1. 교차검증(Cross-validation; CV)
-
Python의 scikit-learn 라이브러리에서 제공하는
train_test_split()함수는 대표적인 '홀드 아웃(Hold Out)' 기법에 해당하나, 이 경우 데이터셋을 어떻게 분할하느냐에 따라 결과가 변하는 상황이 발생할 수 있음 -
따라서, 데이터셋을 여러 번 나누어 학습과 평가를 반복하고, 각 평가의 성능을 종합함으로써 모델의 일반화 성능을 측정하는 방법이 '교차 검증(Cross-validation)'에 해당됨
-
이를 통해 모델이 훈련 데이터에 과적합(overfitting)되지 않았는지 확인할 수 있고, 예측 성능이 일정하게 유지되고 있는지 검증할 수 있음
2. 교차검증의 종류
2-1. k-겹 교차검증 (k-fold Cross-validation)
- 데이터를 k개의 동일한 크기로 나눔
- k-1개 부분의 데이터는 훈련 데이터로, 1개 부분의 데이터는 검증 데이터로 사용하여 총 k번의 학습/평가 과정 반복
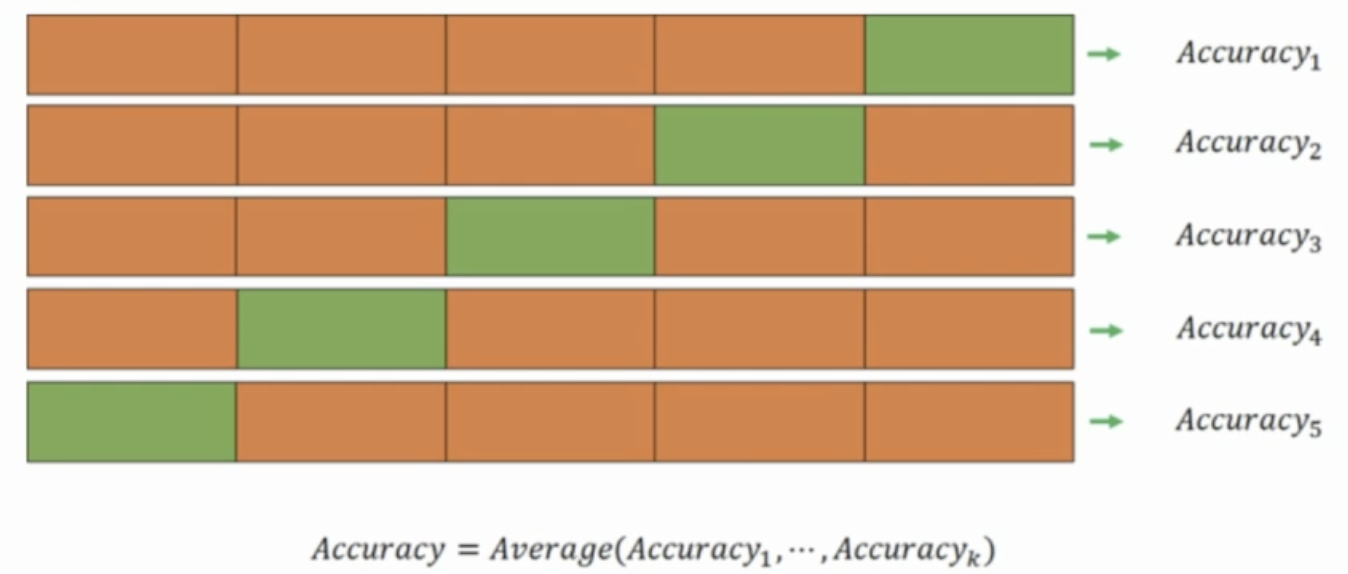 5-fold CV 예시
5-fold CV 예시
2-2. Stratified k-겹 교차검증 (Stratified k-fold Cross-validation)
- k-겹 교차검증의 변형으로, 각 폴드에 클래스의 비율을 동일하게 유지(stratify)함
- 주로 클래스 불균형 문제를 다룰 때 유용함
2-3. Leave-One-Out Cross-Validation (LOOCV)
- 1개의 데이터 샘플만 검증 데이터로, 나머지 데이터 전체를 훈련 데이터로 하여 데이터의 총 샘플 수만큼 학습/평가 과정 반복
- 데이터의 크기가 작을 때 유용하지만 계산 비용이 많이 듬
2-4. Time Series Cross-Validation
- 시계열 데이터는 이전 시점의 데이터가 다음 시점의 데이터와 연관이 있어, 일반적인 CV와 같이 임의로 데이터를 나눌 수 없음
- 따라서, Rolling Window(시간의 흐름에 따라 고정 크기의 Window를 이동하며 CV) 방식이나, Expanding Window(시간의 흐름에 따라 훈련 데이터의 크기를 확장시켜가며 CV) 방식을 활용하여야 함
3. 예제 코드
3-1. 5-fold CV
import pandas as pd
from sklearn.svm import SVC
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
wine = pd.read_csv("./data/wine.csv")
X = wine.drop(columns="type")
y = wine["type"]
# 5-fold CV 정의
# 데이터의 순서가 특별히 중요하지 않은 경우 shuffle=True 추천
cv = KFold(n_splits=5, shuffle=True, random_state=42)
# 각 CV 별 정확도 계산 후 출력
for split, (train_idx, test_idx) in enumerate(cv.split(X, y)):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
clf = SVC(kernel="rbf", random_state=42)
clf.fit(X_train, y_train)
print(f"Split {split+1} Accuracy -> {accuracy_score(y_test, clf.predict(X_test)):.3f}")
## 출력 결과
# Split 1 Accuracy -> 0.928
# Split 2 Accuracy -> 0.929
# Split 3 Accuracy -> 0.947
# Split 4 Accuracy -> 0.932
# Split 5 Accuracy -> 0.9423-2. Stratified 5-fold CV
from sklearn.model_selection import StratifiedKFold
scv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
for split, (train_idx, test_idx) in enumerate(scv.split(X, y)):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
clf = SVC(kernel="rbf", random_state=42)
clf.fit(X_train, y_train)
print(f"Split {split+1} Accuracy -> {accuracy_score(y_test, clf.predict(X_test)):.3f}")
## 출력 결과
# Split 1 Accuracy -> 0.932
# Split 2 Accuracy -> 0.935
# Split 3 Accuracy -> 0.937
# Split 4 Accuracy -> 0.938
# Split 5 Accuracy -> 0.9383-3. Stratified 5-fold CV (w/ Scaling + Pipeline)
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score
pipeline = Pipeline([
("SS", StandardScaler()),
("svc", SVC(kernel="rbf", random_state=42))
])
scv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# cross_val_score 함수를 통해 훨씬 간편히 cv 수행 가능
scores = cross_val_score(pipeline, X, y, cv=scv, scoring="accuracy")
print("Mean Accuarcy: {:.3f}".format(np.mean(scores)))
## 출력 결과
# Mean Accuarcy: 0.996*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소