1. 문제 정의
- '이디야 매장은 스타벅스 매장 옆에 개점한다'는 주장이 있어, 직접 데이터를 수집하고 분석하여 검증하고자 함
- 특별히 개방된 데이터는 없으므로 직접 각 브랜드의 홈페이지에서 수집한 다음, 정제하여 활용함
- 가장 많은 매장이 위치한 '서울특별시'를 중심으로 각 브랜드 매장의 위치를 파악하고 전략을 파악하고자 함
2. 데이터 준비
- 라이브러리 로드
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
rc("font", family="AppleGothic") # 맥 환경 한글 세팅
import folium
from folium.plugins import TagFilterButton
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from warnings import filterwarnings
filterwarnings("ignore") # 각종 오류 무시- 스타벅스 매장 정보 크롤링
res = dict()
names = list()
addrs = list()
phones = list()
url = "https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
driver.get(url)
time.sleep(10)
driver.find_element(By.XPATH, '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]/h3/a').click() # 지역 검색
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a').click() # 서울
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="mCSB_2_container"]/ul/li[1]/a').click() # 전체
time.sleep(5)
src = driver.page_source
soup = BeautifulSoup(src, "html.parser")
store_list = soup.find("ul", class_="quickSearchResultBoxSidoGugun").find_all("li", class_="quickResultLstCon")
for store in store_list:
name = store.strong.get_text()
addr = store.find("p", "result_details").\
get_text(strip=True, separator="\n").splitlines()[0]
phone = store.find("p", "result_details").\
get_text(strip=True, separator="\n").splitlines()[1]
if name is None or addr is None or phone is None:
print("Null Data Exists")
break
names.append(name)
addrs.append(addr)
phones.append(phone)
res["매장명"] = names
res["주소"] = addrs
res["연락처"] = phones
starbucks = pd.DataFrame(res)
starbucks["구"] = starbucks["주소"].apply(lambda x: x.split()[1])
starbucks = starbucks[["매장명", "구", "주소"]]
starbucks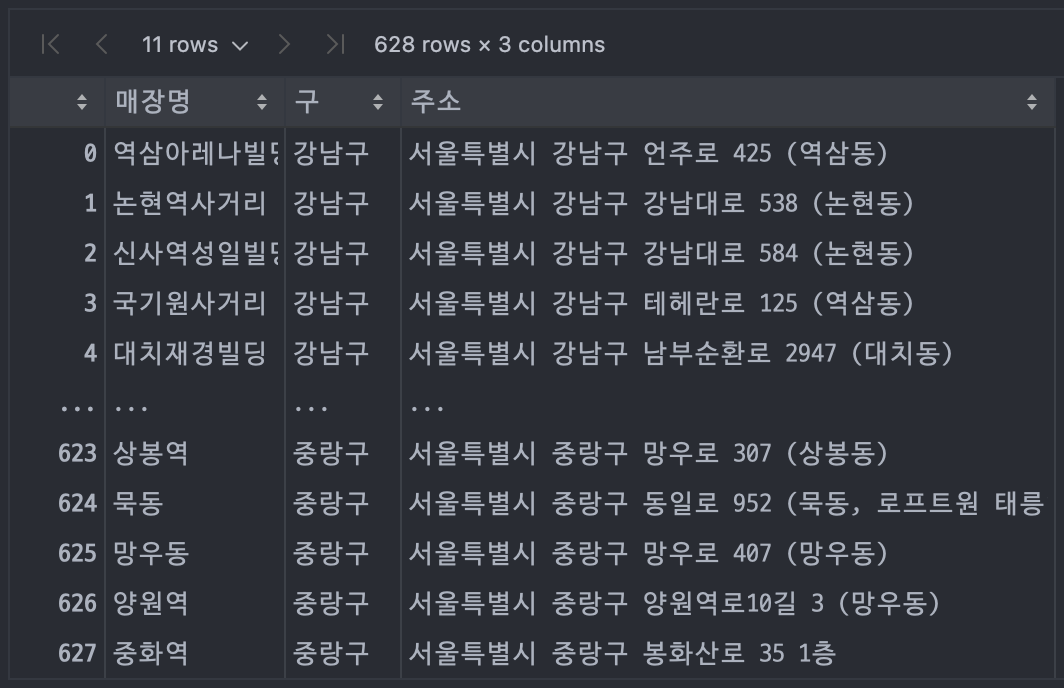
- 이디야 매장 정보 크롤링
# 이디야의 경우 구 별 매장 검색 기능이 존재하지 않아, 키워드 검색 방식 활용
seoul_districts = [
"강남구", "강동구", "강북구", "강서구", "관악구", "광진구",
"구로구", "금천구", "노원구", "도봉구", "동대문구", "동작구",
"마포구", "서대문구", "서초구", "성동구", "성북구", "송파구",
"양천구", "영등포구", "용산구", "은평구", "종로구", "중구", "중랑구"
]
res = dict()
names = list()
addrs = list()
dists = list()
url = "https://www.ediya.com/contents/find_store.html"
driver = webdriver.Chrome(service= Service(ChromeDriverManager().install()))
driver.get(url)
time.sleep(10)
for dist in seoul_districts:
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="contentWrap"]/div[3]/div/div[1]/ul/li[2]/a').click() # 주소
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="keyword"]').click()
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="keyword"]').clear()
if dist == "중구":
dist = "서울 중구" # 서울 외 '중구' 포함 지역 과다로 검색 불가
driver.find_element(By.XPATH, '//*[@id="keyword"]').send_keys(dist)
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="keyword_div"]/form/button').click()
time.sleep(2)
src = driver.page_source
soup = BeautifulSoup(src, "html.parser")
store_list = soup.find("ul", id="placesList").find_all("li", class_="item")
if dist == "서울 중구":
dist = "중구"
for store in store_list:
name = store.dt.get_text()
addr = store.dd.get_text()
names.append(name)
addrs.append(addr)
dists.append(dist)
res["매장명"] = names
res["구"] = dists
res["주소"] = addrs
ediya = pd.DataFrame(res)
# 부산의 강서구도 검색에 포함된 것을 확인하여 제외 필요
ediya["시"] = ediya["주소"].apply(lambda x: x[:2])
ediya = ediya[ediya["시"]=="서울"][["매장명", "구", "주소"]]
ediya.to_csv("./data/ediya.csv", index=False)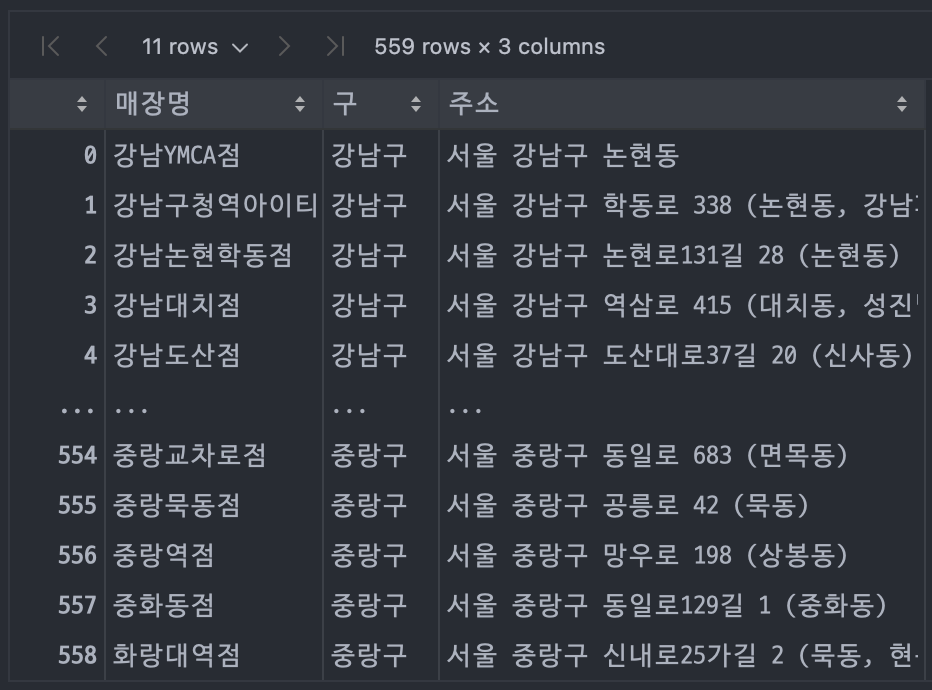
3. 매장별 위도, 경도 추출
- Kakao Developers API를 이용하여 위도 및 경도 정보 추출
# Kakao Developers API KEY
REST_KEY = (나의 호출 키)
import requests
import json
# 추출함수 정의
def get_kakao_lon_lat(address):
url = 'https://dapi.kakao.com/v2/local/search/address.json?query=' + address
headers = {"Authorization": "KakaoAK "+ REST_KEY}
try:
query = requests.get(url, headers=headers)
res = query.json()
xy_info = res["documents"][0]["address"]
return float(xy_info["x"]), float(xy_info["y"]) # 경도(lon), 위도(lat) 순서
except Exception as e:
print(f"에러 발생: {address} -> {e}")
return 0, 0
# Starbucks 위도, 경도 추출
lons = list()
lats = list()
for idx, row in starbucks.iterrows():
addr = row["주소"].split("(")[0].split(", ")[0]
lon, lat = get_kakao_lon_lat(addr)
if lon ==0 or lat ==0:
print(f"위도 경도 획득 오류: {row['매장명']}/ {row['주소']}")
lons.append(lon)
lats.append(lat)
starbucks["경도"] = lons
starbucks["위도"] = lats
# 이디야 위도, 경도 추출
lons = list()
lats = list()
for idx, row in ediya.iterrows():
addr = row["주소"].split("(")[0].split(", ")[0]
lon, lat = get_kakao_lon_lat(addr)
if lon ==0 or lat ==0:
print(f"위도 경도 획득 오류: {row['매장명']}/ {row['주소']}")
lons.append(lon)
lats.append(lat)
ediya["경도"] = lons
ediya["위도"] = lats4. 데이터 들여다보기
- 브랜드별 매장 현황 Bar Graph
starbucks_cnt = starbucks.groupby("구")["매장명"].count().sort_values(ascending=False).reset_index()
starbucks_cnt.columns = ["지역", "매장 수"]
ediya_cnt = ediya.groupby("구")["매장명"].count().sort_values(ascending=False).reset_index()
ediya_cnt.columns = ["지역", "매장 수"]
fig, axes = plt.subplots(1, 2, figsize=(14, 4), sharey=True)
fig.suptitle("서울 내 지역별 매장 수 비교")
axes = axes.ravel()
sns.barplot(starbucks_cnt, x="지역", y="매장 수", color="#106125", ax=axes[0])
axes[0].set_title("Starbucks")
axes[0].set_xlabel(None)
axes[0].set_ylabel(None)
axes[0].set_ylim(0, 100)
axes[0].set_xticklabels(axes[0].get_xticklabels(), rotation=90)
for idx, bar in enumerate(axes[0].patches):
if idx < 5:
axes[0].text(
x=bar.get_x() + bar.get_width()/2,
y=bar.get_height()-2,
s=f"{int(bar.get_height())}",
ha="center",
va="top",
fontweight="bold",
color="white",
size=8
)
sns.barplot(ediya_cnt, x="지역", y="매장 수", color="#061c5e", ax=axes[1])
axes[1].set_title("Ediya")
axes[1].set_xlabel(None)
axes[1].set_ylabel(None)
axes[1].set_ylim(0, 100)
axes[1].set_xticklabels(axes[1].get_xticklabels(), rotation=90)
for idx, bar in enumerate(axes[1].patches):
if idx < 5:
axes[1].text(
x=bar.get_x() + bar.get_width()/2,
y=bar.get_height()-2,
s=f"{int(bar.get_height())}",
ha="center",
va="top",
fontweight="bold",
color="white",
size=8
)
plt.tight_layout()
plt.show()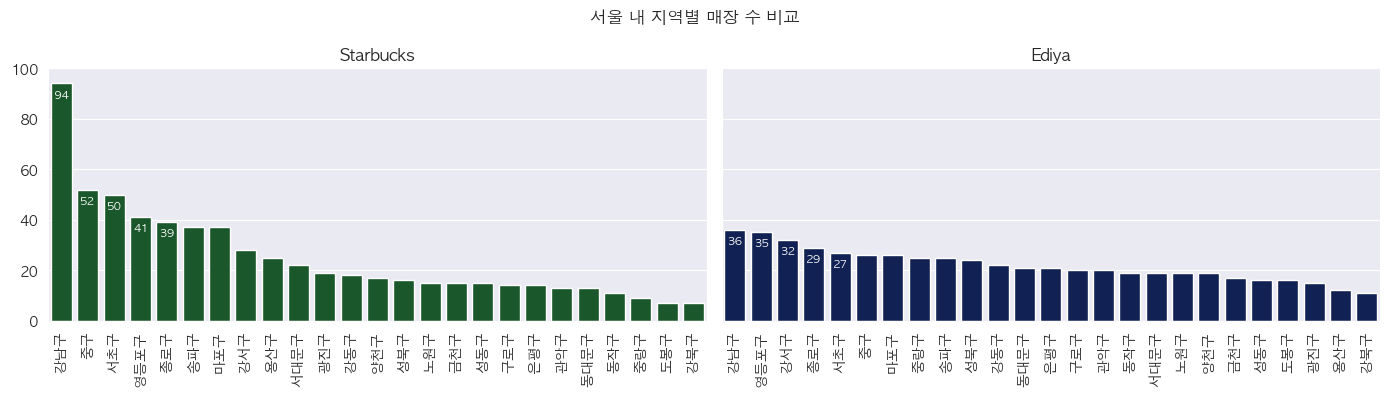
- 지역별 브랜드 매장 수 비교 Bar Graph
intg_cnt = starbucks_cnt.sort_values(by="지역").merge(ediya_cnt, how="outer", on="지역")
intg_cnt.columns = ["지역", "Starbucks", "Ediya"]
intg_cnt_melt = pd.melt(intg_cnt, id_vars="지역", var_name="구분", value_name="매장 수")
fig, ax = plt.subplots(1, 1, figsize=(18, 4))
fig.suptitle("서울 내 지역별 매장 보유 현황")
my_palette = ["#106125", "#061c5e"]
sns.barplot(intg_cnt_melt, x="지역", y="매장 수", hue="구분", ax=ax, palette=my_palette)
ax.set_xlabel(None)
ax.set_ylabel(None)
for idx, bar in enumerate(ax.patches):
ax.text(
x=bar.get_x() + bar.get_width()/2,
y=bar.get_height()-2,
s=f"{int(bar.get_height())}",
ha="center",
va="top",
fontweight="bold",
color="white",
size=8
)
plt.show()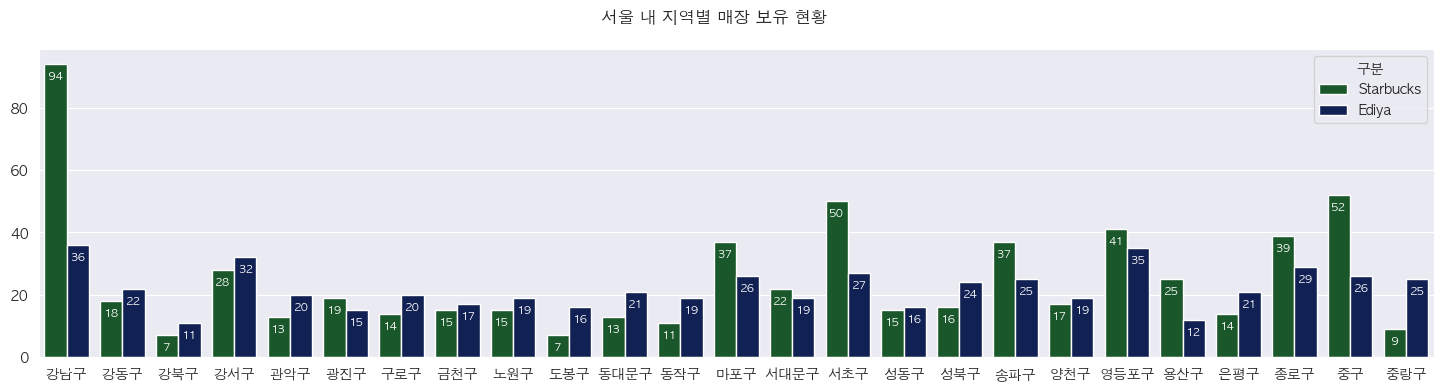
5. 시각화
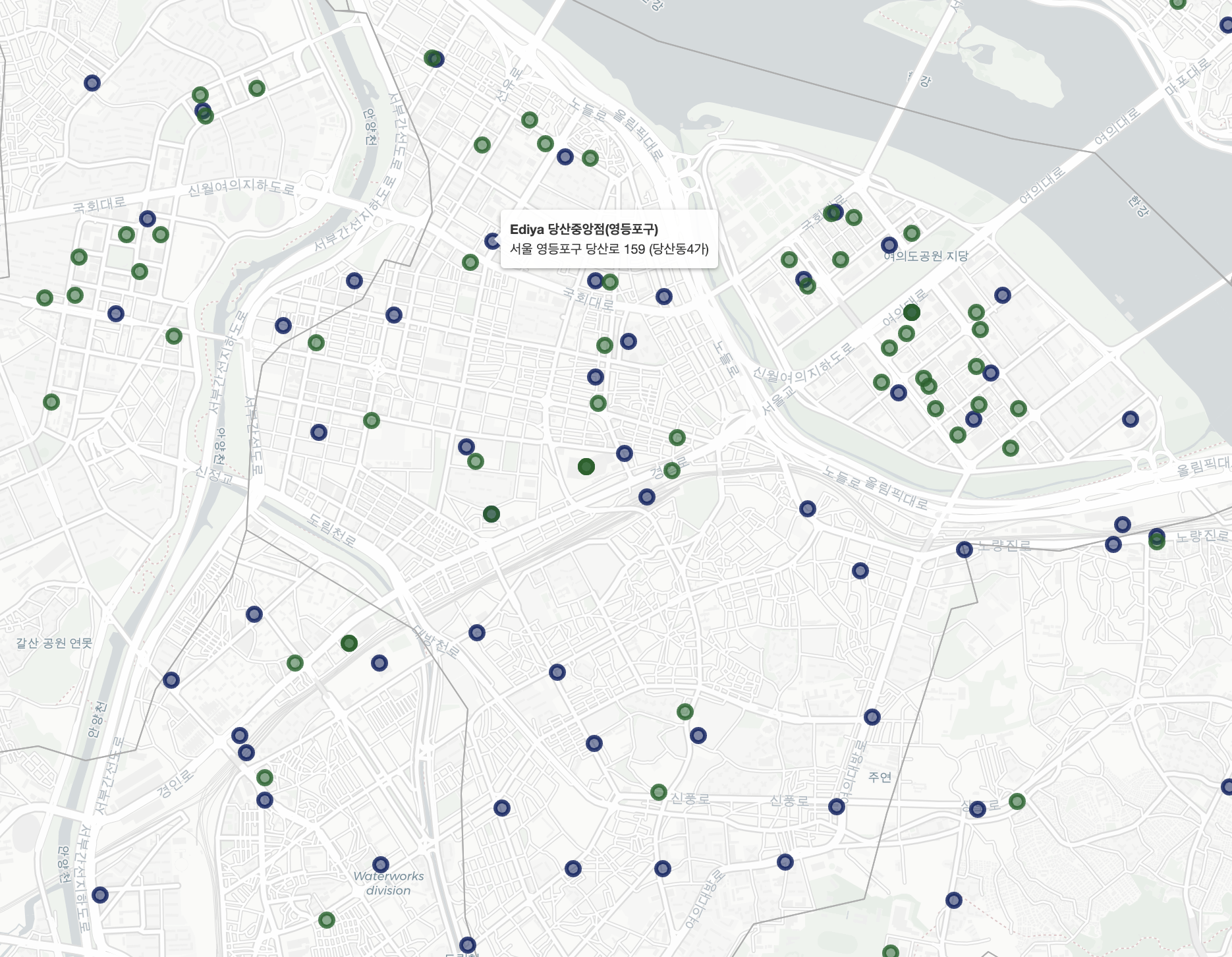
- Folium 활용 Map 시각화
seoul = [37.57, 127.01]
seoul_districts_json = "./data/seoul_municipalities_geo_simple.json"
dists = seoul_districts
map = folium.Map(location=seoul, zoom_start=12, tiles="cartodbpositron")
# 구역 설정
folium.GeoJson(
seoul_districts_json,
style_function = lambda x: {"color": "#adadad", "fillColor": "#00000000", "weight":1}
).add_to(map)
# 이디야 시각화
for idx, row in ediya.iterrows():
name = row["매장명"]
dist = row["구"]
lon = row["경도"]
lat = row["위도"]
addr = row["주소"]
folium.CircleMarker(
location=[lat, lon],
radius=5,
color="#061c5e",
opacity=0.8,
fill=True,
fill_color="#061c5e",
fill_opacity=0.5,
tooltip=f"<b>Ediya {name}({dist})</b><br>{addr}",
tags=[dist]
).add_to(map)
# 스타벅스 시각화
for idx, row in starbucks.iterrows():
name = row["매장명"]
dist = row["구"]
lon = row["경도"]
lat = row["위도"]
addr = row["주소"]
folium.CircleMarker(
location=[lat, lon],
radius=5,
color="#106125",
opacity=0.8,
fill=True,
fill_color="#106125",
fill_opacity=0.5,
tooltip=f"<b>Starbucks {name}({dist})</b><br>{addr}",
tags=[dist]
).add_to(map)
# 필터 추가
TagFilterButton(dists).add_to(map)
map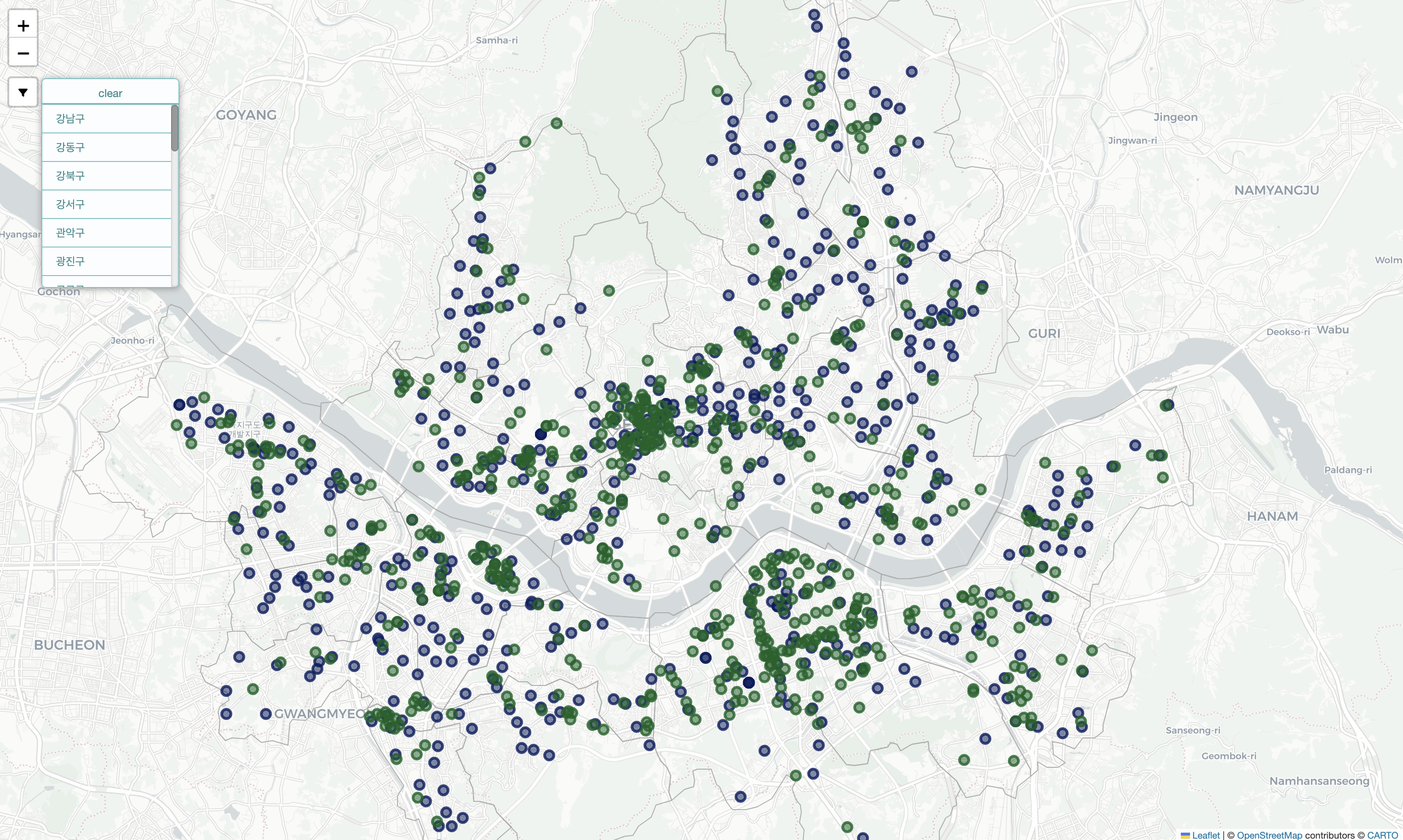
6. 결론
- Starbucks의 경우 주요 혼잡 지역(강남구, 중구)을 위주로 공격적인 매장 운영을 하고 있음을 알 수 있음
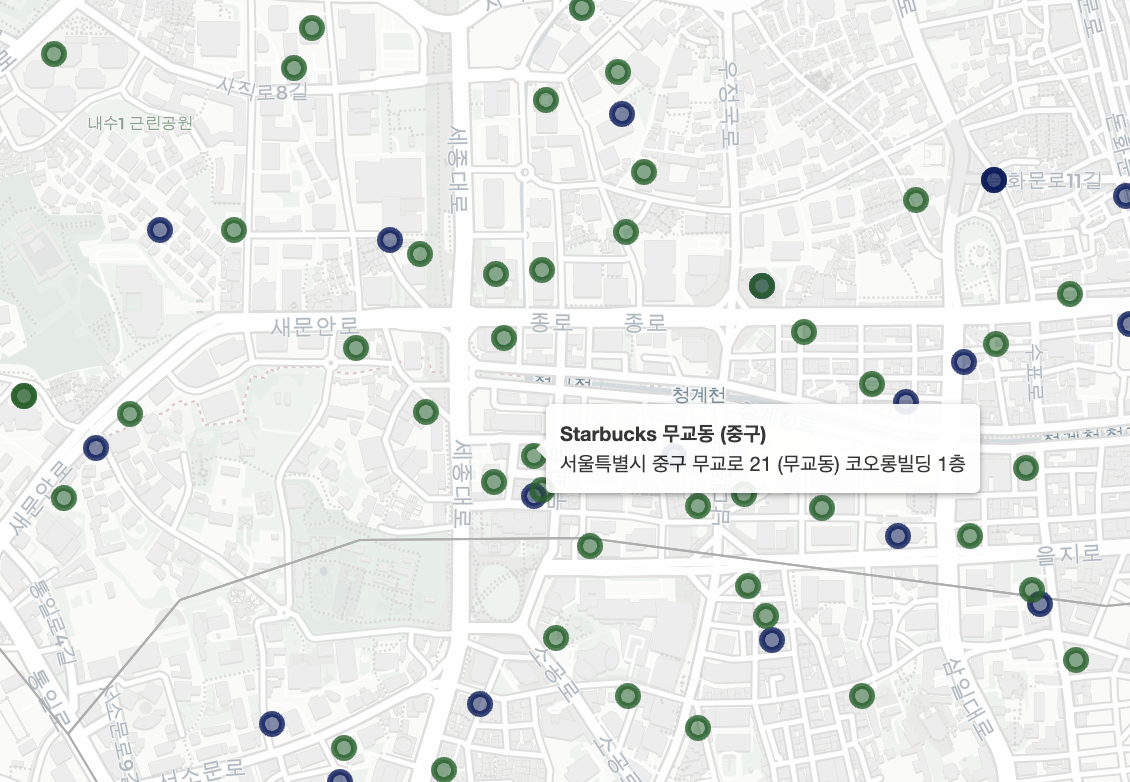
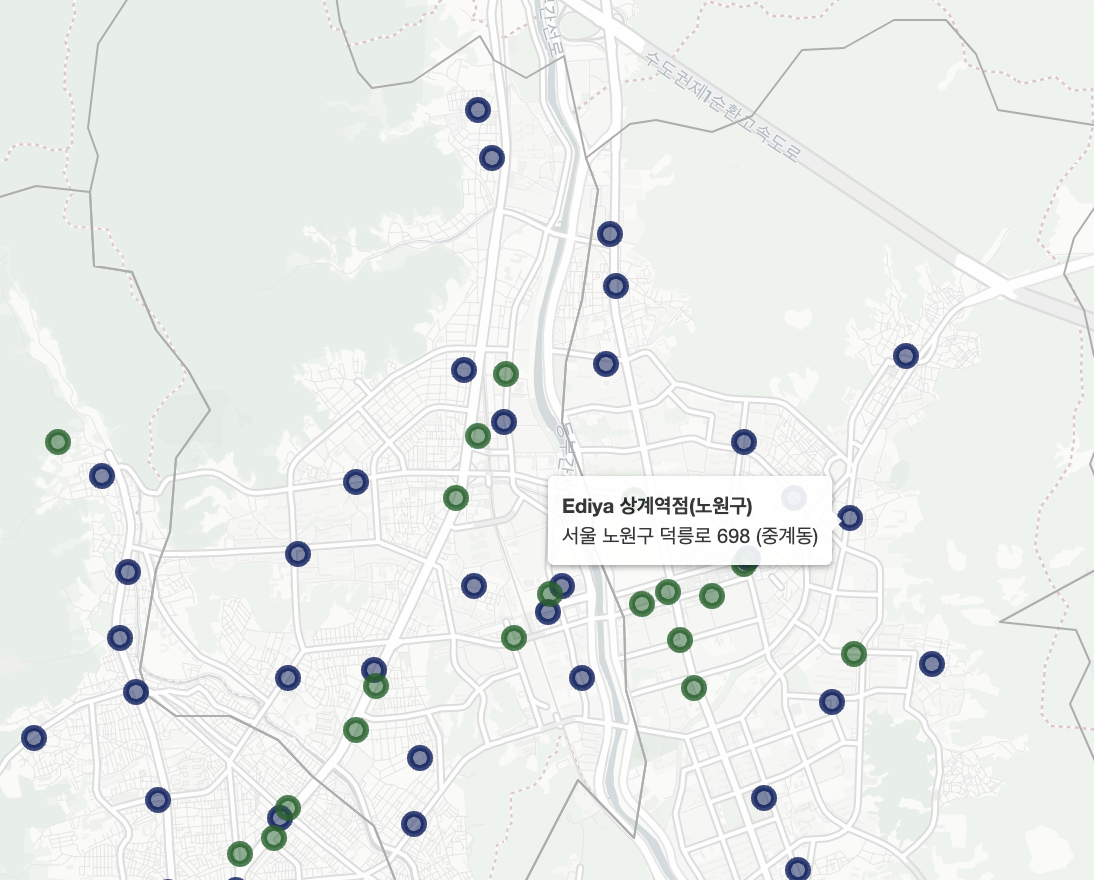
- 반면, Ediya의 경우 비 혼잡 지역(노원구, 강북구, 중랑구)에도 다수의 매장을 운영하고 있으며 Starbucks와는 다른 종류의 전략을 취하는 것으로 보임
- Starbucks 선릉역점과 Ediya 선릉역점과 같이 양 브랜드의 매장이 상당히 붙어있는 경우도 일부 확인되나, 이는 일부 혼잡지역에서만 확인되며 그렇지 않은 경우가 더 많음
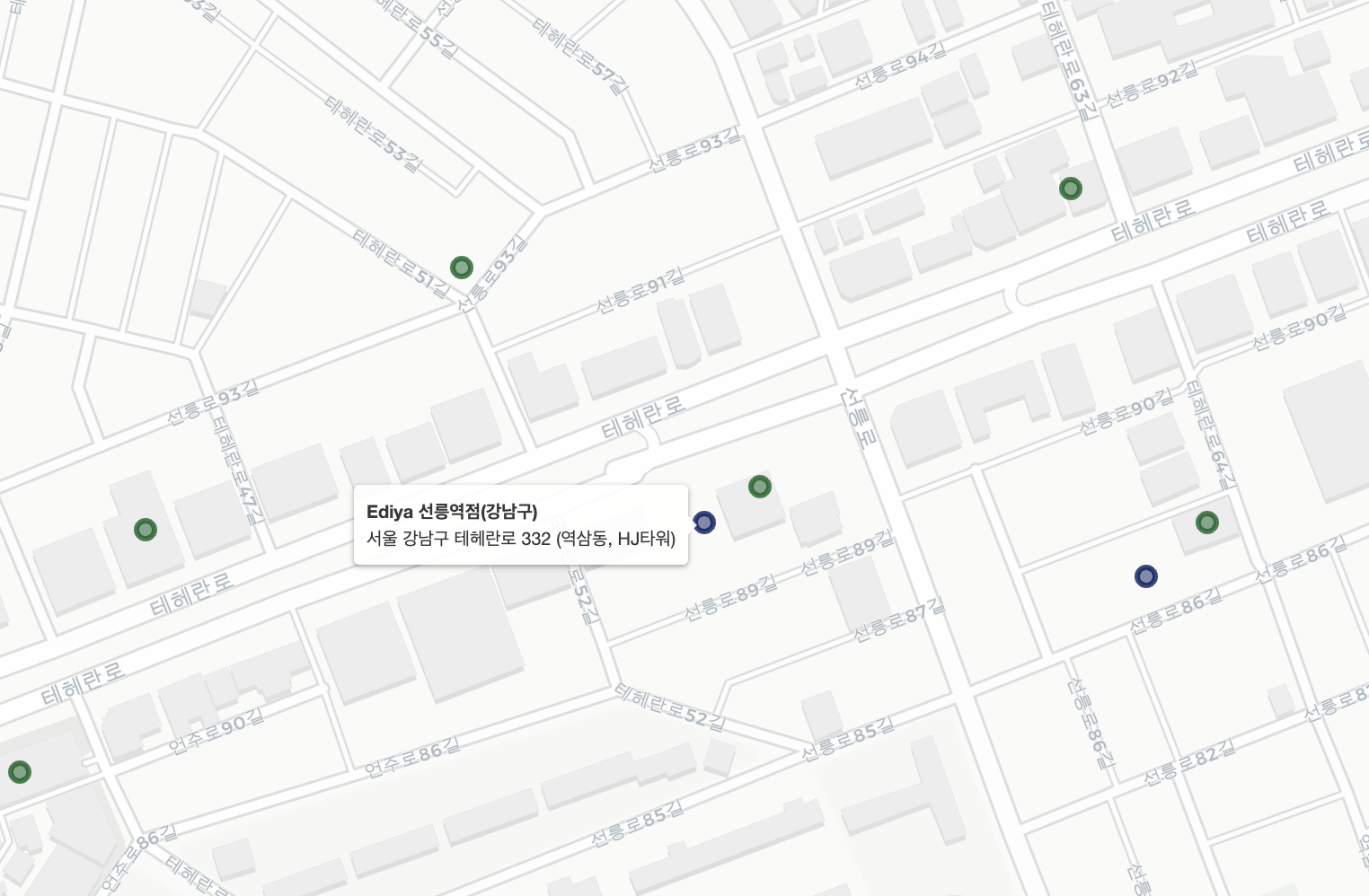
- 매장 개장 시에는 인구 유동량과 입지요건을 상당 부분 고려하기 때문에 매장의 로케이션이 겹칠 수 있어, Ediya 매장이 항상 Starbucks 매장 옆에 개장한다는 주장은 사실이라 보기 어려움
*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소