[Photogrammetry] 8-1. Visual Features Part2: Descriptors (SIFT, BRIEF, ORB)
Photogrammetry (Cyrill Stachniss)
Binary features - 5 minutes with Cyrill
앞서 배운 SIFT는 성능이 검증된 알고리즘이지만, 128차원이라는 높은 차원의 벡터를 가졌기 때문에 연산량이 많다는 단점이 있었다.
따라서 이에 대한 대안책으로 제시된 것이 바로 binary descriptor을 이용하는 BRIEF 알고리즘이다. SIFT의 아쉬움을 보완한 것이므로, desciptor을 계산할 때 더 빠르고 쉬운 장점이 있다.
Binary descriptor
: 이진 테스트(Binary test)을 이용하여 부분 영상의 특징을 기술
: 이진 기술자를 사용하는 알고리즘 ex. AKAZE, ORB, BRIEF
: 이진 기술자는 해밍거리(Hamming distance)를 사용하여 유사도를 판단
BRIEF 알고리즘
- Binary
- Robust
- Independent
- Elementary
- Features
: 각각의 bit는 1:1 comparison에 의하여 계산된다.
: 이 알고리즘은keypoint을 검출하는 알고리즘이 아니라, 검출된 keypoint에 대한 descriptor 생성하는데 사용한다.
:keypont주변 영역의 픽셀을 다른 픽셀과 비교해 어느 부분이 더 밝은지 찾아 이진 형식으로 저장한다고 할 수 있다.
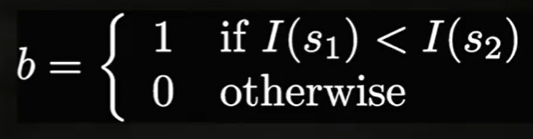
간단한 예시
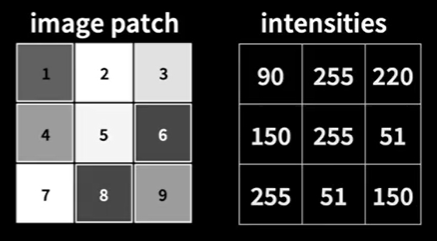 우리는 다음과 같은 예에서 descriptor을 만들어보겠다.
우리는 다음과 같은 예에서 descriptor을 만들어보겠다.
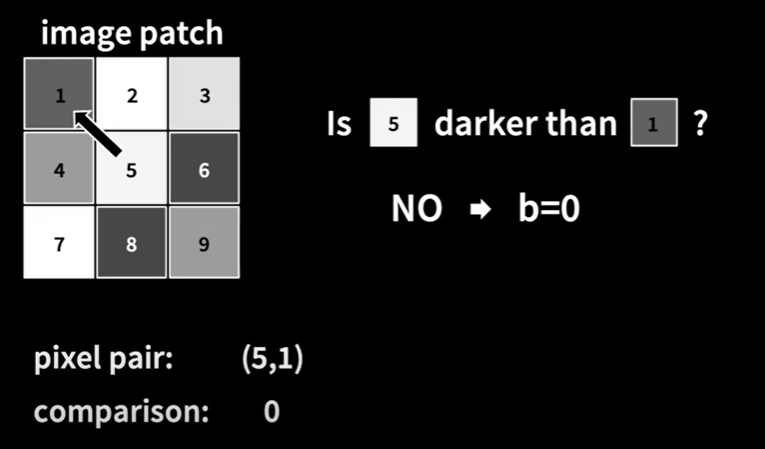 위에서 정의한 식에 따르면 I(5) = 255, I(1) = 90이고, I(5) > I(1)이기 때문에 b = 0이 된다.
위에서 정의한 식에 따르면 I(5) = 255, I(1) = 90이고, I(5) > I(1)이기 때문에 b = 0이 된다.
이러한 과정을 계속 반복하게 되면,
 다음과 같은 결과를 얻을 수 있다.
다음과 같은 결과를 얻을 수 있다.
ORB(Oriented FAST Rotated BRIEF) 알고리즘
: BRIEF의 확장버전
: image의 rotation에 강한 성질을 갖고 있다.
: patch의 main orienatation을 측정함
START!
Motivation
 우리는 이전 강의에서 다음 두 사진을 matching하기 위하여 keypoint를 찾는 방법을 공부했었다. 이번 강의에서는 이러한 keypoint에 대한 정보를 담고 있는 descriptor에 대하여 알아볼 예정이다.
우리는 이전 강의에서 다음 두 사진을 matching하기 위하여 keypoint를 찾는 방법을 공부했었다. 이번 강의에서는 이러한 keypoint에 대한 정보를 담고 있는 descriptor에 대하여 알아볼 예정이다.
Visual Features: Keypoints and Descriptors
앞서 배운 내용을 다시 한번 정리하겠다.
Keypoint란 이미지에서 locally distinct location을 의미한다.
feature descriptor이란 keypoint 주변에서 local structure을 요약해주는 역할을 한다.
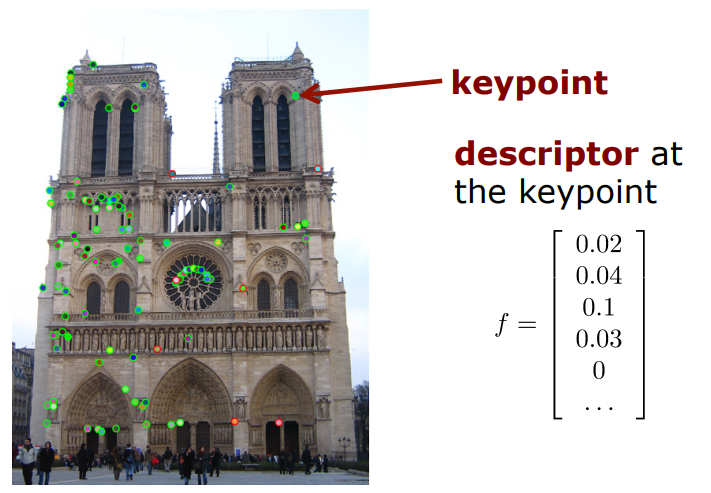 이렇게 keypoint에 대하여 vector로 표현한 형태가 descriptor이다.
이렇게 keypoint에 대하여 vector로 표현한 형태가 descriptor이다.
Today's Topics
 그렇다. 오늘은 descriptor에 대해 배우고 descriptor을 만드는 다양한 알고리즘에 대하여 알아볼 것이다.
그렇다. 오늘은 descriptor에 대해 배우고 descriptor을 만드는 다양한 알고리즘에 대하여 알아볼 것이다.
DoG(Difference of Gaussians)
저번 시간에 배운 내용 짧게 복습하겠다.
우리는 다양한 image pyramid level을 이용하여

1.
(STEP1) Gaussian smoothing: 원본 이미지를 여러 크기로 만든 다음에 점진적으로 blur처리를 하였는데, 이때 blur처리를 할 때 gausisan연산이 사용된다.
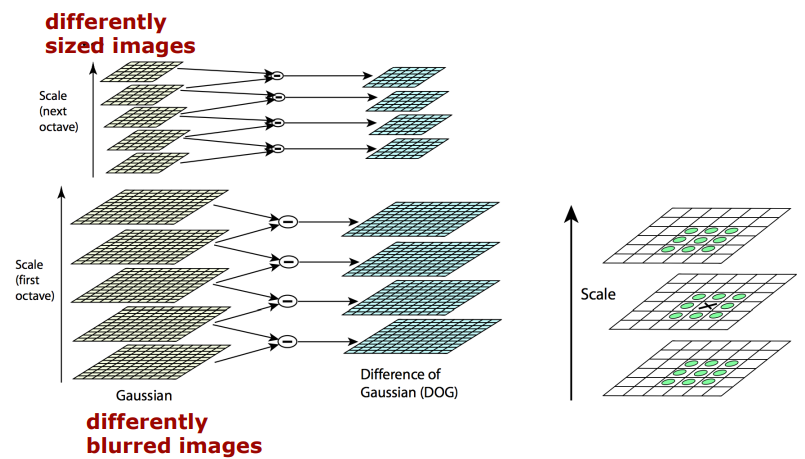
2.
(STEP2) Difference-of-Gaussians and find extrema
: 전 단계에서 얻은 같은 Octative 내에 인접한 두 개의 blur 이미지를 빼준다. 그리고 DoG이미지 내에서 극댓값, 극솟값의 대략적인 위치를 찾는다.
: 한 픽셀에서의 극댓값, 극솟값을 결정할 때는 동일한 octave 내에서의 3장의 DoG이미지가 필요하다. 체크할 DoG이미지와 scale이 한단계씩 다른 위아래 DoG이미지에서 체크하려고 하는 픽셀과 가까운 9개 총 26개 검사하고, 지금 체크하는 픽셀의 값이 26개의 이웃 픽셀값 중에 가장 작거나 가장 클 때 keypoint로 인정되는 것이다.
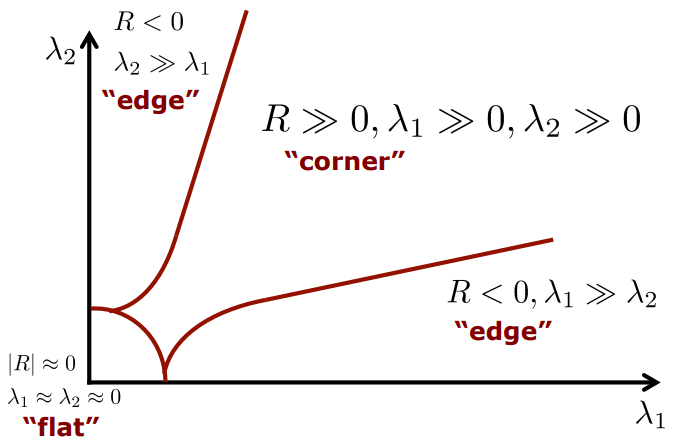
3.
(STEP3) maxima suppression for edges
: 다음 사진은 Harris Corner Criterion을 첨부하였다. 여기서는 앞선 단계에서 찾은 keypoint 중에서 활용가치가 떨어지는 keypoint들은 제거해준다고 생각하는 것이 좋다. Eigenvalue test를 통해서 edge는 제거하고 corner만 남게 하는 것이 이 단계의 목적이다.
Popular Features Descriptors
 다음 사진과 같이 descriptor을 찾는 알고리즘은 정말정말로 많은데.. 우리는 이 중에서 SIFT, BRIEF, ORB에만 집중하겠다.
다음 사진과 같이 descriptor을 찾는 알고리즘은 정말정말로 많은데.. 우리는 이 중에서 SIFT, BRIEF, ORB에만 집중하겠다.
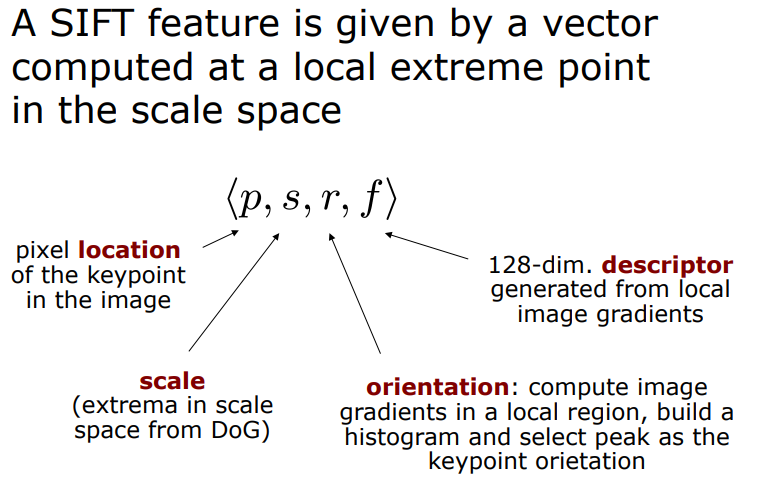
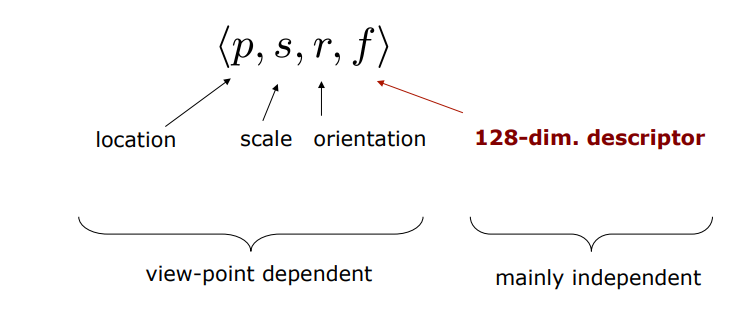
SIFT Descriptor
SIFT(Scale Invariant Feature Transform)
image는 다음과 같은 transform에 invariant하다.
-image translation
-rotation
-scale
: 예를 들어, 이미지를 옆으로 조금 옮겨도 descriptor은 그대로라는 것이다.
그리고 다음과 같은 transform에 대해서는 partially invariant하다.
-illumination changes
-affline transformation,3D projections
: affline transformation이란 선형변환 중 하나로 점, 직선, 평면을 보존한다.

visual landmarks를 찾는데에 적합하다.
- 다양한
angels와distances에 대하여- 다양한
illumination에 대하여
SIFT Features
SIFT Considers the Distribution of Gradients Around Keypoints
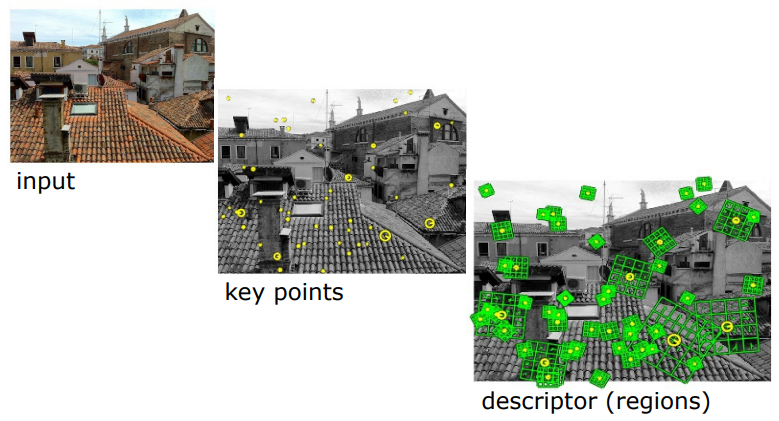 현재 우리가 하고 있는 과정을 사진으로 보면 한눈에 이해할 수 있다.
현재 우리가 하고 있는 과정을 사진으로 보면 한눈에 이해할 수 있다.
SIFT Descriptor in Sum
우리는 이제 keypoint들의 위치 & 스케일 & 방향을 알고 있는 상태이다. 이제 이 keypoint들을 식별하기 위해 지문(fingerprint)과 같은 특별한 정보를 각각 부여해줘야 한다. 각각의 keypoint의 특징을 128개의 숫자(keypoint descriptor)로 표현을 한다.
8 orientations x 4 x 4 histogram array = 128 dimensions (yields best results)이를 위해 keypoint 주변의 모양변화에 대한 경향을 파악한다.
keypoint 주변에 16x16 윈도우를 세팅하는데, 이 윈도우는 작은 16개의 4x4 윈도우로 구성된다.
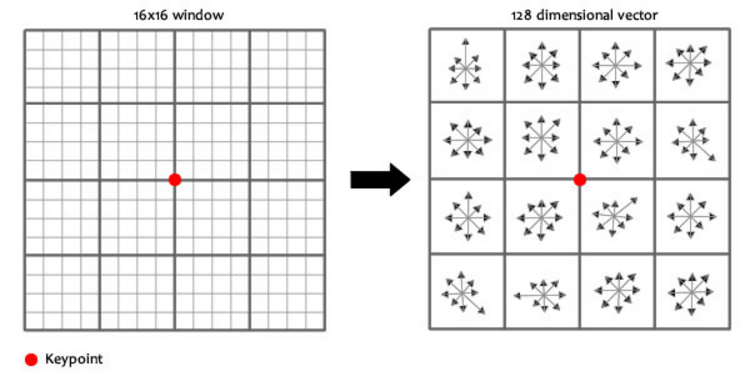
SIFT Illustration
이제 예시를 통하여 이해를 해보겠다.
 다음 사진에서는 given keypoint가 있다. keypoint 주변의 지역을 orientation과 scale에 맞게 warp(왜곡)한 후에 그 지역을 16x16 pixel로 resize한다.
다음 사진에서는 given keypoint가 있다. keypoint 주변의 지역을 orientation과 scale에 맞게 warp(왜곡)한 후에 그 지역을 16x16 pixel로 resize한다.
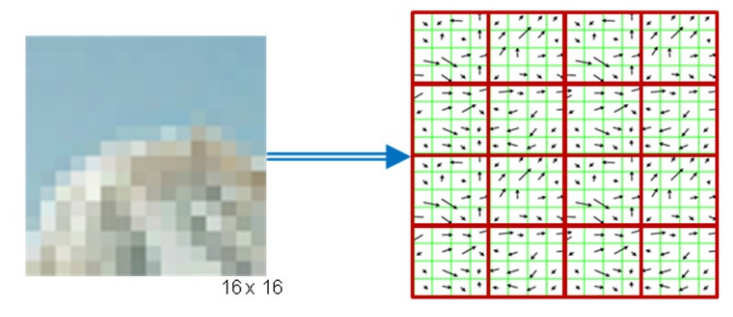 각각 픽셀에 대하여 gradients를 계산하고, 픽셀을 16개(4x4 pixels squares)로 나눈다.
각각 픽셀에 대하여 gradients를 계산하고, 픽셀을 16개(4x4 pixels squares)로 나눈다.
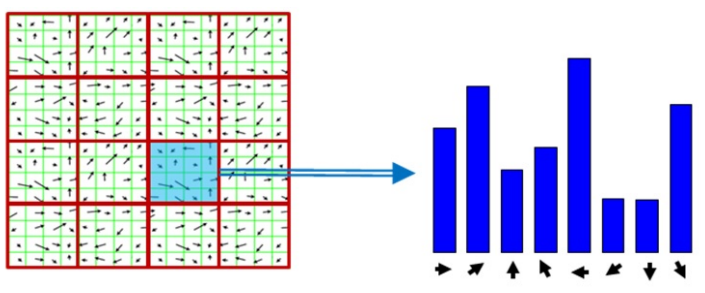 각각의 square은, 8개의 directions에 대하여 gradient direction histogram을 계산한다.
각각의 square은, 8개의 directions에 대하여 gradient direction histogram을 계산한다.
 histogram들을 연결하여 128(16x8)차원의 feature vector을 얻는다.
histogram들을 연결하여 128(16x8)차원의 feature vector을 얻는다.
SIFT Descriptor Illustration
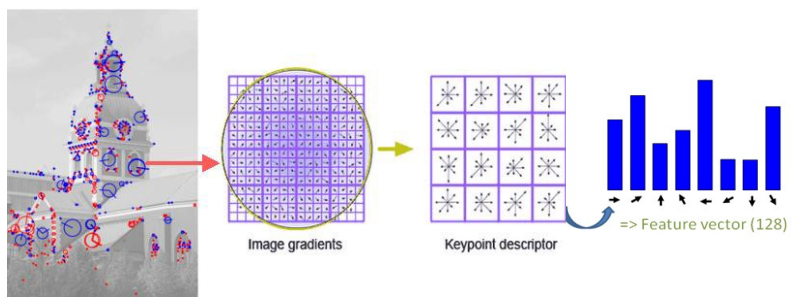 다시 한번 정리를 하자면,
다시 한번 정리를 하자면,
(STEP1)keypoint주변의 지역을 추출하여 16x16 pixel로 resize한다.
(STEP2)각각의 픽셀에 대하여 gradient를 계산하고, 픽셀을 16개(4x4 pixels squares)로 나눈다.
(STEP3)각 square은, 8개의 방향에 대하여 gradient direction histogram을 계산한다.
(STEP4)square은 총 16개가 있으므로, hisogram을 연결하면 16x8 크기의 feature vector을 얻는다.
SIFT Approach Done!
이제 SIFT에 대한 설명이 끝났다.
keypoint는 DoG 연산을 통해 결정되었고,
descriptor은 gradient histogram에 의해서 결정되었다.
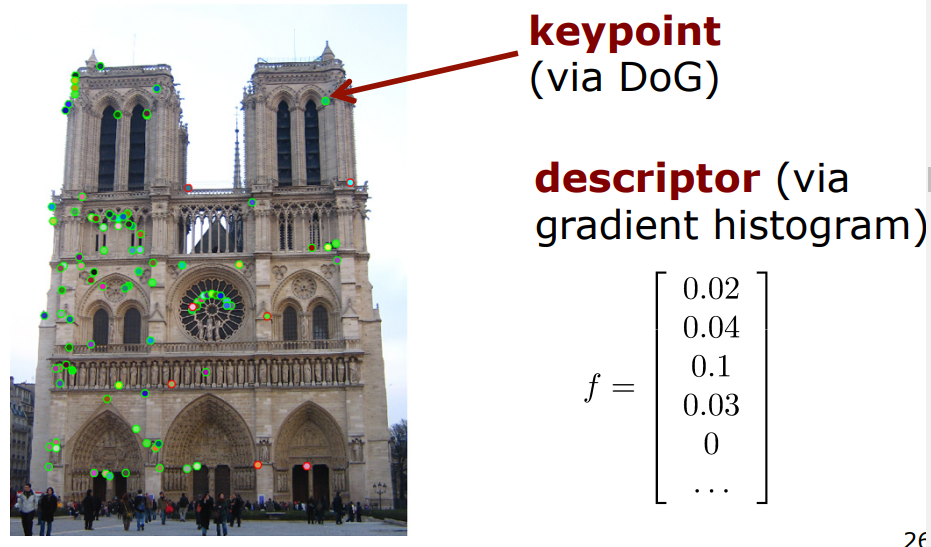
How to Match?
Based on Descriptor Difference
 어렵지 않다. 왼쪽 사진의 keypoint에 대하여 오른쪽 사진에서의 모든 keypoint와 값을 비교해본 다음에 가장 비슷한 keypoint를 찾아주면 그것이 바로 matching되는 것이다.
어렵지 않다. 왼쪽 사진의 keypoint에 대하여 오른쪽 사진에서의 모든 keypoint와 값을 비교해본 다음에 가장 비슷한 keypoint를 찾아주면 그것이 바로 matching되는 것이다.
초록색 라인과 같이 정확히 matching되는 곳도 있지만, 빨간색 라인과 같이 그렇지 않은 곳도 있다.
이렇게 잘 matching되지 않는 곳을 보완하기 위해 제안된 lowe's ratio test
Lowe's Ratio Test

Based on Ratio Test
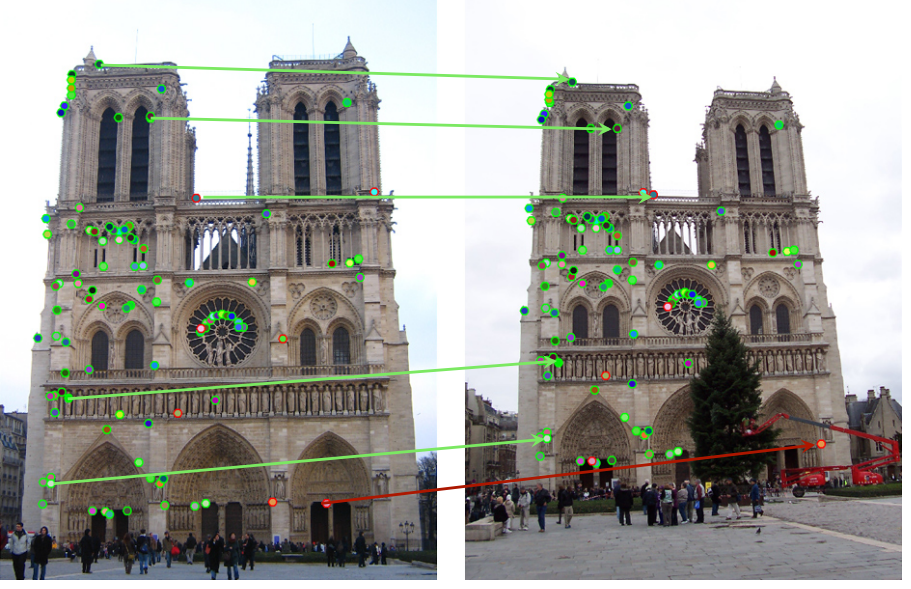 ratio test방법을 이용하면 이전보다 빨간색 라인이 줄어든 것을 확인할 수 있다.
ratio test방법을 이용하면 이전보다 빨간색 라인이 줄어든 것을 확인할 수 있다.
Outliers
Lowe's Ratio test에 의해서도 걸러지지 않는 outliers가 있다.
이 아이들은 추가적인 처리가 필요하다.
Binary Descriptors
or
'computing descriptor fast'
Why Binary Descriptors?
SIFT와 같은 Complex features도 잘 작동하고 표준처럼 사용이 되었다.
하지만 SIFT의 feature차원은 128이었고 이에 따라 연산량도 많고 descriptor을 찾는데 시간이 오래 걸렸다.
따라서
binary descriptors는 easy to compute and compare한 small binary strings를 생성하는 것을 목표로 하고 있다.
Key Ideas of Binary Descriptors
Fairly simple strategy
- keypoint 주변에 patch를 선정한다.
- 그 patch주변에 a set of pixel pairs를 선정한다.
- 각각의 pair에 대하여, intensitiy를 비교한다
- 모든 b를 하나의 bit string으로 연결한다.
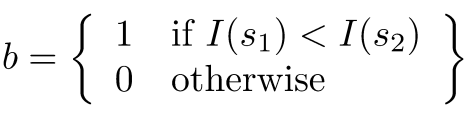
Example
 위(5 Cyrill)에서 설명한 내용이므로 생략
위(5 Cyrill)에서 설명한 내용이므로 생략
Key Advantages of Binary Descriptors
Compact descriptor
: pairs의 수는 length(단위 bit)를 나타냄
Fast to compute
: 단순히 intensity value만 비교하면 됨
Trivial and fast to compare
- Hamming distance란? 몇개의 문자를 바꿔야 두 문자열이 같아지는지
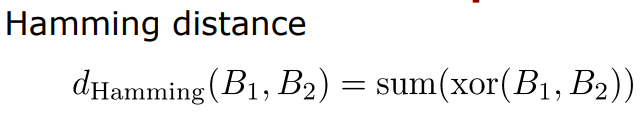

Different Binary Descriptors
Differ Mainly by the
Strategy of Selecting the Pairs
Important Remark - Pairs
image사이에 descriptor을 비교하기 위해서는 전제조건이 있다.
- same pairs 사용하기
- pairs가 tested된 것과 동일한 order 유지하기
different descriptors는 pair가 선택되는 방법을 결정한다.
BRIEF 알고리즘
BRIEF(Binary robust independent elementary features)
- 처음 제안된 binary image descriptor이었다.
- 2010년에 제안되었다.
256bit descriptor
: 256개의 different pair을 가졌다는 뜻- sampling strategy로써 5개의 different geometry 제공한다.
- Noise : noise를 다루기 위해서 operations는 smoothed image에서 수행됨

BRIEF Sampling Pairs

Performance
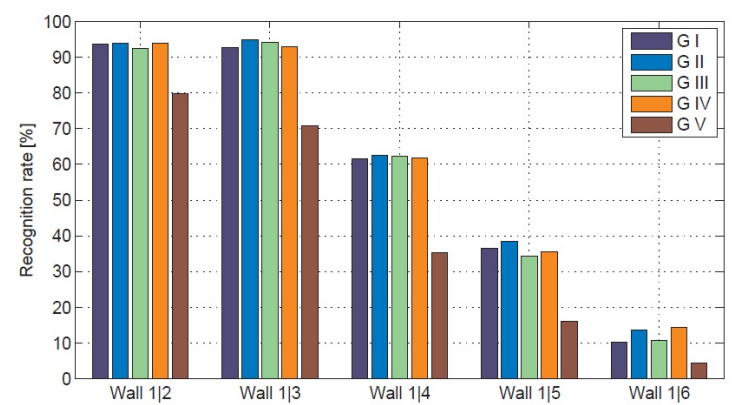 G I와 G IV는 모두 좋지만, G V는 덜 유용한 편이라는 것을 확인할 수 있다.
G I와 G IV는 모두 좋지만, G V는 덜 유용한 편이라는 것을 확인할 수 있다.
ORB 알고리즘
ORB(Oriented FAST Rotated BRIEF
BRIEF의 확장버전이다.
- rotation compensation을 추가하였다.
(즉 rotation에 강함) - 최적의 sampling pair을 학습한다.
ORB: Rotation Compensation
center of mass와main orientation of area/path을 측정한다.
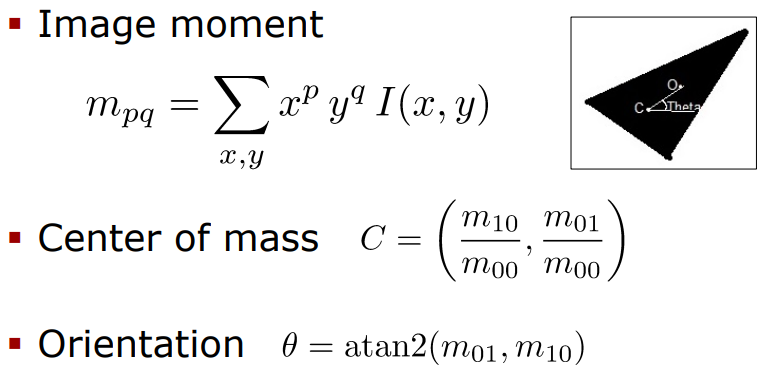

수식이 잘 이해가 안되는데 향후 추가하겠음 ㅠ.ㅠ
ORB: Learning Sampling Pairs
Pairs 전제조건
uncorrelated
: 각각의 pair이 descriptor에 새로운 정보를 줄 수 있도록high variance
: feature을 더욱 discriminative하게 만들기 위하여 (차별성을 갖게)
ORB는 training database를 사용하여
uncorrleated와high variance를 최적으로 만드는 256개의 pairs을 선택하는 과정이다
ORB vs SIFT

Summary


깔끔하게 잘 정리된 글이네요! 잘 보고 갑니다 :)