1. TensorBoard
- Tensorflow에서 제공하는 시각화 도구로, 모델 학습 과정을 추적하고 결과를 분석하는 데 사용
- 손실, 정확도의 변화 뿐만 아니라 가중치 분석, 모델 그래프 및 데이터 시각화 등 다양한 기능을 제공함
- 저장된 로그 데이터를 읽어 웹 브라우저에서 시각적으로 표시하는 방법으로 사용됨
2. Callback 기반 Logging
fit()함수 내callback파라미터를 활용하여 편리하게 로그를 기록할 수 있음
import tensorflow as tf
import datetime
# 데이터 준비
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 모델 정의 (Sequential API)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 로그 디렉토리 명시
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tb = tf.keras.callbacks.TensorBoard(
log_dir=log_dir, # 디렉토리
histogram_freq=1, # 1 에포크마다 히스토그램 데이터 기록
)
# 모델 학습
model.fit(
x_train,
y_train,
epochs=10,
batch_size=256,
validation_data=(x_test, y_test),
callbacks=[tb], # 리스트 내 callback 명시
)3. Summary 기반 Logging
tf.summary클래스를 이용하여 사용자가 직접 로그를 기록하는 방식으로, 보다 세밀한 커스터마이징이 가능함compile(),fit()과 함께 사용하기 어려우므로 수동 컴파일, 학습 단계를 구현한 다음 필요한 부분에 로그 기록 코드를 넣어 사용함
import tensorflow as tf
import datetime
# 데이터 준비
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 로그 디렉토리 설정
log_dir = "logs/summary/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
file_writer = tf.summary.create_file_writer(log_dir)
# 모델 정의 (Subclassing API)
class CustomModel(tf.keras.Model):
def __init__(self):
super(CustomModel, self).__init__()
self.flatten = tf.keras.layers.Flatten(input_shape=(28, 28))
self.dense1 = tf.keras.layers.Dense(128, activation='relu')
self.dropout = tf.keras.layers.Dropout(0.2)
self.dense2 = tf.keras.layers.Dense(10, activation='softmax')
def call(self, inputs):
x = self.flatten(inputs)
x = self.dense1(x)
x = self.dropout(x)
return self.dense2(x)
model = CustomModel()
# 수동 컴파일
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
# 수동 학습
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
@tf.function
def test_step(images, labels):
predictions = model(images)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
# epoch, batch_size 정의
EPOCHS = 10
BATCH_SIZE = 256
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(BATCH_SIZE)
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(BATCH_SIZE)
for epoch in range(EPOCHS):
# 학습 데이터
for images, labels in train_dataset:
train_step(images, labels)
# 검증 데이터
for test_images, test_labels in test_dataset:
test_step(test_images, test_labels)
# 로그 기록
with file_writer.as_default():
tf.summary.scalar('Train Loss', train_loss.result(), step=epoch)
tf.summary.scalar('Train Acc.', train_accuracy.result(), step=epoch)
tf.summary.scalar('Test Loss', test_loss.result(), step=epoch)
tf.summary.scalar('Test Acc.', test_accuracy.result(), step=epoch)
# 결과 출력
print(f'Epoch {epoch + 1}, '
f'Train Loss: {train_loss.result()}, '
f'Tran Acc.: {train_accuracy.result() * 100}, '
f'Test Loss: {test_loss.result()}, '
f'Test Acc.: {test_accuracy.result() * 100}')
# metric 초기화
train_loss.reset_state()
train_accuracy.reset_state()
test_loss.reset_state()
test_accuracy.reset_state()4. TensorBoard 실행
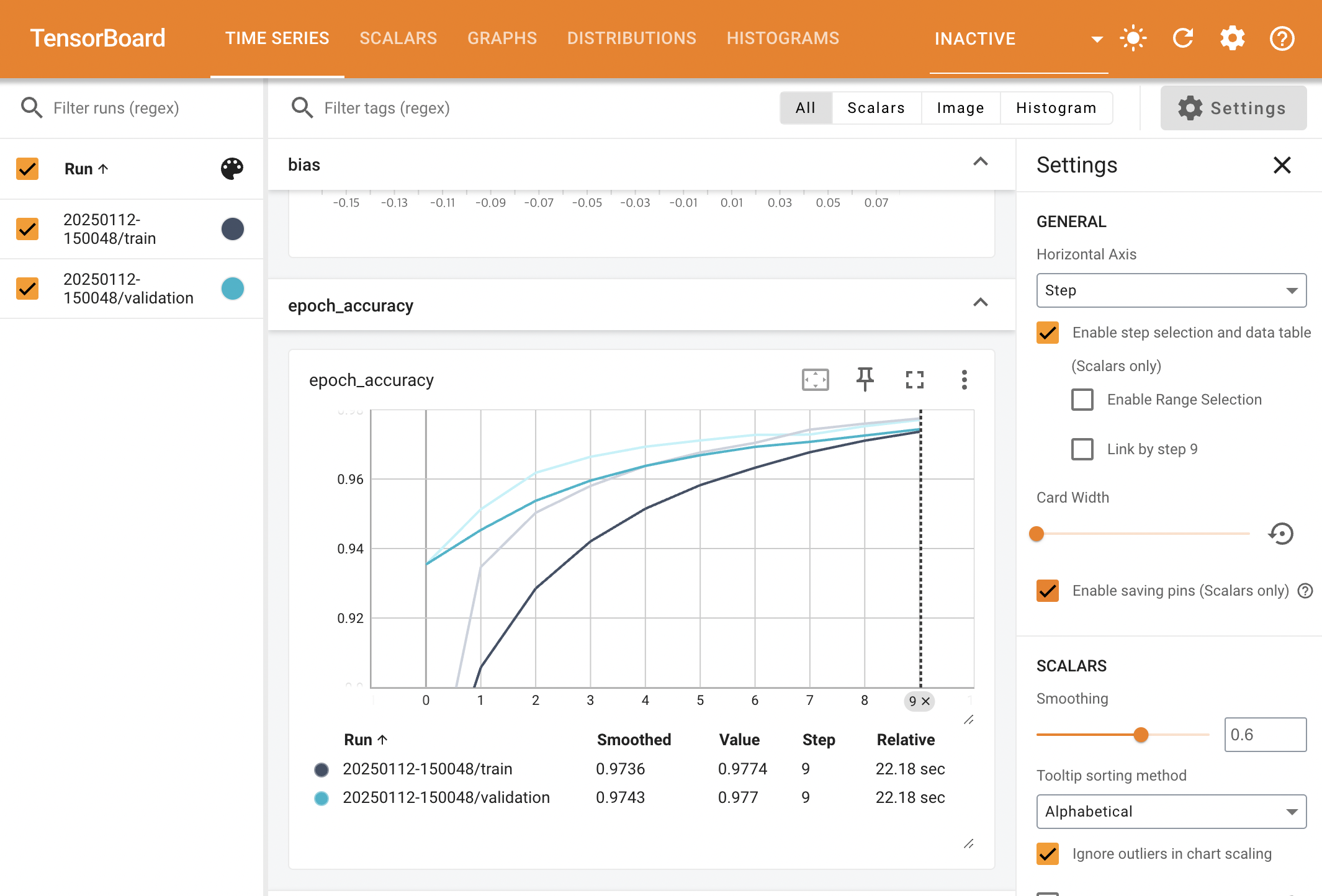
- 두 Logging 기법 중 한 가지 방법을 활용하여 로그를 기록한 후, 다음 명령어로 터미널에서 TensorBoard 실행
tensorboard --logdir=logs # --logdir={로그 디렉토리}- 브라우저에서
http://localhost:6006에 접속해 시각화 정보 확인
*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소