1. 데이터 개요
- 데이터셋: HR-Employee-Attrition.csv
- 배경 설명
- 직원의 이직(Attrition)은 HR 담당자가 처리해야 하는 복잡한 과제 중 하나이다.
- 직원별 정보가 담긴 데이터를 분석하여, HR 부서가 조직을 원활하고 수익성 있게 운영하기 위한 적절한 인사이트를 전달한다.
2. 데이터 불러오기
import pandas as pd
# 데이터 상부 10개 행 확인
hr = pd.read_csv("./data/HR-Employee-Attrition.csv")
hr.head(10)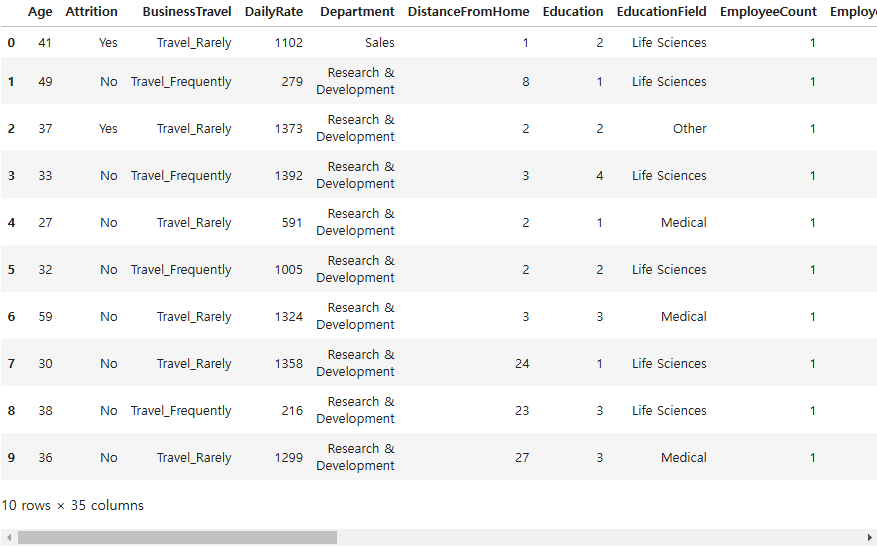
3. 데이터 세부사항 파악
# 데이터 기본정보 확인 (행 수, 컬럼 수, 컬럼명, 컬럼 데이터 타입 등)
hr.info()
# 수치형 데이터 기술통계 정보 확인
hr.describe().round(1).T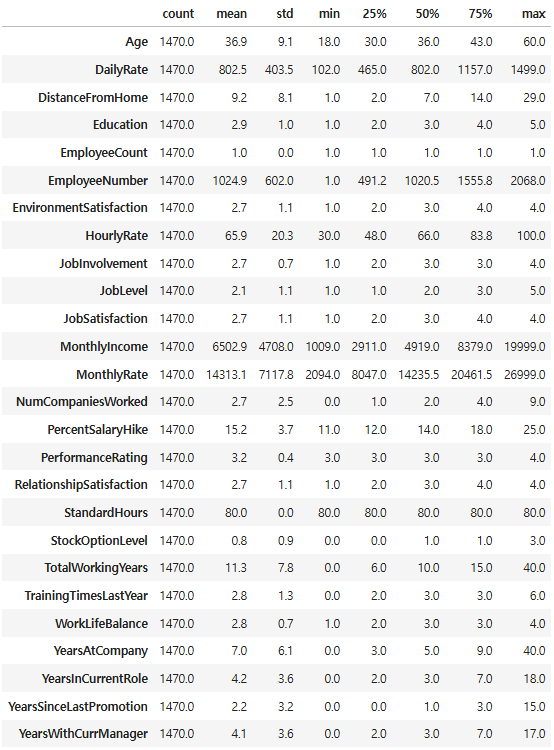
# 중복값 여부 확인 (미존재)
hr.duplicated().sum()# 컬럼별 고유값, null값 여부, 데이터타입 정보 확인 (고유값 수 오름차순 정렬 후 10개 추출)
# 'Over18', 'StandardHours', 'EmployeeCount' 변수는 단일 수치값으로 구성됨
pd.DataFrame(
{
"unique": hr.nunique(),
"null": hr.isna().sum(),
"type": hr.dtypes
}
).sort_values(by="unique", ascending=True).head(10)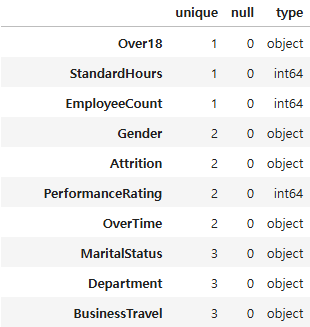
# 'Over18', 'StandardHours', 'EmployeeCount' 변수 삭제처리
hr.drop(["StandardHours", "Over18", "EmployeeCount"], axis=1, inplace=True)4. 데이터 변형
# 'Department' 및 'JobRole' 별 케이스 수 확인
hr.groupby(["Department", "JobRole"]).\
size().\
sort_values(ascending=False).\
reset_index(name="Emp. Count")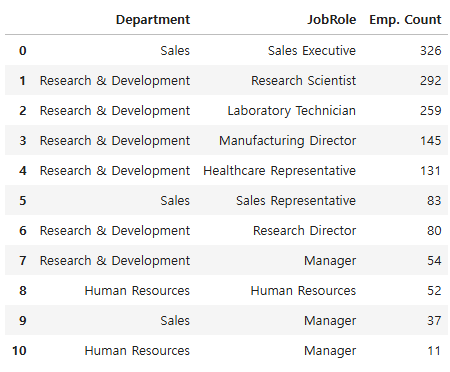
# 'Department' 및 'JobRole' 별 'Age' 기술통계 확인
hr.groupby(["Department", "JobRole"])["Age"].\
agg(["count", "min", "median", "max"])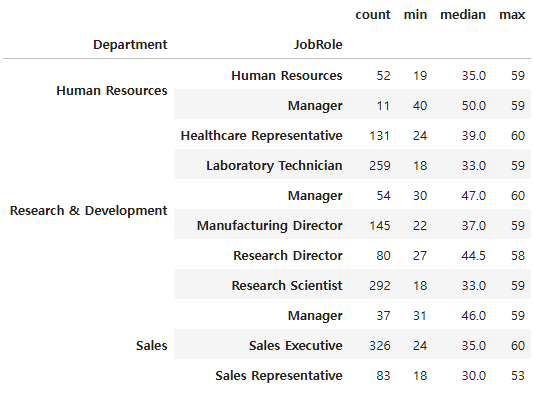
# 'Deparment', 'Attrition', 'JobLevel' 별 이직자 수 확인
# 연구개발 부서의 1년차 주니어의 이직이 상당함을 알 수 있음
pd.pivot_table(
data=hr_part,
values="Age",
index=["Department", "Attrition"],
columns="JobLevel",
aggfunc="count",
fill_value=0 # treatment for NaN
)
5. 상관관계 확인
# 상관행렬 히트맵 제작
import matplotlib.pyplot as plt
import seaborn as sns
hr_corr = hr.corr(numeric_only=True)
plt.figure(figsize=(15,15))
sns.heatmap(hr_corr, annot=True, fmt=".1f", vmin=-1, vmax=1, cmap="RdBu_r")
plt.show()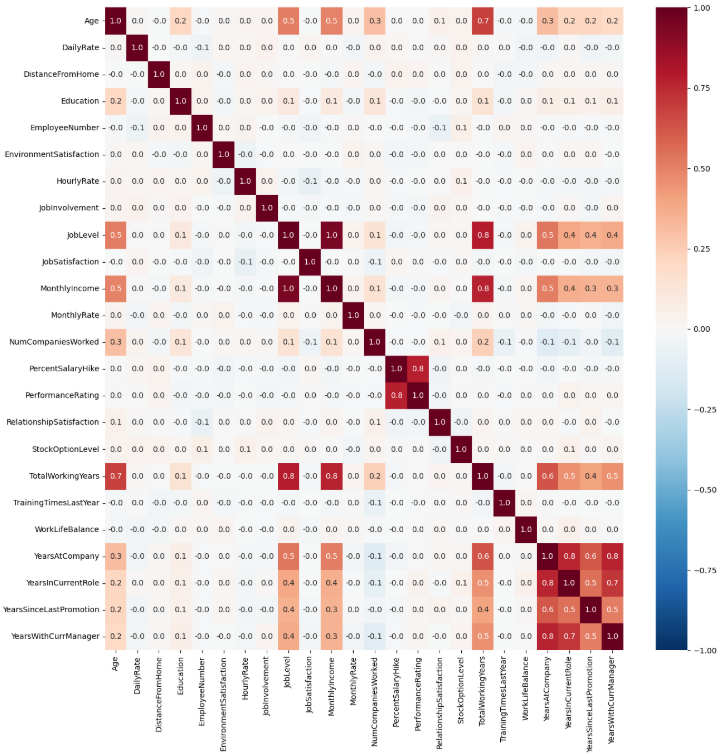
# 컬럼별 상관계수 절대합이 가장 큰 8개의 변수만 추출하여 시각화
colnames_highcorr = hr_corr.apply(abs).sum(axis=1).sort_values(ascending=False)[:8].index.tolist()
hr_corr_highcorr = hr[colnames_highcorr].corr()
plt.figure(figsize=(5,3))
sns.heatmap(hr_corr_highcorr, annot=True, fmt=".1f", vmin=-1, vmax=1, cmap="RdBu_r")
plt.show()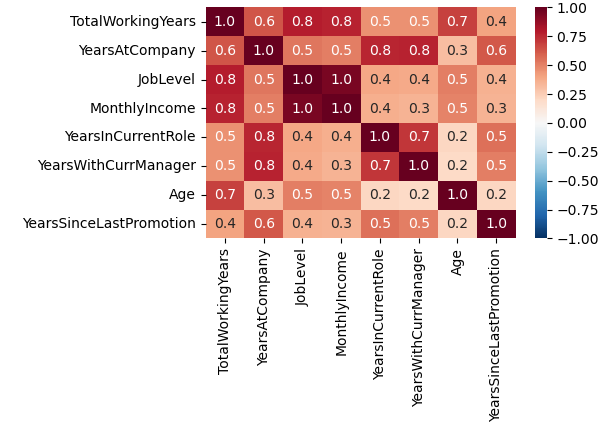
6. 시각화
# 부서별 근속연수와 연간수입 간 차이
sns.set(font_scale=0.7)
fc = sns.FacetGrid(data=hr, row="Department", height=3, aspect=2)
fc.map_dataframe(sns.barplot, x="TotalWorkingYears", y="MonthlyIncome")
fc.fig.subplots_adjust(hspace=.2)
plt.show()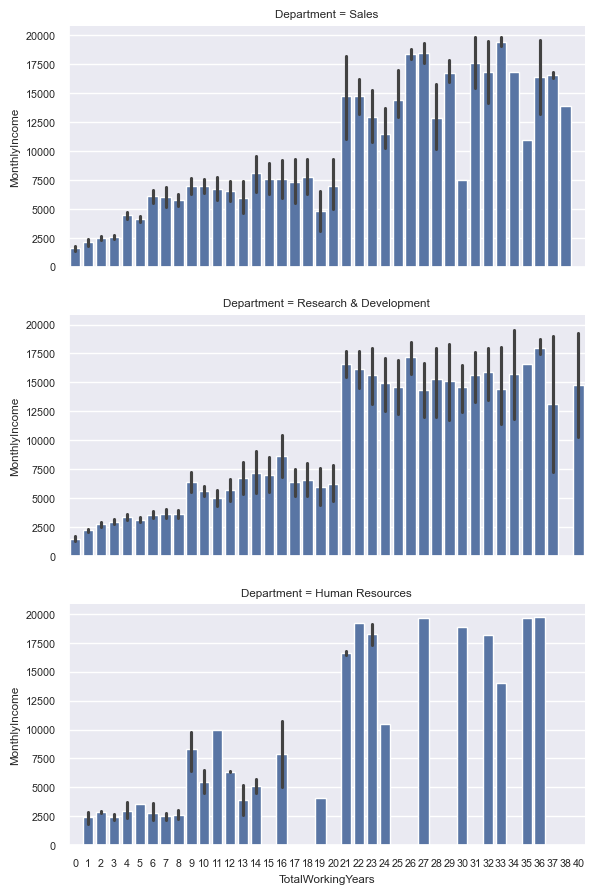
# 부서 및 성별에 따른 근속연수와 연간수입 간 차이
sns.set(font_scale=0.7)
fc = sns.FacetGrid(data=hr,
row="Department",
col="Gender",
hue="Attrition",
aspect=1.3,
hue_order=["No", "Yes"],
palette={"Yes": "red", "No": "grey"})
fc.map_dataframe(sns.regplot, x="Age", y="MonthlyIncome", fit_reg=False)
fc.add_legend()
plt.show()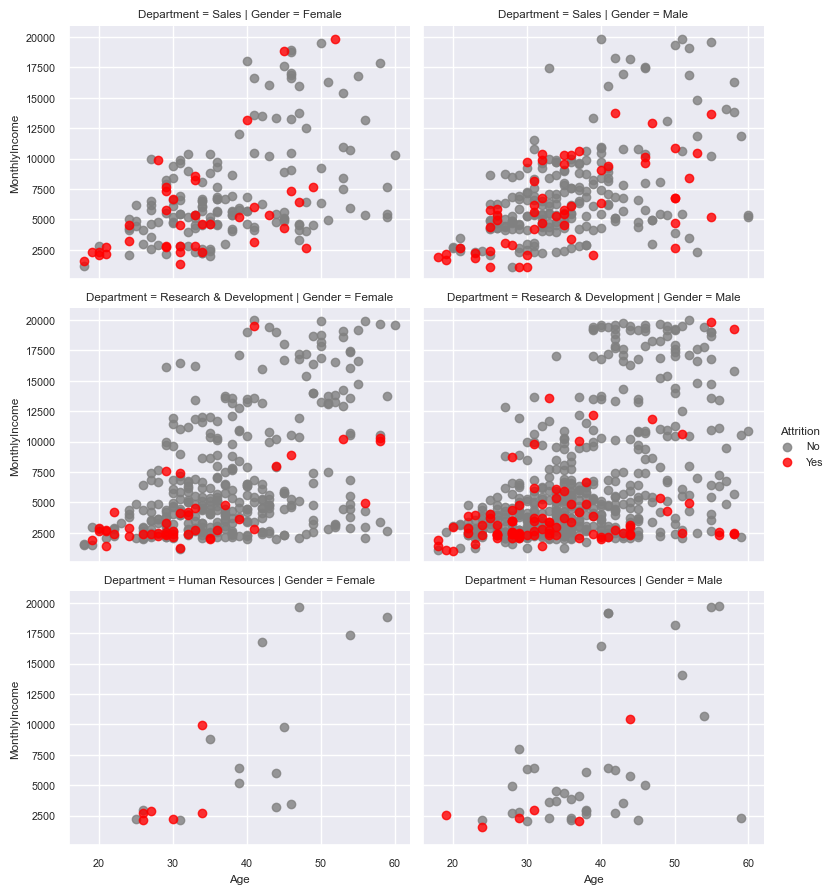
# 수치형 변수의 히스토그램
num_col_list = hr.select_dtypes("int").columns.tolist()
plt.figure(figsize=(10, 10))
for idx, col_name in enumerate(num_col_list):
ax = plt.subplot(6, 4, idx+1)
sns.histplot(data=hr, x=col_name, hue="Gender", ax=ax, alpha=1)
ax.set_title(col_name)
ax.set_xlabel(None)
ax.set_ylabel(None)
plt.tight_layout()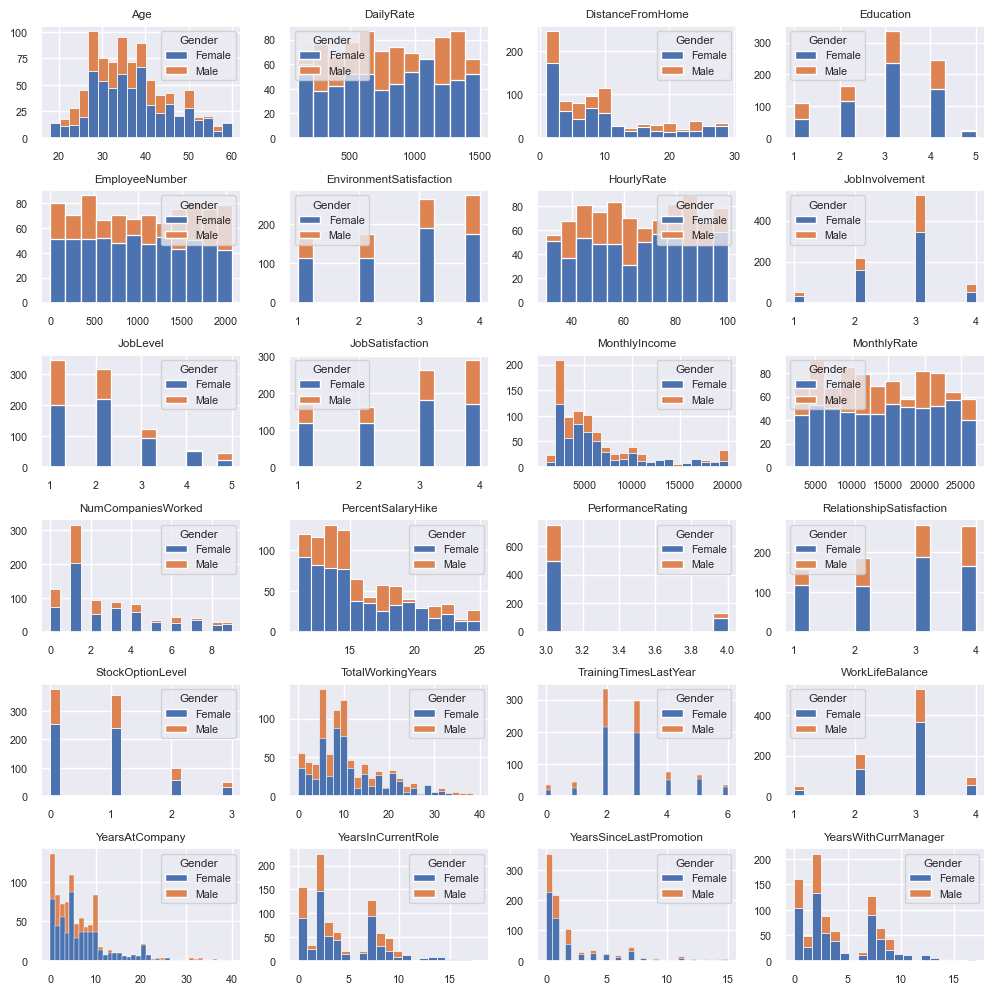
# 나이와 해당회사 근무연수 간 조인트 그래프
g = sns.jointplot(data=hr,
x="Age",
y="YearsAtCompany",
kind="scatter",
height=4,
color="orangered",
marker="+",
marginal_ticks=True,
marginal_kws=dict(bins=20, color="silver"))
g.plot_joint(sns.kdeplot, color="dimgray", alpha=.5)
g.plot_marginals(sns.rugplot, color="gold", height=-0.2, clip_on=False)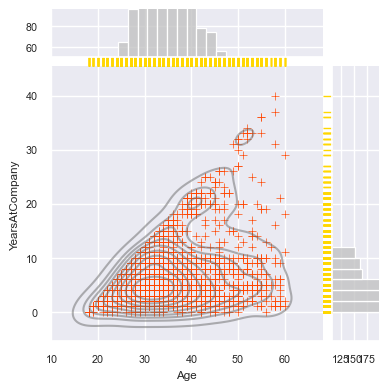
*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소