1. 변동성의 군집 현상
IID는 실제로 성립하지 않는 가정이다. 다음은 FinanceDataReader을 이용해 2019년 1월 1일부터 2023년 1월 1일까지의 코스피200의 일별 수익률과 환율의 일별 변화율을 그래프로 도식화 해봤다.
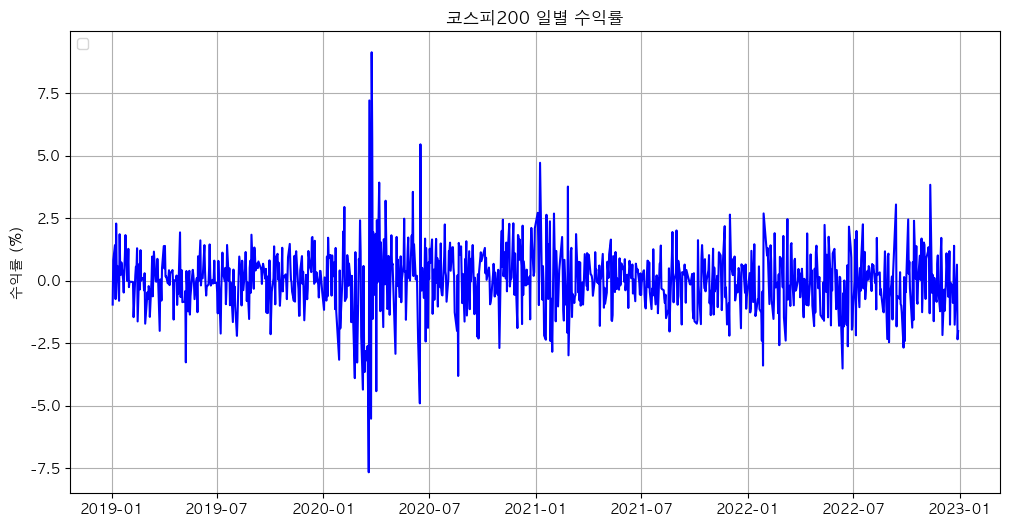
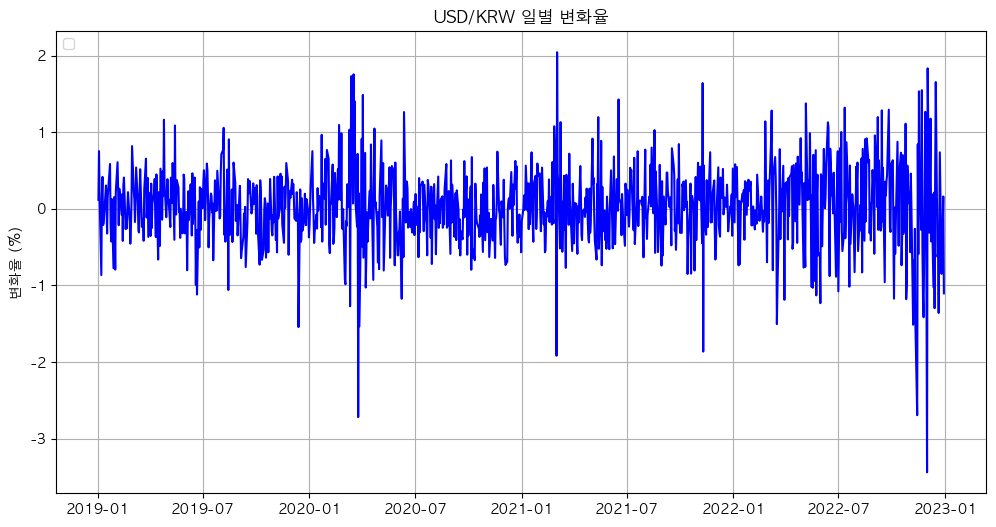
다음 그림을 보면 비슷한 시기에 수익률과 변화율이 크게 변동하는 것을 확인할 수 있다. 그리고 k-th order autocorrelation coefficient는 다음과 같다.
위를 바탕으로 KOSPI200의 일별 수익률의 자기상관계수 그래프를 확인해보자. X축은 래그(lag)시킨 일수를 의미한다.
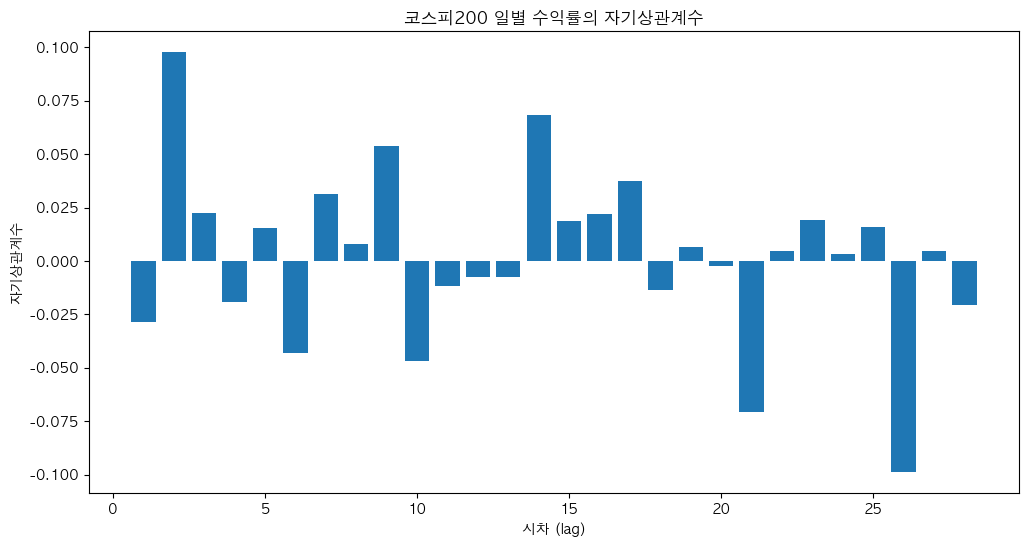 가 0.100에 가깝게 나오긴 했지만, 대부분은 그리 크지 않으며 일부는 음의 자기상관계수가 나왔다. 거래비용을 감안하면 그다지 유의적이라고 보기 어렵다.
가 0.100에 가깝게 나오긴 했지만, 대부분은 그리 크지 않으며 일부는 음의 자기상관계수가 나왔다. 거래비용을 감안하면 그다지 유의적이라고 보기 어렵다.
반면에 KOSPI200의 일별 수익률을 제곱한 수치를 그래프로 그리면 아래와 같다. 기대수익률을 0으로 가정하면 수익률 제곱의 기대치는 분산과 같다.
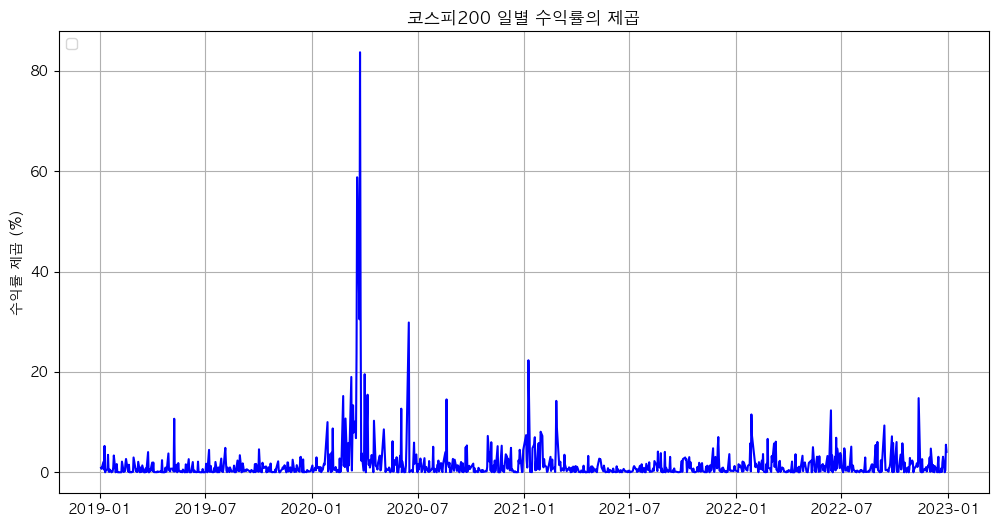
그리고 이를 바탕으로 KOSPI200의 일별 수익률의 제곱의 자기상관계수 그래프를 확인해보자.
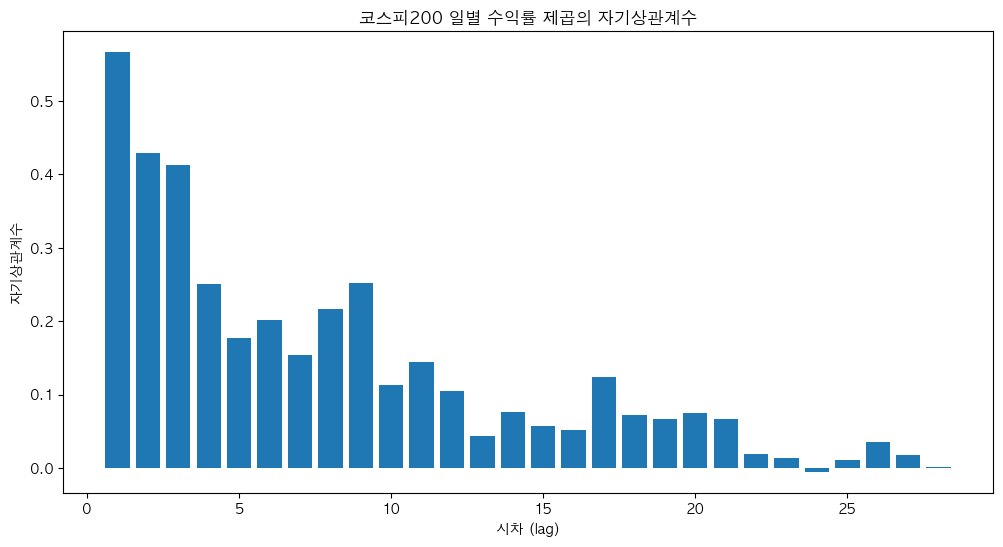 이전과 달리 0.100을 넘는 가 다수 존재하며 모두 양수다. 특히 lag=10 전까지는 수치가 매우 크며, 보다 더 유의적인 수치라고 볼 수 있다.
이전과 달리 0.100을 넘는 가 다수 존재하며 모두 양수다. 특히 lag=10 전까지는 수치가 매우 크며, 보다 더 유의적인 수치라고 볼 수 있다.
변동성이 한번 커지거나 작아지면 그 상태로 어느 정도 지속되는데, 이를 변동성의 군집(volatility clustering)이라고 한다. 이런 패턴을 이용하면 변동성을 보다 더 예측할 수 있음을 의미한다.
2. 변동성과 상관계수 추정 방법
변동성 추정 방법은 아래와 같이 다수 있지만, 이동평균법에 대해 알아보도록 하자.
- 옵션 가격을 이용한 내재변동성
- 시뮬레이션
- 표준편차
- GARCH 모형
- 단순 이동평균모형
- 지수 가중 이동평균모형(EWMA method)
(1) 단순 이동평균법(Simple moving average model)
이동기간을 일, 를 변동성 추정치로, 를 수익률의 제곱으로 하면 단순 이동평균법에 의한 변동성 추정치는 다음과 같다.
하지만 이는 이동기간에 포함된 모든 과거 수익률이 동일한 가중치를 갖는다는 단점이 있다. 앞서 봤듯이, 변동성의 군집현상 때문에 최근의 데이터가 더 중요하다고 볼 수 있다. 그래서 엔글(Engle)이 이를 보안하기 위해모형을 제안했는데, 다음과 같다.
는 일 전 변동성(수익률 제곱)에 주어진 가중치이고,는 장기평균 변동성, 은 그에 대한 가중치이다. 모든 가중치의 합은 1이다. 즉, 오래된 데이터일수록 작은 가중치를 갖는다.
(2) 지수 가중 이동평균법(Exponentionally weighted moving average method)
과거의 데이터일수록 그 가중치가 지수적으로 감소하는 방법으로 다음과 같다.
는 소멸 계수(decay factor)로 가 클수록 최근 데이터의 가중치가 작아지고, 반대로 가 작을수록 최근 데이터의 가중치가 커진다. 즉, 는 에 대한 변동성의 민감도라고 볼 수 있다. 또한 위 식을 다시 정리하면 다음과 같다.
가 무한으로 커지면 가 0에 수렴하고, 의 가중치가 각각 이다. 이를 보면 과거로 갈수록 가중치가 지수적으로 작아짐을 알 수 있다.
(3) 최적 선택
리스크메트릭스에서는 일정기간 동안의 Root Mean Squared Error를 최소화하는 를 최적 소멸계수(optimal decay factor)로 선택하고 있다.
는 추정한 를 이용한 EMWA 방법으로 추정한 일의 분산을 의미한다. 즉, RSME는 추정값과 실체값의 Error를 최소화하는 를 추정하는 것이다.
마치며
주가 지수의 일별 수익률 그래프를 검색해봤는데 보기 좋은 그래프를 못 찾았다. 그런데 생각해보니, 나 이거 만들 줄 아는구나 싶어서 파이썬으로 그래프 그려봤다. 언젠간 다 쓸일이 있다...흐흐
https://colab.research.google.com/drive/1v5esIAoqEQu1HNKxC0DS_ebSlea0z-Vq#scrollTo=KZcmLPmUg__u
