1. 하이퍼파라미터 튜닝
- 하이퍼파라미터(Hyperparameter, 초매개변수)는 머신러닝 모델 학습 과정 중 분석자가 임의로 설정할 수 있는 값을 말함
- 모델의 가중치(Weight)나 편향(Bias)처럼 학습 과정에서 자동으로 업데이트되는 파라미터(Parameter)와는 구분되는 개념임에 유의
- 올바른 하이퍼파라미터의 선택은 모델의 예측성능에 큰 영향을 미칠 수 있으, 최적의 조합을 찾아가는 과정을 '하이퍼파라미터 튜닝'이라고 함
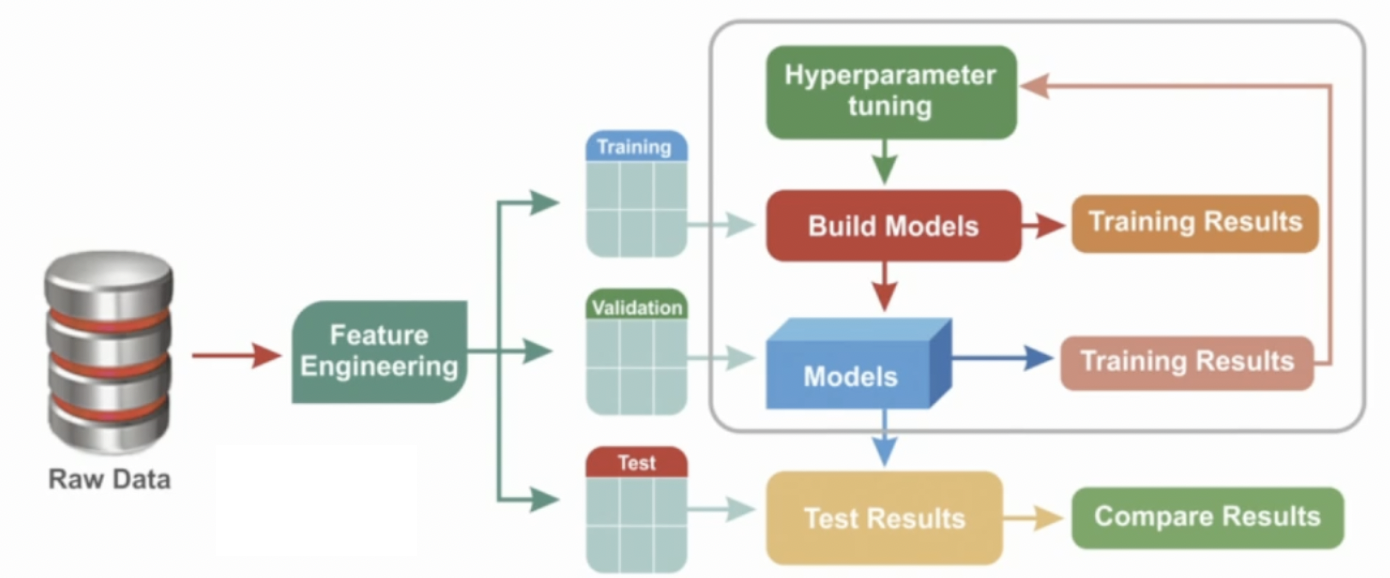 ML 진행 과정
ML 진행 과정
2. 주요 튜닝 기법
2-1. 격자 탐색 (Grid Search)
- 사전 정의된 값의 범위 내에서 모든 조합을 테스트하여 최적의 하이퍼 파라미터를 찾음
- 계산비용이 높지만, 정의된 값의 범위 내 최적값을 도출해 낼 수 있음
2-2. 임의 탐색 (Random Search)
- 하이퍼 파라미터 공간에서 임의의 값을 샘플링하여 최적값을 찾음
- 격자 탐색보다는 효율적으로 자원을 활용할 수 있지만, 최적값을 놓칠 수 있음
2-3. 베이지안 최적화 (Bayesian Optimization)
- 확률 모델을 사용하여 이전 탐색과정의 결과를 바탕으로 다음 탐색과정의 최적 하이퍼파라미터를 찾아가는 방법
- 적은 반복으로 최적값에 수렴 가능하나, 연산시간이 많이 소요되고 구현이 복잡함
2-4. Optuna
- 사용자가 직접 최적화 과정을 설계할 수 있도록 유연한 기능을 제공하는 튜닝 라이브러리
pip install optuna명령어를 통해 라이브러리를 설치할 수 있음
3. 예제
3-1. Grid Search (속도 가장 느림)
import pandas as pd
wine = pd.read_csv("./data/wine.csv")
X = wine.drop(columns="type")
y = wine["type"]
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
# 탐색범위 정의
param_grid = {
"max_depth": [1, 2, 3, 4, 5, 6],
"min_samples_split": [2, 3, 4, 5, 6, 7],
}
estimator = DecisionTreeClassifier(random_state=42)
# 탐색 실시
gs = GridSearchCV(estimator, param_grid, cv=5)
gs.fit(X, y)
# 탐색 결과 출력
print(f"Best Score: {gs.best_score_:.3f}")
print(f"Best Parameters: {gs.best_params_}")
## 출력 결과
# Best Score: 0.981
# Best Parameters: {'max_depth': 5, 'min_samples_split': 2}3-2. Random Search (속도 중간)
from scipy.stats import randint # random 라이브러리의 randint는 사용 불가 (non-iterable)
from sklearn.model_selection import RandomizedSearchCV
# 각 분포 내 임의의 정수 1개씩 추출토록 정의
param_dist = {
"max_depth": randint(1, 10),
"min_samples_split": randint(2, 20),
}
# 10회 임의 반복
rs = RandomizedSearchCV(estimator, param_dist, n_iter=10, cv=5, random_state=42)
rs.fit(X, y)
print(f"Best Score: {rs.best_score_:.3f}")
print(f"Best Parameters: {rs.best_params_}")
## 출력 결과
# Best Score: 0.981
# Best Parameters: {'max_depth': 5, 'min_samples_split': 2}3-3. Optuna (속도 가장 빠름)
import optuna
import numpy as np
from sklearn.model_selection import cross_val_score
# 목적함수 정의
def objective(trial):
# 탐색 범위 설정
max_depth = trial.suggest_int("max_depth", 1, 10) # (별칭, 시작범위, 종료범위)
min_samples_split = trial.suggest_int("min_samples_split", 2, 20)
estimator = DecisionTreeClassifier(
random_state=42,
max_depth=max_depth, # 하이퍼파라미터 할당
min_samples_split=min_samples_split, # 하이퍼파라미터 할당
)
# CV 결과 평균
avg_score = cross_val_score(estimator, X, y, cv=5, scoring="accuracy").mean()
# CV 결과 반환
return avg_score
# 탐색 조건 설정 (CV 결과과 최대화 되는 방향으로 탐색할 것)
study = optuna.create_study(direction="maximize")
# 탐색 실시 (정의한 목적함수를 10회 반복할 것)
study.optimize(objective, n_trials=10)
# 탐색 결과 확인
print(f"Best Score: {study.best_value:.3f}")
print("Best Params:", study.best_params)
## 출력 결과
# [I 2025-01-01 16:11:14,867] A new study created in memory with name: no-name-cb626e8d-b97c-4704-94f6-32a2c844dd5f
# [I 2025-01-01 16:11:14,928] Trial 0 finished with value: 0.9786046070942145 and parameters: {'max_depth': 4, 'min_samples_split': 8}. Best is trial 0 with value: 0.9786046070942145.
# [I 2025-01-01 16:11:15,028] Trial 1 finished with value: 0.9813753775093266 and parameters: {'max_depth': 10, 'min_samples_split': 7}. Best is trial 1 with value: 0.9813753775093266.
# [I 2025-01-01 16:11:15,129] Trial 2 finished with value: 0.9781434239355719 and parameters: {'max_depth': 10, 'min_samples_split': 14}. Best is trial 1 with value: 0.9813753775093266.
# [I 2025-01-01 16:11:15,211] Trial 3 finished with value: 0.9796820039083318 and parameters: {'max_depth': 7, 'min_samples_split': 10}. Best is trial 1 with value: 0.9813753775093266.
# [I 2025-01-01 16:11:15,277] Trial 4 finished with value: 0.9761417658553917 and parameters: {'max_depth': 5, 'min_samples_split': 20}. Best is trial 1 with value: 0.9813753775093266.
# [I 2025-01-01 16:11:15,365] Trial 5 finished with value: 0.9769111150589211 and parameters: {'max_depth': 8, 'min_samples_split': 20}. Best is trial 1 with value: 0.9813753775093266.
# [I 2025-01-01 16:11:15,449] Trial 6 finished with value: 0.9802971516551194 and parameters: {'max_depth': 7, 'min_samples_split': 4}. Best is trial 1 with value: 0.9813753775093266.
# [I 2025-01-01 16:11:15,494] Trial 7 finished with value: 0.9673681530171138 and parameters: {'max_depth': 3, 'min_samples_split': 16}. Best is trial 1 with value: 0.9813753775093266.
# [I 2025-01-01 16:11:15,517] Trial 8 finished with value: 0.9130360632439155 and parameters: {'max_depth': 1, 'min_samples_split': 16}. Best is trial 1 with value: 0.9813753775093266.
# [I 2025-01-01 16:11:15,609] Trial 9 finished with value: 0.9801434239355717 and parameters: {'max_depth': 8, 'min_samples_split': 8}. Best is trial 1 with value: 0.9813753775093266.
# Best Score: 0.981
# Best Params: {'max_depth': 10, 'min_samples_split': 7}*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소