1. 텐서 (Tensor)
1-1. 주요 개념
-
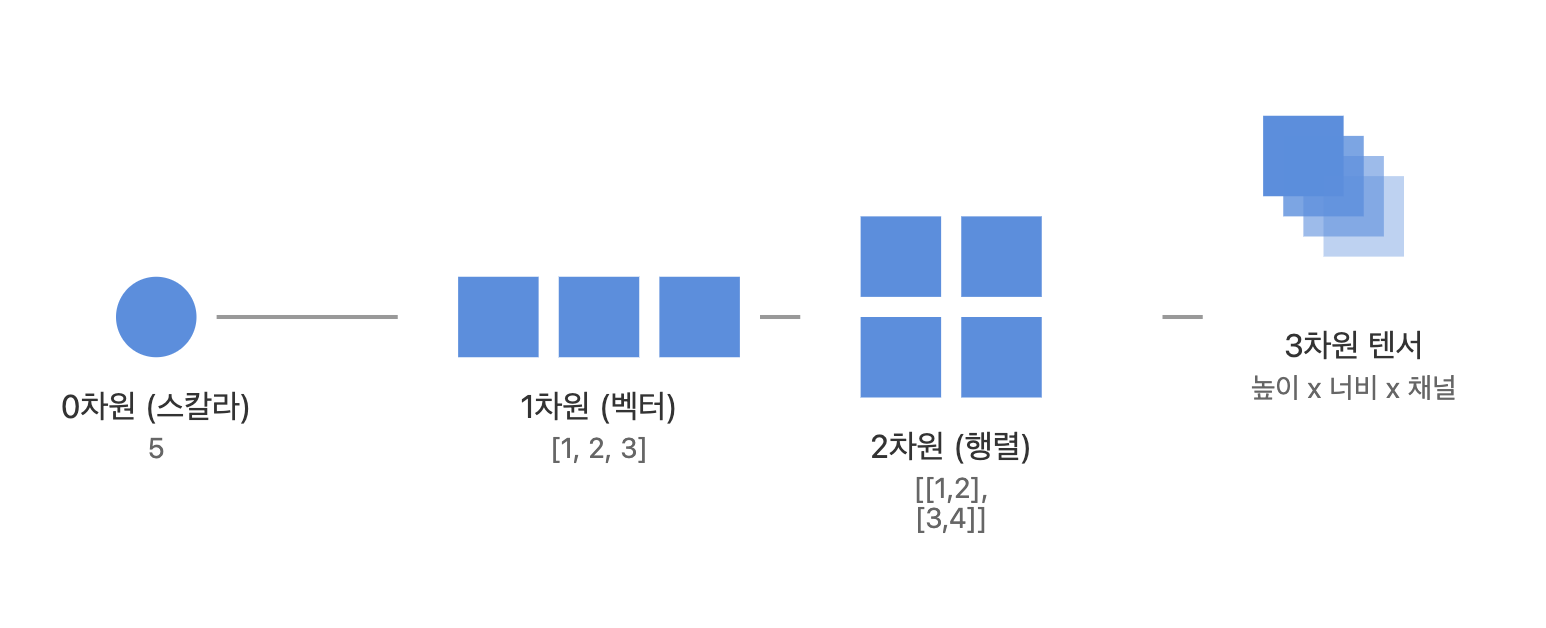
딥러닝 과정에 사용하는 N차원 배열(다차원 행렬)을 의미
ex) 0차원 텐서(스칼라, 5), 1차원 텐서(벡터, [1, 2, 3]), 2차원 텐서(행렬, [[1, 2, 3], [4, 5, 6]]) -
텐서의 핵심은 차원(rank)과 형상(shape), 데이터 타입(dtype)이라고 할 수 있음
-
딥러닝 모델 제작 중 가장 많이 발생하는 오류가 Shape 불일치 오류로 텐서의 Shape을 수시로 확인할 필요가 있으며, dtype이 같은 텐서끼리만 연산이 가능함에 유의
1-2. 생성 & 조작
-
Tensor 생성
- 상수 생성:
tf.constant - 배열 생성:
tf.zeros,tf.ones,tf.fill,tf.eye
- 상수 생성:
-
크기 조작
- 크기 변경:
tf.reshape - 차원 추가/삭제:
tf.expand_dims,tf.squeeze - 복제:
tf.tile,tf.repeat
- 크기 변경:
-
슬라이싱 및 인덱싱
- 슬라이싱:
tf.slice - 특정 인덱스 선택:
tf.gather,tf.gather_nd - 마스크 선택:
tf.boolean_mask
- 슬라이싱:
-
결합/분리
- 결합:
tf.concat,tf.stack - 분리:
tf.split,tf.unstack
- 결합:
2. 난수 생성
- 무작위 값을 생성하고자 하는 경우,
tf.random클래스 하위의 다양한 분포함수를 사용할 수 있음
# shape이 (2,2) 이면서 평균이 0, 표준편차가 1인 정규분포 기반 난수
shape = (2,2)
print(tf.random.normal(shape, 0, 1))
# tf.Tensor(
# [[-1.3544159 0.7045493 ]
# [ 0.03666191 0.86918795]], shape=(2, 2), dtype=float32)- 과정의 재현성 유지를 위해서는 Random Seed를 고정한 뒤 작업하는 습관을 들여야 함
MY_SEED = 42
tf.random.set_seed(MY_SEED)
print(tf.random.uniform([1]))
# tf.Tensor([0.6645621], shape=(1,), dtype=float32)3. 상수 (Constant)
-
상수는 값이 정해지면 변하지 않는 고정 값을 지칭
-
메모리 관리 측면에서는 상수가 훨씬 효율적임
# 리스트 이용 상수 생성
li_ten = tf.constant([1, 2, 3])
print(li_ten)
# tf.Tensor([1 2 3], shape=(3,), dtype=int32)
# 튜플 이용 상수 생성
tu_ten = tf.constant(
((1, 2, 3), (4, 5, 6,)),
name="tuple_tensor"
)
print(tu_ten)
# tf.Tensor(
# [[1 2 3]
# [4 5 6]], shape=(2, 3), dtype=int32)
# 배열 이용 상수 생성
import numpy as np
arr = np.array([1., 2., 3.,])
arr_ten = tf.constant(arr)
print(arr_ten)
# tf.Tensor([1. 2. 3.], shape=(3,), dtype=float64)
# 텐서에서 배열 추출
print(arr_ten.numpy())
# [1., 2., 3.,]
# rank, shape, dtype 확인
print(arr_ten.ndim) # 1
print(arr_ten.shape) # (3,)
print(arr_ten.dtype) # <dtype: 'float64'>4. 변수 (Variable)
-
변수는 상수와 달리 값이 고정되지 않고, 사용자가 수정할 수 있음 (즉, 공간만 만들어놓았다고 생각할 수 있음)
-
보통 미지수, 가중치 등 변할 수 있는 값을 정의할 때 사용하지만 직접 사용할일이 많지는 않음
-
값을 변경할 때에는
assign()함수를 사용하여햐 함
te_var = tf.Variable([1, 2, 3])
print(te_var)
# <tf.Variable 'Variable:0' shape=(3,) dtype=int32, numpy=array([1, 2, 3], dtype=int32)>
te_var.assign(tf.constant([4, 5, 6]))
print(te_var)
# <tf.Variable 'Variable:0' shape=(3,) dtype=int32, numpy=array([4, 5, 6], dtype=int32)>5. 텐서 연산
- 텐서 간 연산 수행 시 텐서를 반환하며, 데이터 타입이 다른 텐서 간 연산을 수행하려면
tf.cast()를 이용하여 명시적 형변환 과정을 거쳐야 함
# 다른 데이터 타입의 텐서 생성
float_tensor = tf.constant([[1.0, 2.0]], dtype=tf.float32)
int_tensor = tf.constant([[1, 2]], dtype=tf.int32)
try:
# 다른 타입 간 연산 시도
result = float_tensor + int_tensor
except tf.errors.InvalidArgumentError as e:
# InvalidArgumentError 발생
print("오류 발생:", e)
# 올바른 방법: 명시적 타입 변환 후 연산
result = float_tensor + tf.cast(int_tensor, dtype=tf.float32)5-1. 수학 연산
-
기본 산술 연산: '+', '-', '**', '@' 등 Python 기본 연산자를 사용하여도 자동 오버라이딩되어 텐서 간 연산 수행 가능
- 덧셈:
tf.add - 뺄셈:
tf.subtract - 곱셈:
tf.multiply - 나눗셈:
tf.divide - 거듭제곱:
tf.pow - 나머지:
tf.math.mod
- 덧셈:
-
기초 수학 함수
- 절댓값:
tf.abs - 제곱근:
tf.sqrt - 지수:
tf.exp - 로그:
tf.math.log - 최소/최대값:
tf.math.minimum,tf.math.maximum
- 절댓값:
-
삼각 함수
- 사인:
tf.sin - 코사인:
tf.cos - 탄젠트:
tf.tan
- 사인:
-
선형 대수 연산
- 행렬 곱셈:
tf.matmul - 행렬 전치:
tf.transpose - 행렬 역행렬:
tf.linalg.inv - 특이값 분해(SVD):
tf.linalg.svd
- 행렬 곱셈:
5-2. 통계 분석
-
기본 통계
- 평균:
tf.reduce_mean - 합계:
tf.reduce_sum - 최대값/최소값:
tf.reduce_max,tf.reduce_min - 표준 편차:
tf.math.reduce_std
- 평균:
-
정렬 및 순위
- 정렬:
tf.sort - 인덱스 반환:
tf.argsort,tf.argmax,tf.argmin
- 정렬:
5-3. 조건 & 논리 연산
-
비교 연산
- 크기 비교:
tf.greater,tf.less,tf.greater_equal,tf.less_equal - 동등성 비교:
tf.equal,tf.not_equal
- 크기 비교:
-
논리 연산
- AND, OR, NOT:
tf.logical_and,tf.logical_or,tf.logical_not
- AND, OR, NOT:
-
조건문
- 조건 처리:
tf.where
- 조건 처리:
5-4. 문자열 처리
- 문자열 합치기:
tf.strings.join - 문자열 분할:
tf.strings.split - 문자열 변환:
tf.strings.to_number,tf.strings.format
5-5. 신경망 조작
-
활성화 함수
- ReLU:
tf.nn.relu - Sigmoid:
tf.nn.sigmoid - Softmax:
tf.nn.softmax
- ReLU:
-
손실 함수
- MSE:
tf.keras.losses.MeanSquaredError - Cross-Entropy:
tf.keras.losses.CategoricalCrossentropy
- MSE:
-
합성곱
- 2D 합성곱:
tf.nn.conv2d - 1D 합성곱:
tf.nn.conv1d
- 2D 합성곱:
-
풀링
- 최대 풀링:
tf.nn.max_pool - 평균 풀링:
tf.nn.avg_pool
- 최대 풀링:
5-6. 데이터 처리
- 데이터셋 생성:
tf.data.Dataset.from_tensor_slices,tf.data.Dataset.range - 데이터셋 변환:
map,filter,batch,shuffle
*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소