 행렬의 요소들을 순서대로 곱해서 최종 값이 최소여야 하는 문제이다. 곱들의 합이 최소가 되기 위해선 순서가 필요해 보인다. 정렬이 필요하다.막상 배울땐 어영 부영 넘어간 API부분이 코테연습할땐 아쉽고 더 열심히 할껄 싶다. 직접 정렬을 구현해되 되겠지만 사실 기억
6.최댓값과 최솟값
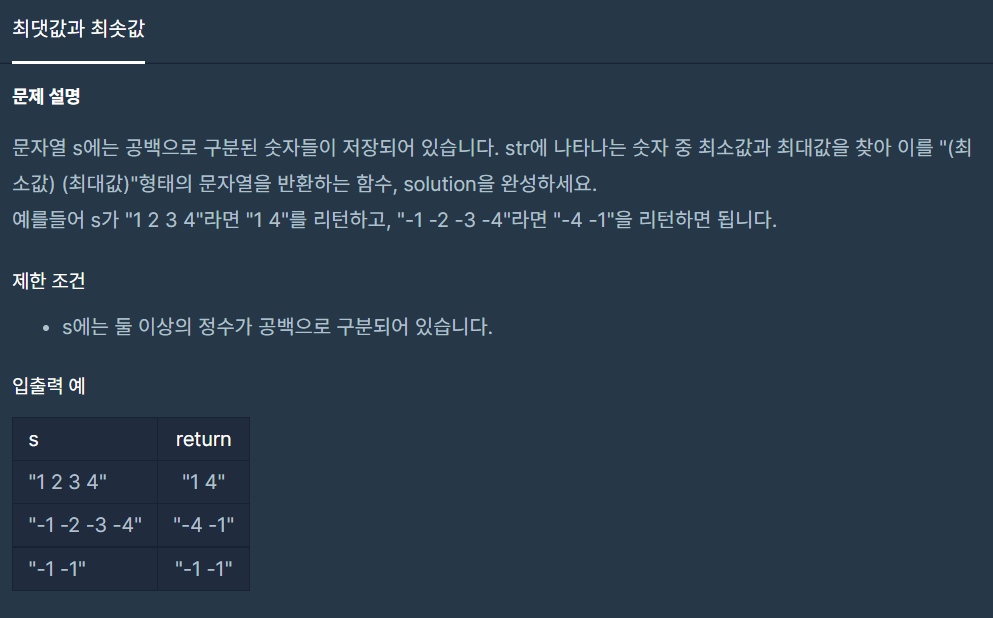
문자열의 값들을 구분해야 하고 최댓값과 최솟값을 구해야 한다!처음엔 Arrays클래스를 이용하여 정렬후 최솟값(0번 index)와 최댓값(마지막 index)을 문자열에 더해 반환하는 코드를 작성 하였으나 다른사람의 풀이 중 정렬할 필요 없이 최댓값과 최솟값을 바로 구하
7.숫자의 표현
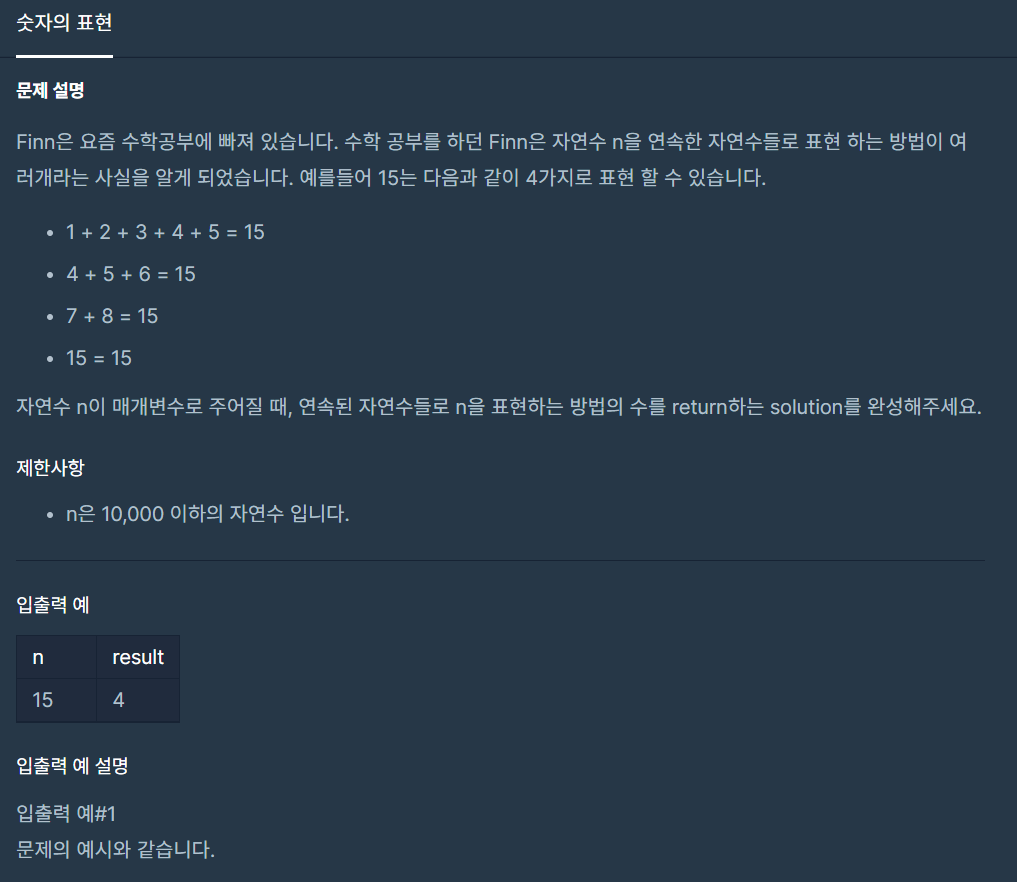
연속된 자연수만 사용하는 것이 핵심이다. 각 갯수는 한 조합 밖에 구성 될 수 밖에 없을 것 같다.연속된 자연수로 구성될 수 있는 갯수가 몇 개인가와 같은 말인 것 같다.만약 연속된 자연수로 구성이 될 수 있는 갯수라면 적은 동안 더하다가 마지막에 합이 일치하고, 그렇
8.땅따먹기
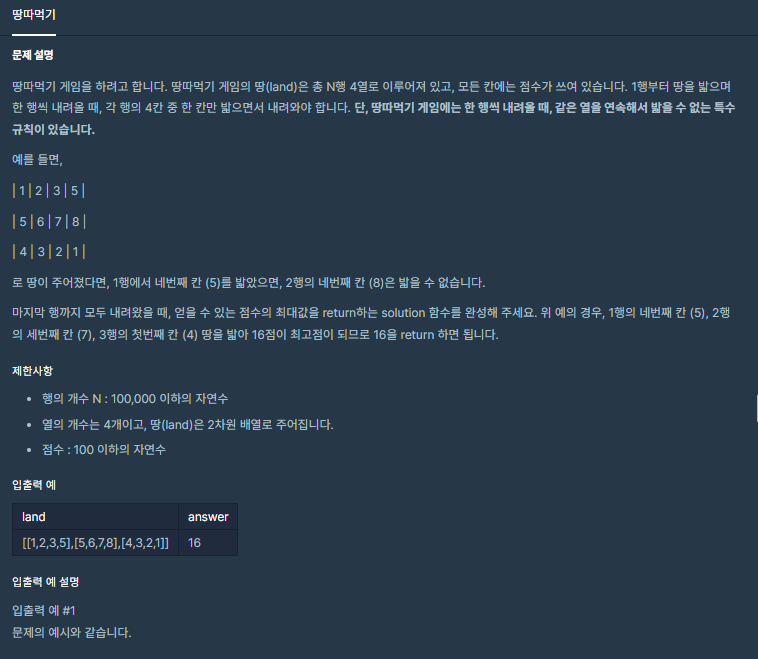
1행부터 이전 열을 제외한 최대값만 구하려하면 안될것 같다.2행에 8이 아니라 아주 큰 수면 1행부터 최대값을 고르며 진행 하는건 옳지 않다고 생각하여 최대값이 있는 행을 미리 구하고 위의 행들 아래 행들을 따로 구하려고 했다. 테스트 케이스는 통과했지만 예제는 전부
9.다음 큰 숫자
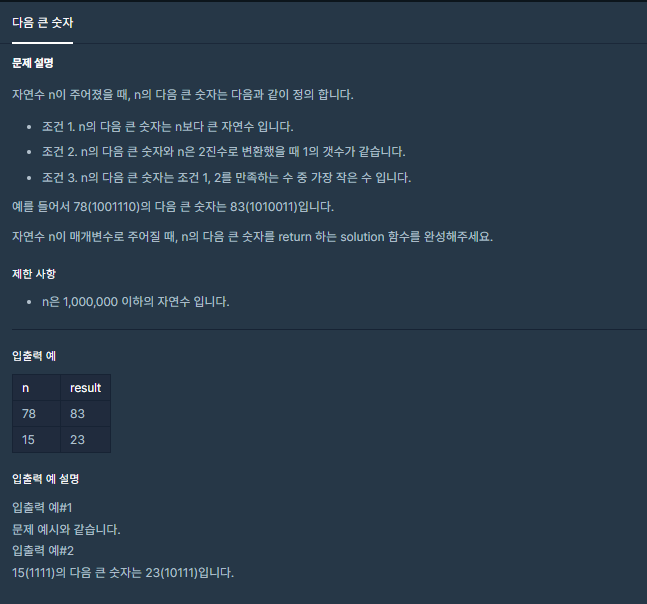
이진수 변환시 1의 갯수가 중요한 문제이다. 이진수로 간단히 바꿀 수 있는 API가 있다면 사용하자! 이진수를 나머지 연산(%)으로 직접 구하였다. 또 1의 위치를 여러 가지 경우로 나누어 직접 옮기면서 도저히 답을 구할 수 없었다.Integer.toBinaryStri
10.[3차] n진수 게임
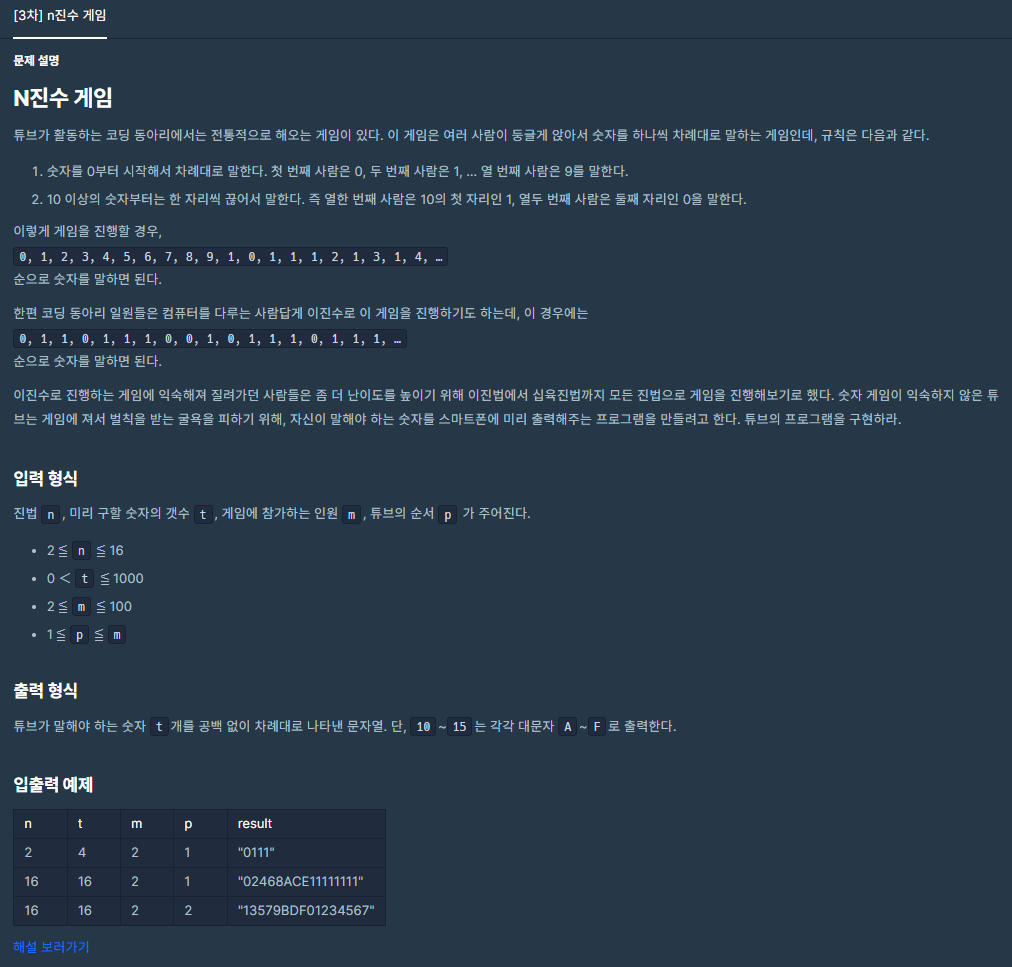
예전에 1의 개수를 비교하던것과 달리 여러 진수들이 나누어 질 수 있으므로 직접 진수를 구하는 로직을 구성해야 한다. 구성한 다음 순서에 맞춰 값들을 추가하자!오랫만이기도 하고 해서 나머지 연산을 사용한다는건 알았는데 간단하게 또 문자를 이용하여 10진수 이상은 기억이
11.올바른 괄호
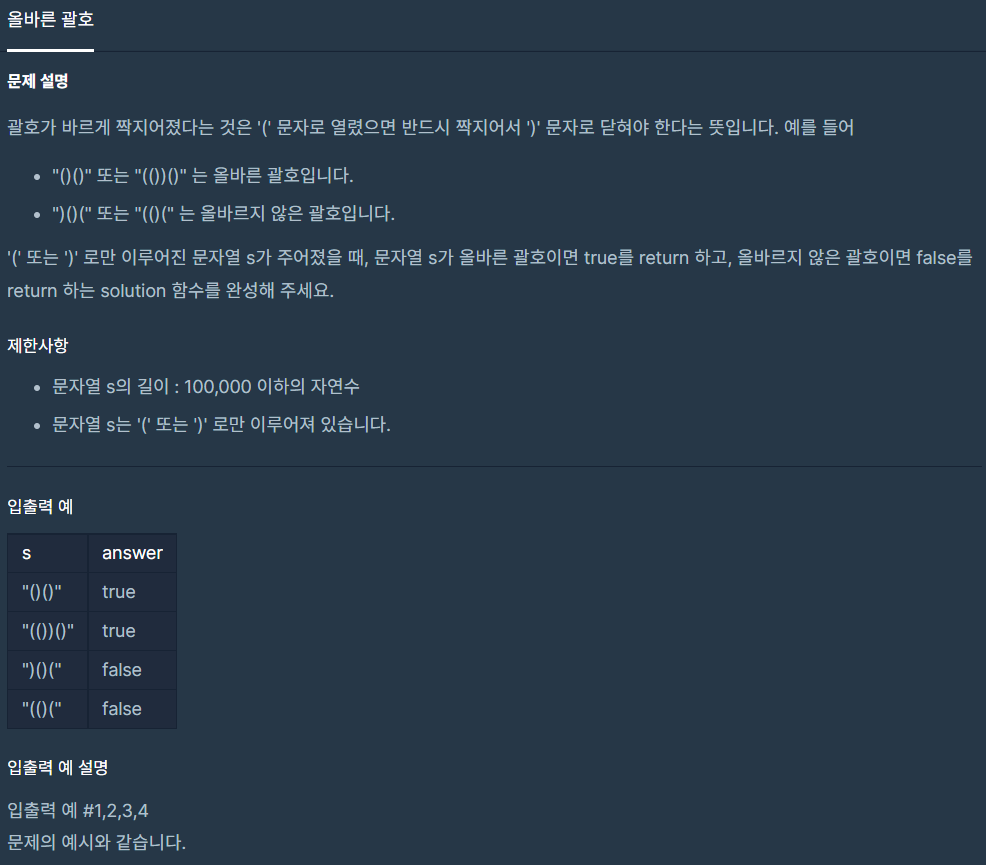
열린 괄호 닫힌 괄호에 따라 true, false를 결정하는 문제이다.1.항상(가 있어야만 )가 있을 수 있다. 즉 먼저 있어야 한다. 2.(보다 더 많은 수의 )가 있으면 false이다.즉 항상 '('의 수 > ')'의 수을 만족해야 한다. count변수에 (가 오면
12.파일명 정렬

HEAD,NUMBER,TAIL로 나누고 HEAD를 비교 후 정렬, 만약 HEAD가 같다면 NUMBER를 비교후 정렬 하는 문제https://subin-0320.tistory.com/103Comparator<E>클래스와 compare메소드 오버라이딩에 대하
13.가장 큰 정사각형 찾기
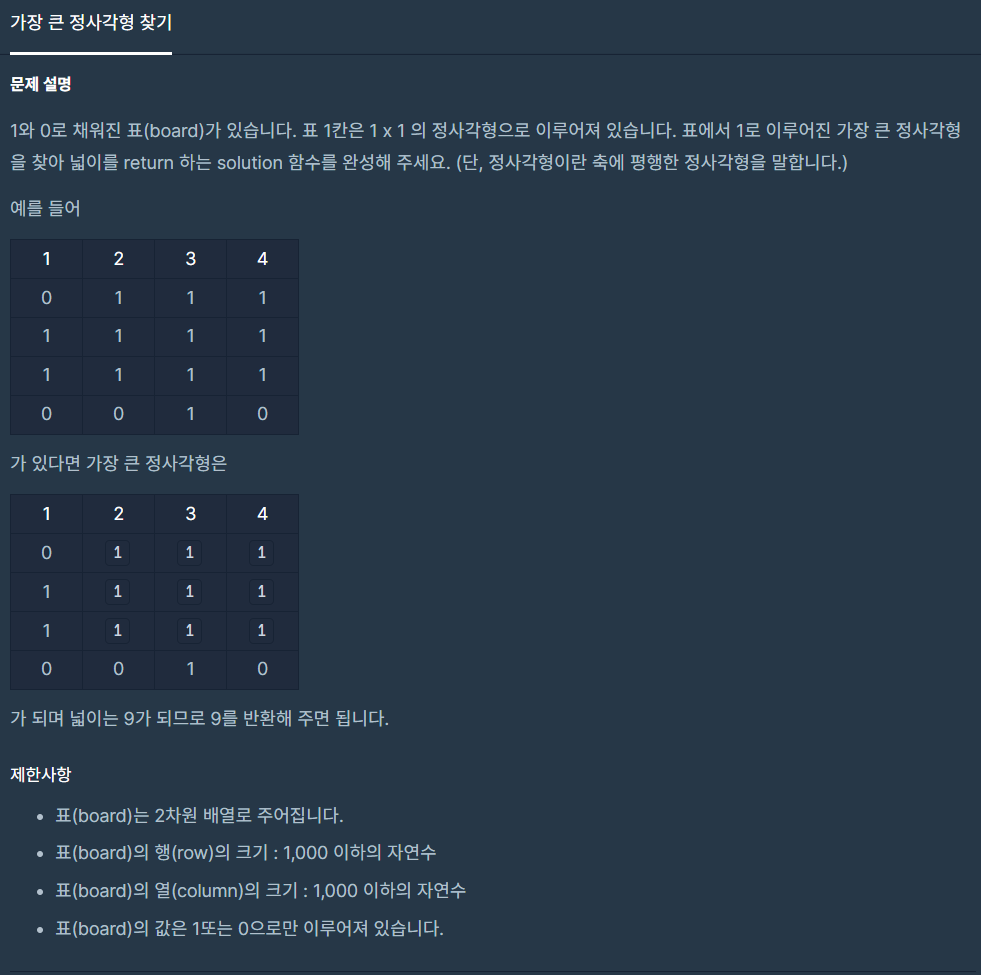
최대한 큰 1로 이루어진 정사각의 크기를 구하는 문제이다. 0이면 패스 1이면 점점 크기를 증가시켜가며 정사각형을 구성하고 있는지 체크 해야하므로 반복문이 아주 많이 겹칠것 같다.1인 위치를 찾고 행과 열을 +1 씩 해 가며 정사각형 여부를 판단하였으나, if() br
14.방문 길이
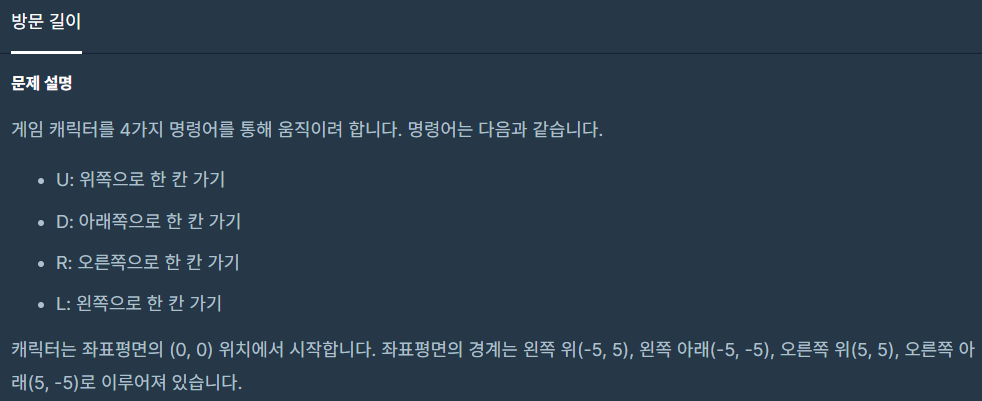
처음 문제를 풀면서 -5~5 사이 좌표값을 가지면 되겠다 생각을 했었다. 그래서 5와 -5를 벗어나는 이동은 계산하지 않으면서 풀었었다.\-5와 5사이의 X,Y 좌표를 가져야 한다. 따라서 넘어가는 경로는 고려되지 않아야 함중복된 경로를 어떻게 연산하지 않을지는 가장
15.스킬트리
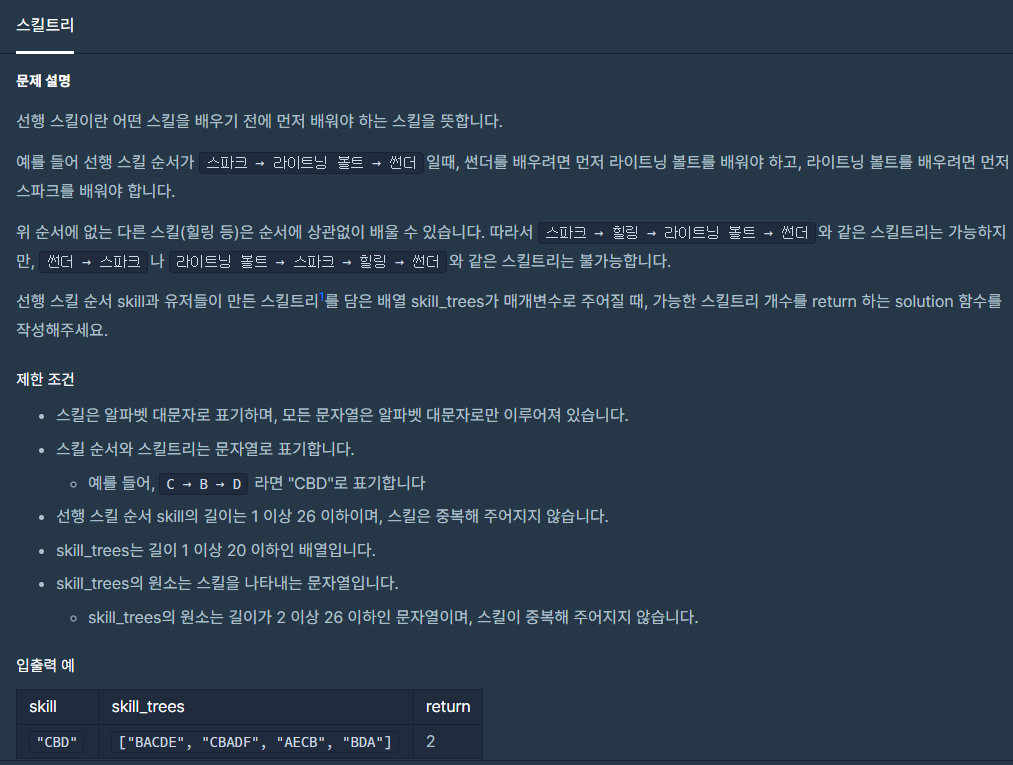
스킬트리에 있는 스킬들의 순서가 올바른지 선행 관계를 확인 하는 문제이다.skill에서 한문자 skill_trees\[i]에서 한문자씩 비교하며 skill에 없는 문자는 건너뛰고 있으면 순서를 비교하는 로직을 구현했었다.정규표현식으로 스킬트리를 비교하는 로직이 있어서
16.점프와 순간 이동
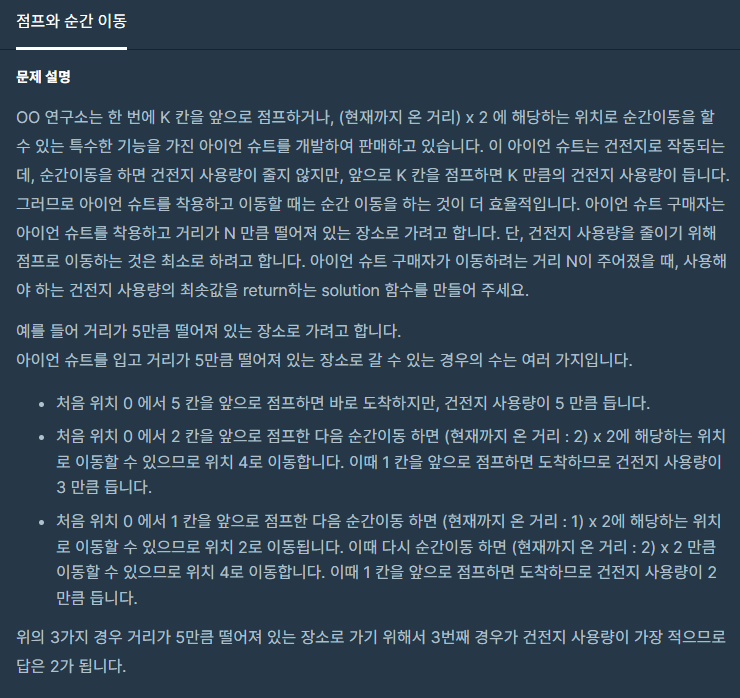
점프는 배터리 이동 거리만큼 소모하지만 순간이동은 소모하지 않으므로, 최소한의 배터리로 이동하기 위해선 순간이동을 최대한 많이 활용 해야 한다.순간이동은 무조건 왔던 거리의 두배만큼 갈 수 있다. 즉 시작점부터 도착점까지 1.맞게 도착하는지 2.넘어가는지 3.부족한지
17.캐시
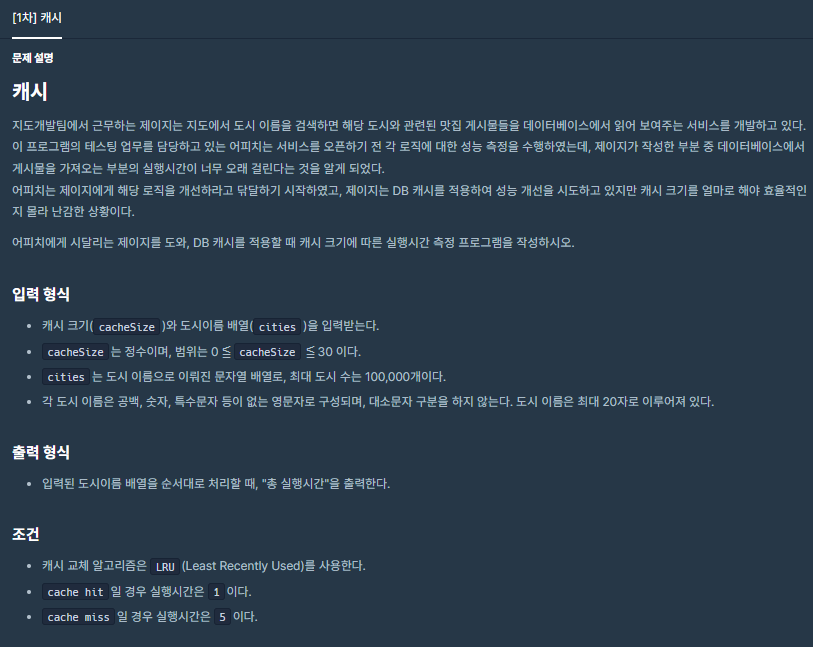
캐시 Hit와 miss를 구분하여 answer에 값을 저장하고 비교하는 문제이다. 캐시와 LRU에 대해서 사전에 알고 있어야만 문제를 풀 수 있다.캐시는 사전에 나온 값들을 미리 저장하고 있다가 새로 들어온 값이 캐시에 있으면 hit, 없으면 miss로 구분한다.그렇다
18.구명보트

배열의 원소에 따라 답이 달라지므로 정렬이 필요해 보인다. 원소의 크기에 따라 혼자냐 둘이 타냐가 결정 되기 때문에 정렬이 필요하다. Arrays.sort(배열)로 오름차순으로 정렬 하였다.최소의 보트 횟수 즉 가능하면 둘이 태울 수 있어야 한다.제일 작은 것과 그다음
19.주식 가격
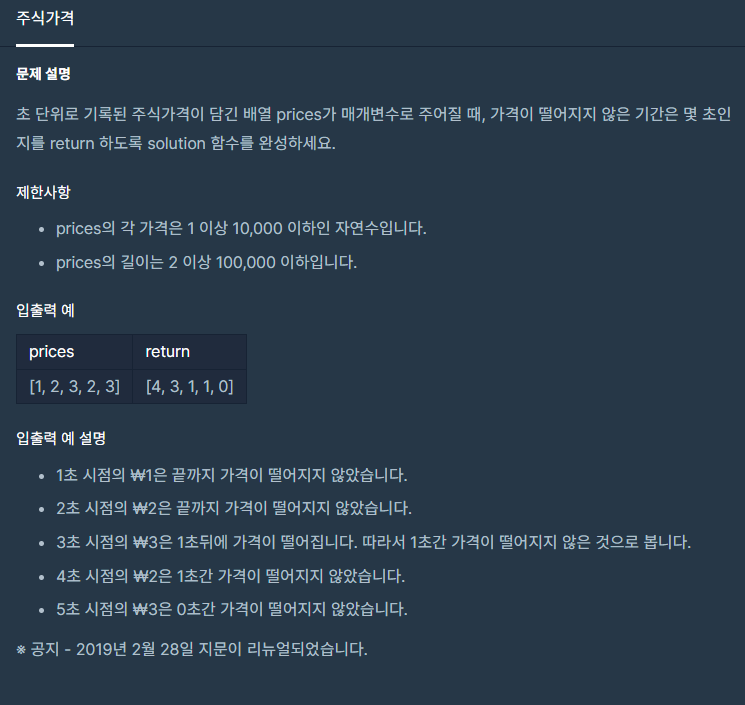
먼저 들어올 수록 값이 늦고 나중에 들어올 수록 값이 낮으므로 스택을 이용하여 값의 차이를 둘 수 있을 것이다.import java.util.Stack;Stack<> stack = new Stack<>();을 이용하여 자바에서 쉽게 스택을 사용할 수 있다.p
20.큰 수 만들기
1.k개의 숫자를 제거했을때 최대값이 되어야 한다.2.숫자들간 순서는 유지되어야 한다.최대값을 유지해야고 이전 값과 비교해야 하므로 스택을 사용현재 값과 이전 최대값을 비교해 이전 스택의 값들이 더 크면 push, 현재 값이 더 크면 스택의 값이 더 클때까지 pop을
21.카펫
노란색 카펫으로부터 갈색 카펫을 구해야하는 문제이다.갈색카펫의 갯수를 비교해야 할 것 같다.노란카펫의 크기를 구하기 위해선 가로와 세로의 길이를 알아야 한다. 가로가 세로보다 항상 같거나 길므로세로를 1씩 증가시켜가며 나눠떨어지면(노란색 갯수가 일치) 갈색카펫과 갯수를
22.H-index
h와 H-index가 의미하는 점이 이해하기 어려운것 같다.h들을 구해서 h의 최댓값(인용된 논문수)인 H-index를 반환하는 문제이다.순서와 상관없이 갯수를 구하는 문제이므로 정렬을 사용하자import java.util.Arrrays;Arrays.sort(citat
23.다리를 지나는 트럭

https://minhamina.tistory.com/241
24.위장

조합의 수를 보는 문제인것 같다. 순서는 중요하지 않고 어떤 종류들을 묶느냐가 중요한 문제인것 같다.같은 카테고리를 묶어야 하므로 해시맵을 사용하여야 한다.(key,value)로 이루어진 쌍을 각각 (String ,Integer)로 (카테고리, 나온수)로 묶자impor
25.조이스틱
오락실에서 마지막에 하던 이니셜 세기는 것과 비슷하다고 생각하면 된다. 아파벳 뿐만아니라 자리도 역순으로 돌 수 있다.위로 올리면 정순, 아래로 내리면 역순으로 알파벳을 바꿀 수 있다. 최소한으로 움직여야 하므로 정순과 역순중 빠른 걸 고르면 될것이다.answer +=
26.튜플

처음엔 이해하기 어려워서 부분집합인줄 알았다. 하지만 자세히 읽어보니 부분집합보단 순서가 존재하고 원소가 중복 될수 있다. 즉 (1,2,3) =/= (2,3,1)이고 튜플{{2},{1,2,3},{3,2}}의 집합은 {2,3,1}이다.주어진 자료형과 연산과정이 복잡하여
27.[카카오 인턴] 수식 최대화

연산자와 피연산자로 이루어진 문자열을 구분하여 연산을 수행하는 문제이다. 순열을 이용하여 연산자 우선순위를 구하고 해당 우선순위에 대한 결과 값을 비교한다.1.문자열에서 연산자와 피연산자를 구분2.순열로 만들어질수 있는 연산자우선순위 경우들 계산3.연산자 우선순위로 연
28.[1차] 뉴스 클러스터링

두개의 문자열로부터 원소들을 추출하고 교집합과 합집합을 구한후 자카드수를 구하는 문제이다.일반적인 합집합, 교집합과는 다르게 양쪽에 여러개가 존재할 시 합집합은 많은 쪽을, 교집합은 적은 쪽 수를 맞춘다.처음에 원소들을 중복해 나열하여 교집합과 합집합 구할때 여러번 다
29.괄호 변환
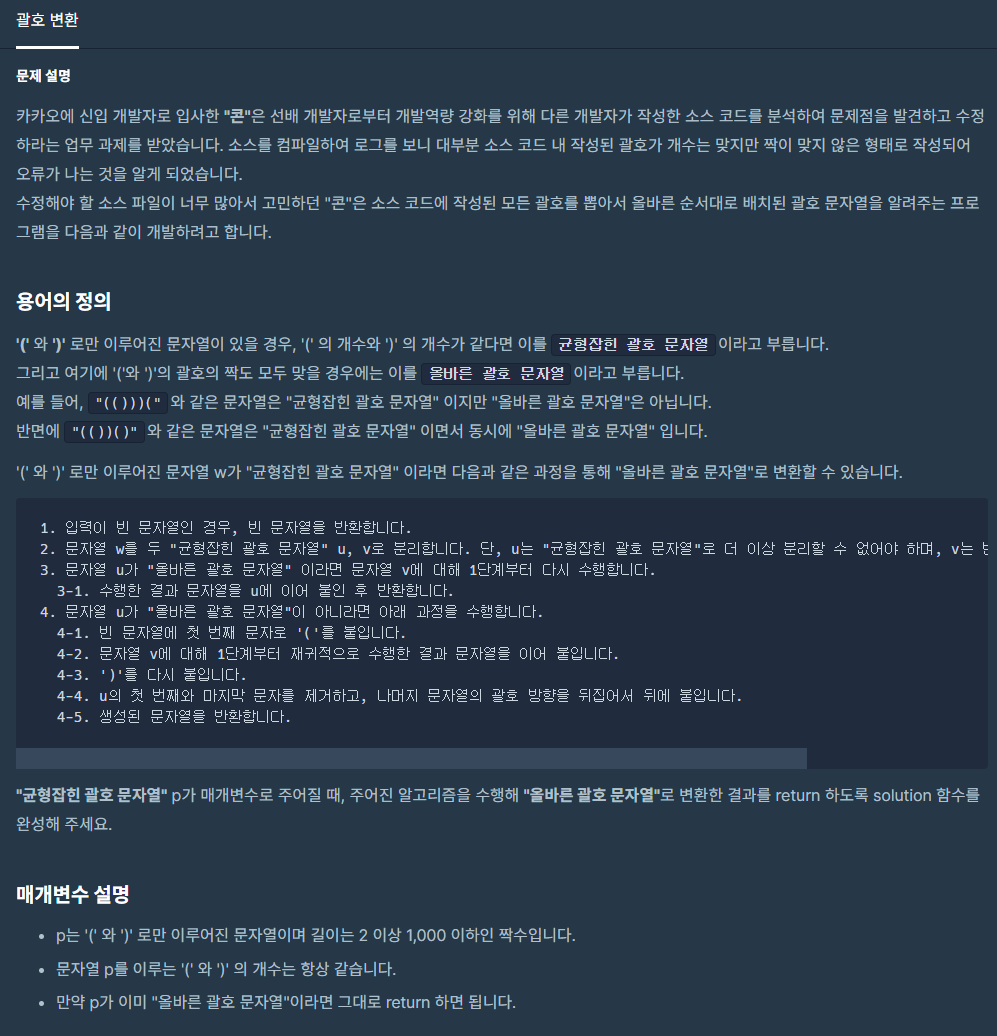
특이하게도 알고리즘을 문제에서 제시하였습니다. 어려워서라기 보단 모호해질수 있어서 그런것 같네요.균형잡힌 괄호 문자열과 올바른 괄호 문자열이 무엇을 뜻하는지와 문제에서 설명하는 변환방식이 어떤 건지 정확히 짚고 가야 다른 길로 빠지는걸 방지할 수 있을것 같습니다.임의로
30.메뉴 리뉴얼

배열이 두개가 주어지는데 orders와 course가 각각 무엇을 의미하는지와 어떻게 메뉴를 조합하는지를 잘 정해야 합니다.이전에 뉴스클러스터링 문제와 많이 혼돈이 되었었습니다. (https://velog.io/@ds02168/1%EC%B0%A8-%EB%89
31.짝지어 제거하기
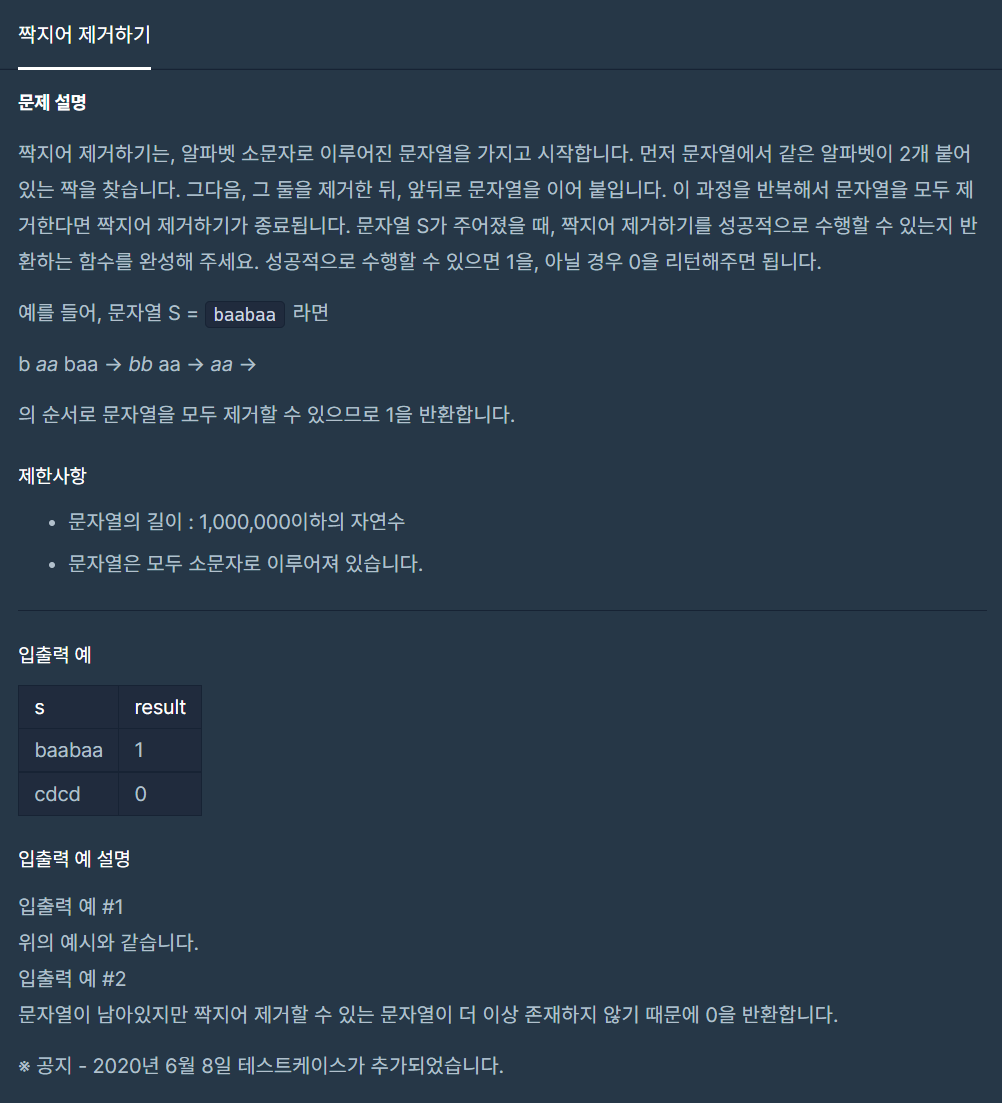
2개의 동일한 문자가 있으면 제거합니다. 만약 제거후 또 2개의 동일한 문자가 존재한다면 존재하지 않을때까지 제거합니다. 만약 가능한 2개의 동일한 문자들을 모두 제거하였을때 남은 문자가 없다면 1, 있으면 0을 리턴합니다.2개의 문자를 제거한다가 핵심이었습니다. 3개
32.멀쩡한 사각형
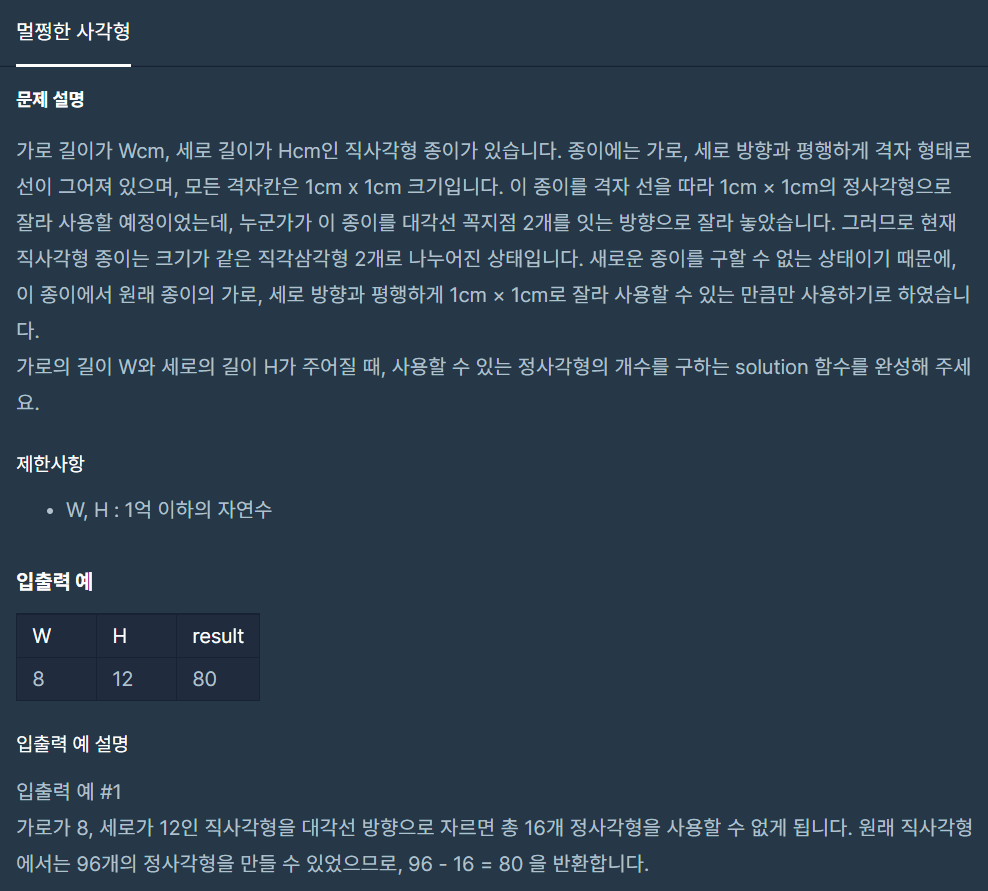
수학적으로 접근해야하는 문제입니다. 사각형과 대각선을 이용하여 구해보겠습니다. 다른방법도 있을 듯 합니다.x값,y값,기울기 이용자바 자료형의 한계대각선을 제외한 사각형기울기 = x / y으로 기울기는 같은 도형내에서 어느 x든 y든 항상 상수입니다. x축이 +1씩 할때
33.오픈채팅방

나갔다가 다시 들어오거나, 닉네임을 수정하거나 해서 닉네임이 항상 바뀔수 있고 결과는 바뀐 닉네임만 처음부터 마지막 까지 보여줘야 하는 문제입니다.변하지 않는 유저ID가 주어집니다. 유저 ID로 자유롭게 바뀔 수 있는 닉네임을 해시맵을 이용하여 찾는다면 항상 찾을 수
34.문자열 압축
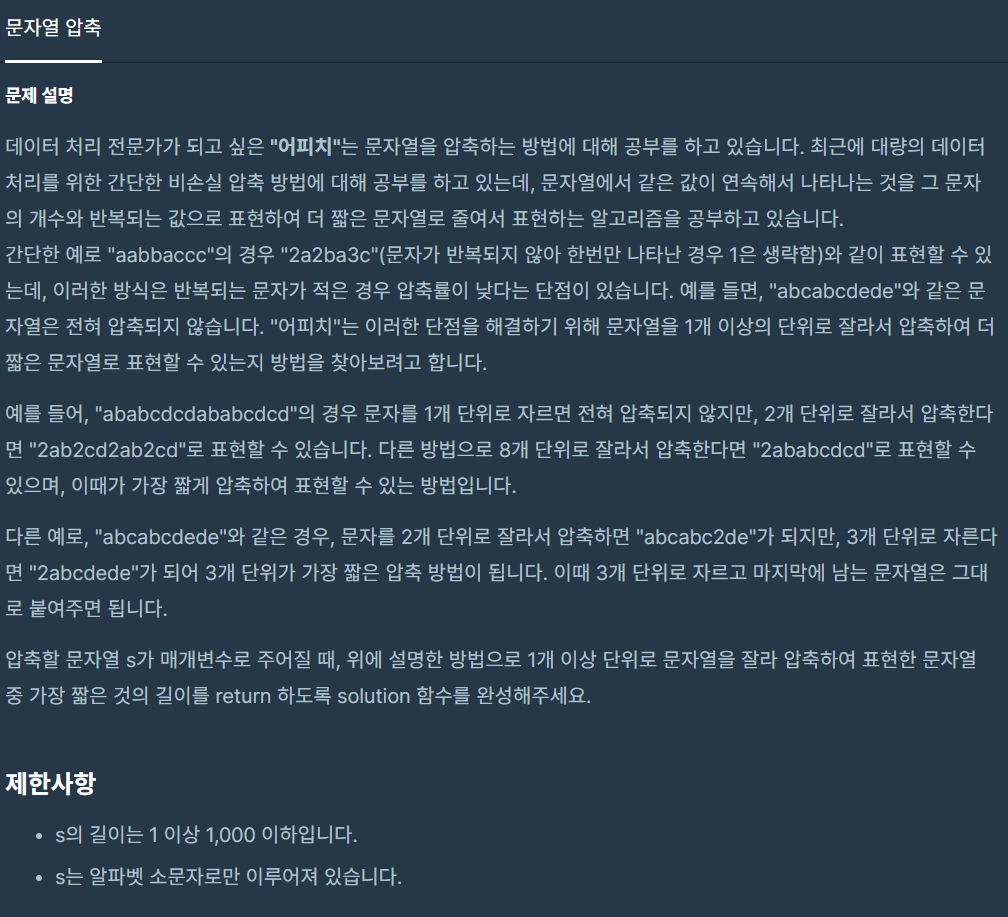
문자열 묶음으로 압축하여 가장잘 압축될 수 있는 문자열의 수를 구해 길이를 구하는 문제입니다.압축을 위해 실제로 문자열을 수정하고 했지만 이 문제는 문자열이 아닌문자열의 길이를 제출하는 문제입니다. 형식에 얽매여서 풀이가 많이 힘들었었습니다.시작위치와 갯수로 문자열 묶
35.프린터
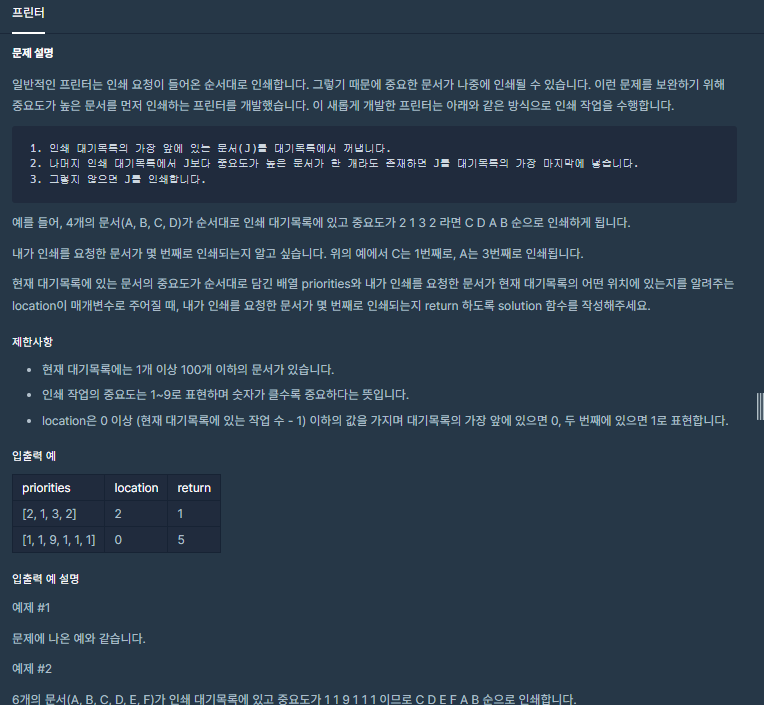
몇번째로 인쇄되는지 순서가 중요하고 기본적으로 같은 우선순위일땐 앞의 문서가 먼저 출력되므로 큐를 이용해야 합니다.프린트 하고자 하는 문서의 위치와 큐를 초기화 합니다.맨앞에 있는 문서가 가장큰 우선순위를 가지면 인쇄합니다.맨앞의 문서가 인쇄가 되었는지, 맨뒤로 이동했
36.전화번호 목록

현재 전화번호의 부분집합(전체가능)이 다른 전화번호와 일치하는지 점검하는 문제입니다.문제에서 의미하는 접두어가 무엇인지 파악하는것이 정답과 상당히 깊은 관련이 있는 문제입니다. 뒷부분은 신경쓰지 않고 앞부분만 일치여부를 확인하므로 앞에서 부터 차례로 비교합니다.전화번호