1. SELECT
- 데이터베이스 내 테이블의 내용을 조회하고자 한다면 SELECT 명령어를 사용함
# 쿼리 구조
SELECT [Columns]
FROM [Source Table]
WHERE [Condition];# Age, Attrition 컬럼 조회
SELECT Age, Attrition
FROM HR_EMPLOYEE_ATTRITION;
- 단순히 개수만을 조회하고자 한다면 컬럼 명시 부분에 COUNT()를 사용함
# Age 컬럼의 개수 조회
SELECT COUNT(Age)
FROM HR_EMPLOYEE_ATTRITION;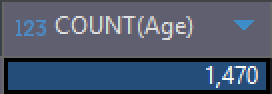
# Age 컬럼의 unique한 값의 개수 조회
SELECT COUNT(DISTINCT Age)
FROM HR_EMPLOYEE_ATTRITION;
2. GROUP BY
- 컬럼을 특정 그룹으로 묶어 집계를 시행하고자 할 때에는 GROUP BY 명령어를 사용함
# 부서, 역할, 계급을 그룹으로 묶어 이직을 하지 않은 직원의 수 조회
SELECT Department,
JobRole,
JobLevel,
count(*) AS Cnt
FROM HR.hr_employee_attrition
WHERE Attrition = 'No'
GROUP BY Department, JobROle, JobLevel;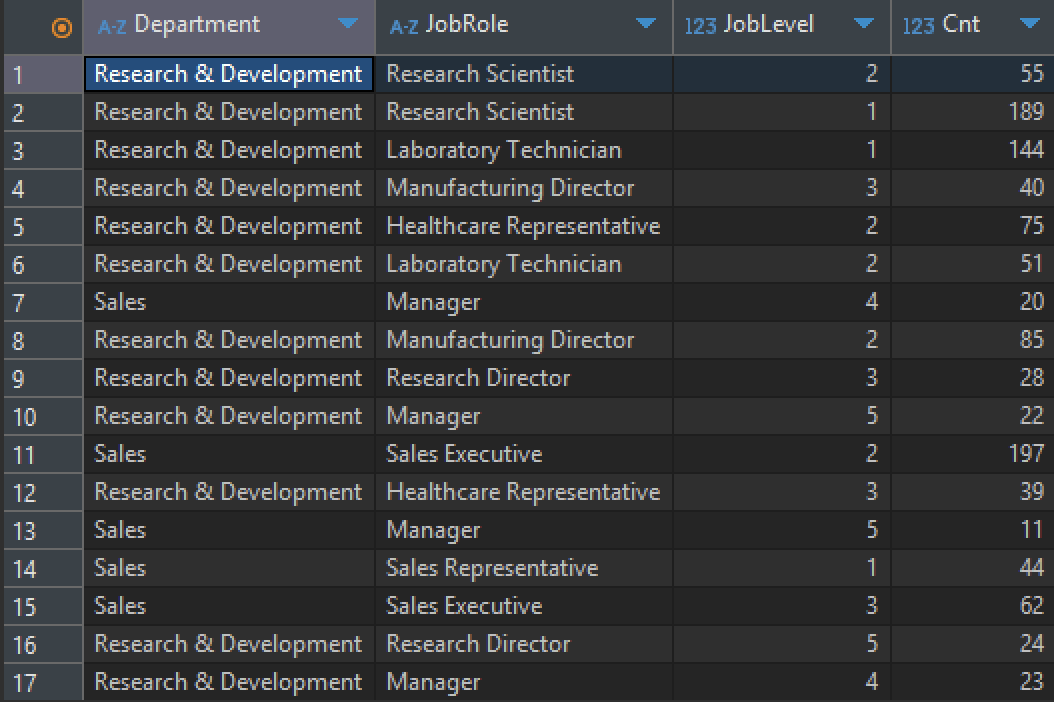
-
사용가능한 주요 집계 함수는 다음과 같음
함수 기능 COUNT() Row 개수 카운트 SUM() 합계 AVG() 평균 MIN() 최소값 MAX() 최대값 -
정렬을 희망하는 경우, 정렬 기준이 되는 컬럼의 순서대로 컬럼명을 ORDER BY 뒤에 기입하여야 함 (컬럼명 뒤에 DESC 명시 시, 해당 컬럼은 내림차순으로 정렬 실시)
# 부서, 역할, 계급을 그룹으로 묶어 이직을 하지 않은 직원의 수 조회
# 단, 부서, 역할, 계급 순으로 오름차순 정렬 실시
SELECT Department,
JobRole,
JobLevel,
COUNT(*) AS CNT
FROM HR.hr_employee_attrition
WHERE Attrition = 'No'
GROUP BY Department, JobRole, JobLevel
ORDER BY Department, JobRole, JobLevel;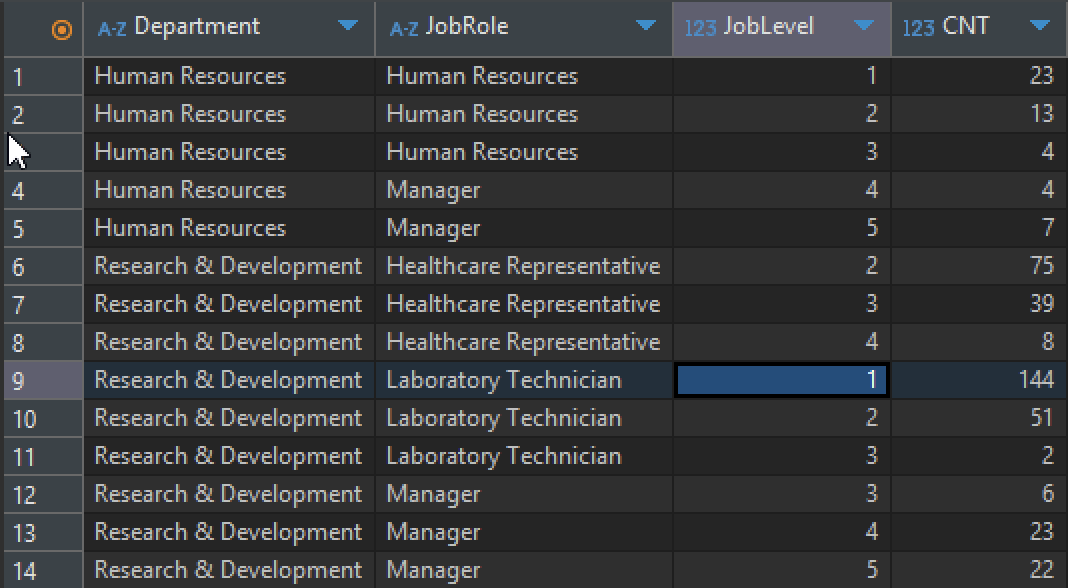
3. 비교 연산자
-
SQL에서 사용하는 기본적인 비교 연산자는 다음과 같음
연산자 기능 > ~보다 크다 < ~보다 작다 >= ~보다 크거나 같다 <= ~보다 작거나 같다 = 같다 <>, != 같지 않다 -
연산의 결과가 참이면 1, 거짓이면 0이 반환됨
4. 논리 연산자
-
SQL에서 사용하는 기본적인 논리 연산자는 다음과 같음
연산자 기능 A AND B A와 B 모두 만족 시 TRUE A OR B A 또는 B 만족 시 TRUE NOT A A 미만족 시 TRUE IN (A, B, C) A, B, C 내 존재하면 TRUE BETWEEN A AND B A와 B 범위 내 존재하면 TRUE LIKE A A라는 규칙에 부합하면 TRUE -
연산의 결과가 참이면 1, 거짓이면 0이 반환됨
5. 데이터타입
-
데이터베이스가 지원하는 주요 데이터타입은 다음과 같음
타입 의미 바이트 비고 INT 정수 4 FLOAT 실수 4 CHAR(n) 고정길이 문자열 n n 초과 시 절삭, n 미만 시 공백 채움 BINARY(n) 고정길이 문자열 n 대소문자 구분 VARCHAR(n) 가변길이 문자열 n n 초과 시 절삭, n 미만 시 해당 크기만큼 저장 VARBINARY(n) 가변길이 문자열 n 대소문자 구분
6. CREATE
- 데이터베이스 내 새로운 테이블을 생성하기 위해서는 CREATE 명령어를 사용함
- 생성할 컬럼명과 컬럼의 데이터 타입을 함께 선언하여야 함
CREATE TABLE HR.hr_cat
(
EmployeeNumber int(11),
Attrition VARBINARY(50),
BusinessTravel VARBINARY(50),
Department VARBINARY(50),
EducationField VARBINARY(50),
Gender VARBINARY(50),
JobRole VARBINARY(50),
MaritalStatus VARBINARY(50),
OverTime VARBINARY(50)
);7. INSERT
- 특정 테이블에 값을 입력하기 위해서는 INSERT 명령어를 사용함
INSERT INTO HR.hr_cat
(
SELECT
EmployeeNumber,
Attrition,
BusinessTravel,
Department,
EducationField,
Gender,
JobRole,
MaritalStatus,
OverTime
FROM
HR.hr_employee_attrition
);- CREATE 시 SELECT를 이용함으로써, CREATE와 INSERT를 동시에 수행할 수도 있음
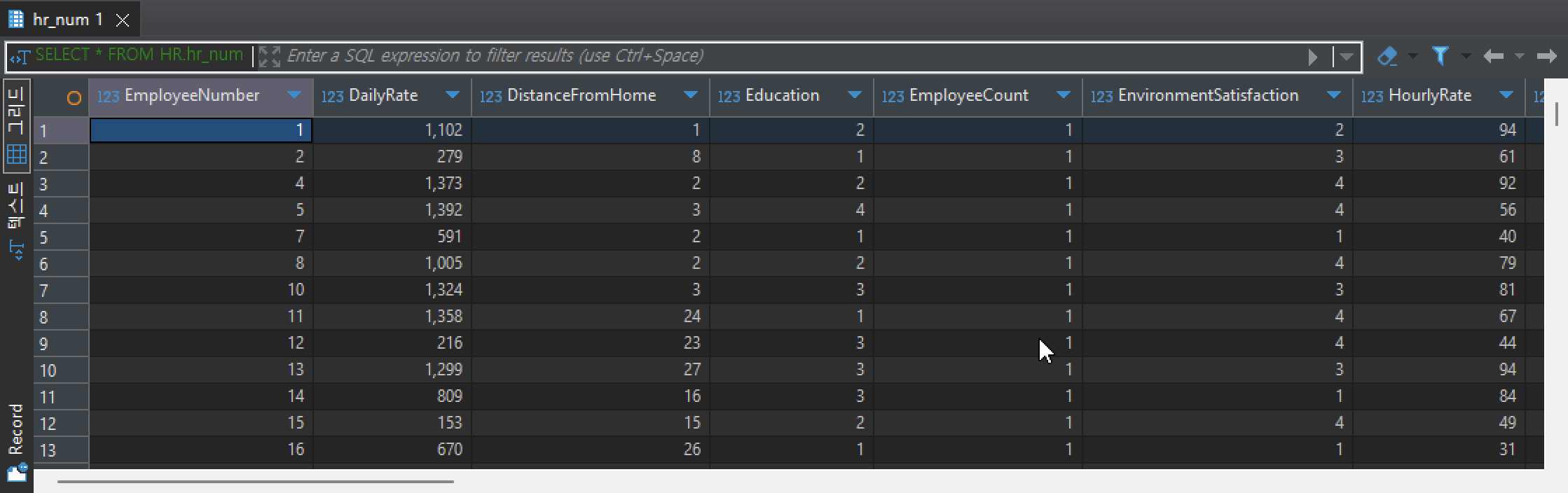
CREATE TABLE HR.hr_num
(
SELECT
EmployeeNumber,
DailyRate,
DistanceFromHome,
Education,
EmployeeCount,
EnvironmentSatisfaction,
HourlyRate,
JobInvolvement,
JobLevel,
JobSatisfaction,
MonthlyIncome,
MonthlyRate,
NumCompaniesWorked,
PercentSalaryHike,
PerformanceRating,
RelationshipSatisfaction,
StandardHours,
StockOptionLevel,
TotalWorkingYears,
TrainingTimesLastYear,
WorkLifeBalance,
YearsAtCompany,
YearsInCurrentRole,
YearsSinceLastPromotion,
YearsWithCurrManager
FROM
HR.hr_employee_attrition
);
*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소