
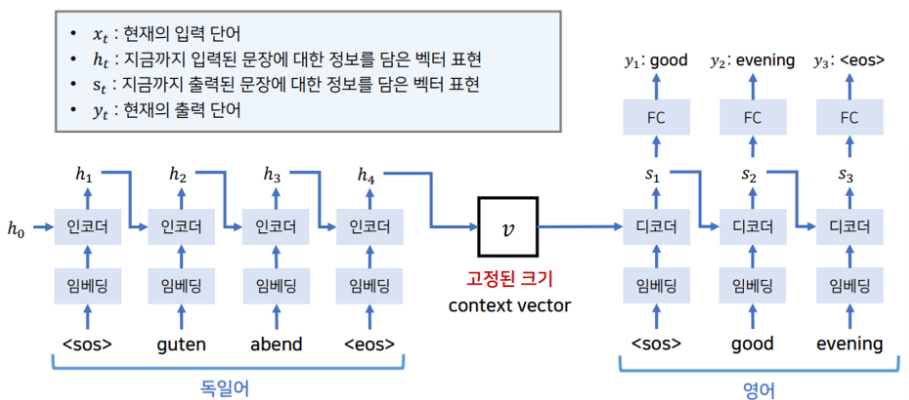
입력 문장이 들어왔을 때 Encoder에서 만들어 낸 하나의 고정된 크기 context vector를 Decoder에서 받아 문장을 번역하는 결과를 낸다.
등장 배경
- 전통적인 RNN에서는 입력과 출력의 길이가 같다고 가정하기 때문에 현실적인 기계번역에서 사용하기 어려움
- 한국어와 영어의 문장 구조가 다르기 때문에 입력이 들어갈 때마다 정확한 예측은 거의 어려움
모델
기초
- T : 시퀀스에 포함되어 있는 요소의 개수로 단어의 개수
- hidden state : 이전까지의 데이터 정보
- <sos> : start of sequence
- <eos> : end of sequence
STEP 1
임베딩 레이어를 거쳐 차원을 줄인다.
STEP 2
hidden state는 다음 인코더에 들어가며 갱신된다.
- Seq2Seq에서 LSTM을 인코더로 사용
- 기본적인 RNN보다 긴 dependence를 처리하기 적합
- 인코더의 마지막 hidden state를 context vector로 사용
- 마지막 hidden state가 문장에 대한 모든 정보를 가진다.
STEP 3
디코더에서 s(t) 지금까지 출력된 문장에 대한 정보를 담은 벡터 표현이 hidden state이다.
STEP 4
하나의 linear한 레이어 fully connected를 거쳐 y(t) 현재의 출력 단어가 나오게 된다.
- 이전까지의 hidden state 정보와 현재 단어까지를 linear layer를 통해서 아웃풋이 나옴
*인코더와 디코더는 서로 다른 파라미터(가중치)를 가진다.
- 인풋 시퀀스는 t개 만큼 단어 존재
- 입력과 출력 문장이 다를 때는 사용하기 어려움
👉 인코더 파트의 RNN과 디코더 파트의 RNN을 다르게 사용할 수 있음
장점
- 입력과 출력의 길이가 다를 수 있음
단점
- 긴 문장이 test data로 들어오게 되면 문장에 대한 정보를 모두 담을 수 없음
- 어떤 시스템이나 프로세스에서 데이터의 흐름이 지연되거나 제한되는 시점이 bottleneck으로 작용
논문 리뷰
Task
영어를 불어로 번역
- WMT’14 dataset 사용
- BLUE score 34.8
- SMT - BLUE score 33.3
- LSTM + SMT - BLUE score 36.5
핵심
LSTM을 통해서 계속 업데이트 된 hidden state를 context vector로 함
실제 구현
- 인코더와 디코더에 사용한 LSTM은 파라미터가 다르다.
- LSTM을 총 4번 multilayer로 쌓아 capacity가 높아졌다.
- 입력 문장의 단어의 순서를 바꿨다.
ex) abc -> cba
상대적으로 첫번째 등장하는 단어끼리 높은 연관성을 가질 수 있도록 매핑시킬 수 있기 때문에 실제 모델의 학습 난이도를 낮춘다.
- 근거
- 일반적인 언어 체계에서 앞쪽에 위치한 단어끼리 연관성이 높다.
- 순서를 뒤바꿈으로서 context vector에 문맥이 더 잘 담긴다.
- 학습 효율이 높아서 정확도가 높아진다.
- beam search
- 모델이 생성한 여러 후보 중에서 가장 가능성이 높은 시퀀스를 선택하는 탐색 알고리즘
- 디코더
- Word Embedding
- 16만 개 단어로 16만이었던 차원을 1000 차원으로 축소
- LSTM의 파라미터를 uniform distribution으로 초기화
- 모멘텀 없이 스토캐스틱 경사하강법을 사용하여 learning rate를 줄여나갔다.
- 배치 사이즈로 128을 사용
- 학습 과정에서 모델을 foward할 때 사용하는 문장의 개수가 128개
- 같은 미니 배치 안에 포함되어 있는 각각의 문장들이 최대한 비슷한 길이가 될 수 있도록 조정해서 패딩을 최소화
- 만약 랜덤으로 문장을 생성하게 된다면 하나의 긴 문장이 발생했을 때 다른 문장들의 길이를 맞추어 주는 패딩이 낭비이기 때문
- 결과적으로 학습 속도를 높임
- LSTM의 hidden state를 PCA projection 시켰을 때 (2차원) 비슷한 시퀀스끼리 잘 clustering 됨
- teachear forcing
- 딥러닝 기법과 기존에 사용하였던 통계적 기법을 같이 사용, 앙상블 기법
느낀 점
모델 성능 개선에 대해 생각해볼 수 있었다. 트랜스포머 논문을 보는 데 기초가 되었다.
